【深度】申省梅颜水成团队获国际非受限人脸识别竞赛IJB-A冠军,主要负责人熊霖技术分享

新智元专栏
作者:熊霖 赵健 徐炎
采访:闻菲
【新智元导读】开发出精确的和可扩展的无约束人脸识别算法,是生物识别和计算机视觉领域长期以来不断追求的目标。为了促进非受限条件下的人脸识别,美国国家技术标准局(NIST)主办了IJB-A竞赛。新加坡松下研究院与新加坡国立大学LV组去年两次夺得冠军,项目负责人新加坡松下研究院的研究工程师熊霖进行了专访,分享技术细节以及参赛经验。

开发出精确的和可扩展的无约束人脸识别算法,是生物识别和计算机视觉领域长期以来不断追求的目标。然而,实现这一点难度非常大,因为“无约束”需要人脸识别系统能在各种面部图像采集条件下(不同的光照、不同的传感器,以及是否进行了压缩),或者在被拍摄者各种主观条件下(面部的不同姿态、不同表情以及是否有遮挡),都能成功进行验证与识别。
去年3月,新加坡松下研究院与新加坡国立大学LV组参加了美国国家技术标准局(NIST)主办的非受限条件下人脸识别竞赛IJB-A,之后收到通知,获得了人脸验证(verification)与人脸辨认(identification)的双项冠军。
不过,他们在位居榜首三个月后被一家商业机构超越。但是,团队继续努力,找到差距,弥补不足,最终再次拿到目前已发表文章及arXiv技术报告中的最好性能。
在这样的背景下,新智元对项目负责人新加坡松下研究院的研究工程师熊霖进行了专访,分享技术细节以及参赛经验。
不过,你首先可能会问:IJB-A人脸识别竞赛是怎样的一个比赛?
早在2007年,Huang等人在一篇技术报告[1]提出并发布了后来非常著名的LFW人脸数据集,该数据集确实为后来推动无约束人脸识别算法起到了很大的作用。这个数据集包括在不受控或“自然环境下”采集的被拍摄者的静态图像。
自LFW数据集发布以来,许多类似的人脸数据集被相继发布,比如PubFig[2]和YouTube Faces(YTF)[3]。LFW和PubFig仅包含被拍摄者的静态图像,而YTF人脸数据则包含被拍摄者的一段视频。LFW和YTF等数据发布后,吸引了大量的学术机构和工业界团队去提升算法在这些数据集上的性能。
如今,尤其在LFW数据集上,已经有许多人脸识别算法的性能接近[4][5]甚至超越了人类的水平[6][7]。然而,无约束人脸识别算法的性能在很多实际的应用场景(比如监控系统),仍需亟待提高。究其原因,部分是因为所采用的评估协议没有充分考虑到无约束场景中图像实际采集的需求[8],但可能更多的原因,来自于数据集,比如LFW和YTF等都不完全是在无约束环境下采集的。
基于上面的这些原因,美国国家标准与技术研究院 (National Institute of Standards and Technology,NIST)于2015年发起了一项旨在推动无约束人脸检测与识别的挑战赛,并将相关的数据集IARPA Janus Benchmark A(IJB-A)发布在当年CVPR的论文中[9]。
不同于LFW和YTF,IJB-A具有如下新特点:
不仅包括被拍摄者的静态图像,也包括被拍摄者的视频片段。因为这个特点,论文引入了“模板”的概念,也即在无约束条件下采集的、所有感兴趣面部媒体的一个集合,这个媒体集合不仅包括被拍摄者的静态图像,也包括视频片段。
所有媒体都是在完全无约束环境下采集的。很多被拍摄者的面部姿态变化巨大,光照变化剧烈以及拥有不同的图像分辨率。
因为一个模板代表一个集合,所以最终的人脸验证与识别不是基于单个图像,而是基于集合对集合。此外,被拍摄者也来自世界不同国家、地区和种族,具有广泛的地域性。

正是因为IJB-A数据集拥有以上这三方面的新特点,使得该数据集非常符合实际的应用场景。当然,随之带来的也是巨大的挑战。在论文[9]中, 作者扩展了现有的评估协议到基于模板的场景,并针对人脸识别任务设计了开集(open-set)和闭集的评测协议(所谓开集评测协议,就是测试图像 [probe] 可能并不在注册集 [gallery] 中出现)。
这些新特点就成为新加坡松下研究院和新加坡国立大学LV组参加 NIST IJB-A 人脸挑战赛的主要动机。团队成员表示,希望他们提出的算法能够在完全无约束环境下更加鲁棒,性能得到显著提升。

新加坡松下研究院与新加坡国立大学LV组合作论文,非受限条件人脸识别目前已发表文章及arXiv技术报告中的最好性能。
从三处寻找突破口,提出冠军模型“深度迁移特征融合联合学习框架”
新智元:这次获胜的具体算法/模型是什么?相较于其他参赛解决方案的优势在哪里?
NIST 在2015年召开的CVPR上发布了IJB-A人脸验证与识别数据集,并同时拉开了围绕该数据集的人脸挑战赛的帷幕,我们于2016年10月正式决定参加该挑战赛并于2017年4月的NIST官方报告中,分别在验证1:1和识别1:N上都取得了第一的成绩,这不是仅仅依靠单个算法或模型所能做到的。我们的联合学习框架称之为迁移深度特征融合,具体可参见我们的arXiv预印版论文[1],我们的最新结果将在即将更新的arXiv预印版论文里展示。
不同于其他挑战赛所提供的数据集,例如COCO、ImageNet 以及MS-Celeb-1M等都提供了动辄几十万,几百万甚至上千万的数据,IJB-A数据则只包含来自500个对象的5396副静态图像和20412帧的视频数据,显然这样规模的数据是无法直接用来训练一个深层网络模型的。所以绝大部分的参赛方案都会使用外部数据并设计部署深层模型进行训练,然后在IJB-A数据上进行微调或在低维嵌入空间再训练另一个简单的模型以此来获得一个不错的成绩。简而言之,我们要想提出针对IJB-A人脸挑战赛的解决方案,那必然要从以下三处寻找突破口:外部数据、设计并部署深层模型和受迁移学习思想的启发是微调网络还是在低维嵌入空间再训练一个简单的模型。
具体来说,通过比较众多论文中IJB-A的结果,大多数方法都是基于深层网络的单一算法或单一模型,我们将这些算法总结为两类:一类是基于深层网络的单一算法或单一模型并辅以增加判别性信息的损失函数,好处是可以进行端到端的训练,但还需要在IJB-A原始数据上微调深层网络来获得一个不错的成绩;另一类也是基于深层网络的单一算法或模型但并非端到端的训练,前段基于深度模型,后段则通过将前段训练的深层网络作为特征提取器来提取IJB-A原始数据的低维特征,并对这些低维特征在低维嵌入空间进行测度学习来提升系统整体的判别性,最终获得一个不错的性能。这种分开的训练,好处是后段测度学习可以灵活选择,并且训练的代价要比微调深层网络小不少,但不能利用端到端训练的优势。在NIST的官方报告中,只有结果的比拼也未透露参赛者具体的算法和模型。
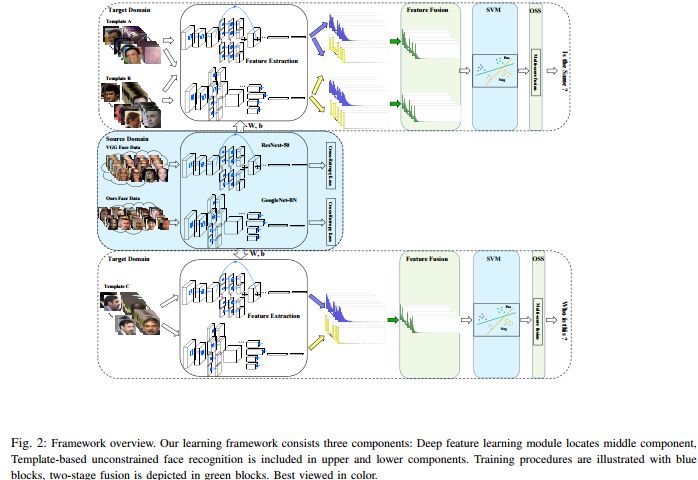
在外部数据方面,我们除了收集公共的人脸识别数据集外,也在网上爬取和采集各种符合项目要求的人脸数据,这其中涵盖了不同性别、不同年龄段、不同种族和不同地域的被拍摄对象。我们采集不同表情、不同光照条件和不同面部姿态的人脸数据,除了静态图像也包含摄像头捕捉的动态视频数据。
在设计并部署深层模型方面,纵观各种挑战赛,比如ImageNet, MS-Celeb-1M 以及 COCO等 ,要想冲击更高的性能,参赛的团队都会考虑多模型融合或集成的策略。我们吸取了这样的经验,但与通常采用的同构多模型融合策略(同一深层模型,同一训练数据)不同,我们的联合学习框架中则采用了异构多模型的融合策略。具体来说,我们知道,不同的深层模型由于设计思路的不同(卷积核的大小,是否考虑空间尺度信息,网络的深度和宽度的差异,各通道间的关系等等)其表达能力也大不同,但这些表达能力之间有没有互补性?我们早期通过初步的实验发现,确实存在这样的互补性,尤其网络结构差别越大,这种互补性也就越强。那么不同的训练数据呢?我们通过实验发现,即便采用相同的深层模型训练,在同一目标数据上,其低维的特征同样也有互补性。为了充分挖掘和利用这样的互补性,我们在联合学习框架中部署了两路具有巨大结构差异的深层网络并使用不同的大规模数据进行训练。
在利用迁移学习的思想时,我们同时采用了两种策略,即在低维嵌入空间再训练一个简单的测度学习模型和微调网络但不在局限于原始的IJB-A数据。对于第一种策略,我们通过模板自适应的思想设计了使用特定模板(IJB-A数据里引入了模板的概念,所谓模板是指一个集合,这个集合不仅包括被摄对象的静态图像也包括视频片段)来训练支撑矢量机以得到特定的测度信息,目的就是为了增强系统的判别性,这其中我们针对支撑矢量机也巧妙的设计了训练集和测试集,并且采用了两段融合的思想(特征融合与相似度分数融合),详细信息可以参见[1]。
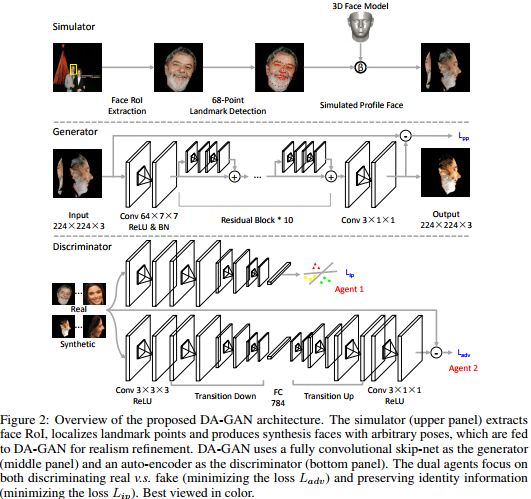
对于第二种策略,我们并不满足于原始的IJB-A数据,因为我们通过分析原始IJB-A数据发现,由于数据本身的面部多姿态性,面部姿态(比如偏向角)的分布是极不均衡的,尤其在大角度视角下具有长尾效应,如果直接使用IJB-A数据进行网络微调,势必最终的算法性能会是有偏的(受占主要正面或接近正面视角数据的影响),受苹果在CVPR 2017上获得最佳论文奖的工作[4]启发,我们提出了双代理的对抗生成网络用来生成逼真的多视角的面部姿态以获得均衡分布的IJB-A面部姿态数据。我们的方法可以看作是针对特定问题的数据增强方法并且可以推广到用于俯仰角的分析,详细信息可以参见[3]。
设计思路与关键:数据与基线深层网络模型的设计与部署
新智元:设计思路是怎样的?关键点在哪里?
正如我在前面分析的,我们的参赛方案着眼于三点:数据(包括外部数据和经过我们设计的增强方法而得到的增强版的IJB-A数据)、基线深层网络模型和受迁移学习思想启发的利用增强版IJB-A数据微调网络,以及在低维嵌入空间训练测度学习模型。这里的每一点都对我们最终能够在验证1:1和识别1:N上都取得第一都至关重要。这其中关键的还是数据与基线深层网络模型的设计与部署。
对于外部数据,我们不但使用了公开的人脸识别数据集,比如VGG 人脸数据集[5],其中包括2622 个对象且每个对象拥有约1000副静态图像,而且也使用了我们自己采集并整理的人脸数据。对所有人脸数据我们都进行了数据清理,人脸检测、人脸对齐以及标准化等预处理。其中我们自行设计的数据清理和标准化等预处理方法同样用到了早先我们参加的微软的百万名人识别竞赛MS-Celeb-1M,详细信息可以参见[2]。
对于增强版的IJB-A数据,最令人自豪的是,我们提出的双代理对抗生成网络是第一个针对人脸面部姿态(不同偏向角)做数据增强的模型,并且这种模型是可控的并能产生逼真的人脸面部姿态,尤其在完全无约束环境下我们的通过生成识别(recognition via generation)框架能够极大改善算法的性能。相关成果已经发表在NIPS 2017。

双代理对抗生成网络论文,已经在NIPS 2017发表,是第一个针对人脸面部姿态(不同偏向角)做数据增强的模型
对于基线深层网络模型,我们采用了异构多模型的融合策略。就是为了充分挖掘和利用不同深层网络结构和不同数据间的互补性,我们在联合学习框架中部署了两路具有巨大结构差异的深层网络并使用不同的大规模数据进行训练。当然,在训练深层网络模型时有效的数据增强方法也很重要,需要针对IJB-A数据的特点做出相应设计,比如光照的剧烈变化。
此外,我们的联合学习框架包含两阶段的融合,即特征融合与相似度分数融合。
无约束人脸识别难点与挑战:同一对象面部姿态变化剧烈
新智元:针对无约束人脸识别,当前主流的方法是什么(有哪些)?这些方法存在哪些问题或局限?存在这些局限的原因是什么?
针对完全无约束环境下的人脸识别,特别是在面部姿态变化剧烈的场景下的人脸识别,有研究论文[6]指出,当应用场景从正面-正面转换到正面-侧面或侧面-正面后,大多数人脸验证算法的性能会有超过10%的性能损失。这表明,面部姿态的剧烈变化仍然是今后人脸识别算法需要亟待解决的问题。这主要是因为同一对象的面部姿态的剧烈变化远超过不同对象间内在的面部外观的变化。
为了克服上面的挑战,根据最近提出的多种方法,我们可以归结为两大类。第一类是从各种面部姿态数据中直接学习姿态不变的判别性表示,我们提出的迁移深度特征融合的联合学习框架也属于这一类。具体方法包括我们前面提到的基于深层网络的单一算法或单一模型并辅以增加判别性信息的损失函数[5][7],以及基于多模态或多姿态的方法[8][9]。前者的局限在于仅考虑的单一的训练数据和单一的深层网络模型,并且网络的层数与现在主流的深层模型相比还不够深,比如[5]中使用了VGG16或VGG19 的网络结构,[7]中使用了类似GoogLeNet的22层结构。作者做出这样的选择,一是更高效的反向传播梯度信息流的网络结构还未被提出,对于更深的网络结构还无法有效探求,二是可能也由于当时硬件算力的制约。Triplet Loss 损失函数在这些方法中的得到使用,使得其被大家所熟知,但所带来的算法性能的提升有限,更多的性能提升还是来自于大规模的训练数据和有效的深层模型。后者的局限在于需要针对不同模态不同姿态去分别学习各自的深层网络模型,当模态数量和姿态数量增加,此外如果训练数据本身非常庞大,那训练多模态和多姿态所需的训练数据也将线性增加,这都将使得训练多个深层神经网络所带来的时间和计算成本非常巨大。在对抗生成网络诞生之前,生成特定姿态的人脸数据仍然有不少问题需要解决,比如使用3D模型,但生成的面部数据尤其是大姿态下会出现面部纹理细节丢失的现象,而我们提出的方法[3]可以有效解决这个问题。
第二类是通过人脸合成的方法将大姿态的人脸(比如大偏向角的侧脸)正面化(frontalization)为正脸,然后再用标准的人脸验证与识别算法去做最终的判断。最具代表性的方法是TP-GAN (Two-Pathway Generative Adversarial Network)[10],论文中展示的将侧脸生成正脸的可视化结果是让人震撼的,这足以显示出对抗生成网络具有强大的生命力。但经我们仿真复现该方法时发现,TP-GAN对Multi-PIE[12]数据有严重的过拟合问题,特别是想推广该方法到IJB-A数据时。这当然与该模型就是在Multi-PIE数据上训练有直接关系。更主要的原因是要想训练TP-GAN,针对数据的要求是比较严格的(需要有成对的正脸和侧脸数据,侧脸相应的标注点信息,如眼睛、鼻子和嘴巴的位置信息),能符合条件的数据很少,如果想将算法推广到IJB-A数据,那Multi-PIE几乎是唯一选择。
最近,L.Tran等人[11]提出的DR-GAN (Disentangled Representation learning-Generative Adversarial Network),为试图将前两类方法结合起来做了初步的尝试。但DR-GAN在Multi-PIE上的性能与TP-GAN相比还是有差距。虽然DR-GAN在IJB-A上表现出不错的性能,但与第一类方法相比还有很大的提升空间。
截止发稿前,我们通过改进基线深层网络模型、增加了新的外部训练数据以及增加了一些训练技巧,使得我们的算法在IJB-A数据上的性能又被刷到了历史新高,同时我们对人脸合成的方法同样也抱有浓厚的兴趣,也希望充分利用前两类方法的优势做出新的算法突破,相关的论文我们会陆续放出。
意外:验证数据出现在了训练数据里
新智元:比赛中有遇到意外吗?如何解决的?
任何科学实验都可能伴随着意外情况,近期我们在做相关实验时确实遇到了一个意外情况。为了进一步提高我们算法在IJB-A数据上的性能,使其有更大的突破,我们组织实习生在互联网上爬取相关的人脸数据,根据[5]的建议,我们主要选择抓取名人的图片以及大量公开的照片其中包括著名的运动员,影视歌演员以及政治家和国家领导人等,且希望尽可能覆盖不同性别、不同年龄段、不同种族、不同地域、不同表情、不同光照条件和不同面部姿态的人脸数据,以求满足IJB-A数据所具有的完全无约束条件。这样,我们就得到了一个人名列表和对应的静态图片集,为了保证每个对象至少包含100副变化多样的面部数据,我们做了适当筛选。
整个过程我们花费了前后1个多月的时间。然后我们也收集了已经公布的最新的人脸识别数据集,光将两者整合和做数据清洗等预处理也花费了近3个月时间。这包括使用多个人脸检测算法,多级的检测静态图片集以防止漏检,针对误检和检测出多张人脸的情况,我们使用在其他数据集上预训练好的超过百层的深层神经网络提取特征并计算相似性分数,再经过选择适当阈值进行筛选,最后我们得到了约1万个对象,近400万副图片的数据库。
我们使用这个数据集来训练经改进的基线深层网络模型,在IJB-A数据集上来验证我们的算法的性能,最后确实获得了意想不到的高性能。当看到我们的算法性能有了很大突破,正为此而欢呼雀跃时,突然我们研究人员发现忘记将新获得的数据集与IJB-A数据集做去重处理。
这个消息确实给了我们当头一棒,因为验证数据出现在了训练数据里,即便占比很少在机器学习方法论里也是不被允许的。为了追求严谨和公平的科研精神,我们根据人名列表重新设计了工具用于做IJB-A数据的去重处理。最后虽然性能上有轻微的降低,但我们最大程度上保证了严谨和公平。
参赛的硬件条件/配置如何?在过去一年,硬件或者说芯片的发展,对你们的工作是否有影响?
我们研究院对深度学习的项目都是大力支持的,这保证了我们可以使用到最新的GPU。我们在设计第一版算法时,训练两个都是百万数据的深层网络时(网络深度最多也就50层),使用的是英伟达麦斯威尔(Maxwell)核心的Tesla M40 GPU,每个网络的训练都使用4块卡,一个模型完整的训练最长需要12天。后面有了英伟达帕斯卡(Pascal)核心的GTX Titan X。我们加深了网络结构,同样每个网络的训练都使用4块卡,一个模型完整的训练最长甚至需要18天。而最近我们使用了更大的数据集,并使用超过一百层的深度网络结构,通过英伟达的DGX-1的Tesla P100 4块GPU,一个有效模型的训练可以缩短到8天。如果使用最新的Tesla V100的GPU,或许还可以继续降低模型训练的时间成本。随着GPU芯片的飞速发展,有了这样的算力,确实为我们进行调参提供了很大便利也提升了效率。当然,谷歌专门为人工智能和机器学习而研发的专用芯片TPU极大的推动了谷歌AI项目的进展,只是我们还无法获得谷歌的TPU来加速我们的项目开发。
为了更好的人脸识别,我们还需要更加符合实际场景的数据集
新智元:从LFW到IJB-A,为了更好的人脸识别,我们还需要怎样的数据集?
自2007年,Huang 等人在一篇技术报告[13]中就提出并发布了后来非常著名的LFW人脸数据集,该数据集确实为后来推动无约束人脸识别算法起到了很大的作用。 这个数据集包括在不受控或“自然环境下”采集的被拍摄者的静态图像。自LFW数据集发布以来,许多类似的人脸数据集被相继发布,如PubFig [14]和 YouTube Faces (YTF)[15]。不同于LFW 和 PubFig 仅包含被拍摄者的静态图像,YTF人脸数据则包含被拍摄者的一段视频。LFW和YTF等数据发布后,吸引了大量的学术机构和工业界去提升算法在这些数据集上的性能。然而,无约束人脸识别算法的性能在很多实际的应用场景比如监控系统中仍需亟待提高。
究其原因,可能更多的原因来自于数据集,比如LFW和YTF等都不完全是无约束环境下采集的。2014年,CASIA-WebFace [16]数据集发布,其中包括10575个对象和约50万的人脸图像,该数据尽管对象数过万,但是数据分布极不平衡,平均每个对象仅拥有46.8副图像。一年后,VGG 人脸数据[5]被发布,其中包括2622个对象和约2.6百万张人脸图像,平均每个对象平均拥有1000副人脸图像。但CASIA-WebFace 和 VGG 人脸数据中大姿态的面部数据占比非常少且光照变化不大。同年,美国国家标准与技术研究院 National Institute of Standards and Technology (NIST)发起了一项旨在推动无约束人脸检测与识别的挑战赛,并将相关的数据集IARPA Janus Benchmark A (IJB-A)发布在当年CVPR的论文中[19], IJB-A数据集中不仅包括被摄对象的静态图像而且同时也包括被摄者的视频片段。因为这个特点,论文种引入了模板的概念,这里所谓的模板是指在无约束条件下采集的所有感兴趣面部媒体的一个集合,这个媒体集合不仅包括被拍摄者的静态图像也包括视频片段,而且数据集中的所有媒体都是在完全无约束环境下采集的。很多被拍摄者的面部姿态变化巨大,光照变化剧烈以及拥有不同的图像分辨率,唯一的不足是该数据集的规模小。
2016年,更大的百万级人脸数据MegaFace[17]在当年的CVPR被发布,其中包括690572个对象和约4.7百万张人脸图像,将人脸数据的规模推向了一个高度。而美国华盛顿大学发布的这个数据集方针设定不同,其内容是几十位互联网名人的图片再加上普通人的1百万张图片作为干扰数据,相比人脸识别,更倾向于在大噪声情况下的人脸验证,并且数据的分布同样不平衡,平均每个对象只有7副图像,同一对象内人脸数据的变化小。同年,微软发布了MS-Celeb-1M[18]数据集,该数据集包含10万个对象和约1千万张人脸图像。这是迄今最大规模的人脸识别数据集,尽管规模很大但数据分布不平衡且大姿态的面部数据占比少且存在不少的噪声数据。
针对IJB-A 数据这种完全无约束环境下采集的数据,我们当然还需要更符合实际场景(比如包括更多的面部姿态变化、更多的光照变化甚至还有分辨率变化)的大规模人脸数据集。如果在没有合作,仅考虑自己采集数据的情况下,权衡成本,采集的对象数量不必非常大,万级别的就够用但应尽量保证所采集数据的分布尽量均衡,即每个对象平均要有至少100副以上的面部图像,目的是尽可能涵盖更多的面部变化信息,这其中也要考虑面部姿态分布的均衡性,以及要有更多的光照变化,甚至也尽可能包括不同分辨率的情况。同时也要考虑尽可能覆盖不同性别、不同年龄段、不同种族和不同地域的对象,数据集尽量干净,少量的噪声数据在深层模型下是可接受的。当然,未来还是需要工业界与学术界甚至和政府部门建立紧密的合作,有助于更高效的人脸数据采集与共享,共同推动完全无约束条件下的人脸验证与识别算法的性能。
如果要投入实用,作为入口的人脸检测将更加重要
新智元:获胜的技术投入实用还有多大距离?还需要解决哪些问题?
这个问题非常好,也非常具有实际意义。目前,我们研究院参加IJB-A 的人脸验证与识别挑战赛的目的,从技术角度上是希望我们提出的学习算法或框架能够在IJB-A数据上从验证到识别都能取得最高的精度,有些类似学术研究的性质,追求的是精度的极限。而从研究院的角度是希望通过在IJB-A的挑战上有更大的突破,来提升松下新加坡研究院人脸识别技术水平,进而为我们相应产品的更新换代打下坚实的技术基础,也同时为整个松下集团带来商业上的积极影响。并且IJB-A的人脸验证与识别挑战赛更关注的还是性能和精度,尽管该挑战赛目前已经落下帷幕,但是在该数据集上对性能和精度的追逐不会就此停歇。然而,仅仅在性能和精度上的精益求精并不能表示该技术能很快落地并投入实用。这其中还有很多需要优化和改进的空间,根据360公司首席科学家颜水成教授谈到的四元分析法,即算法、算力、数据和场景,IJB-A 的人脸验证与识别挑战赛的特点是数据和场景都是固定的,剩下的就是用尽量多的计算资源,设计和部署不同的算法,甚至使用更多网络和更多外部数据的异构多模型融合策略,其目的就是为了追求精度的极限,但这里面很多的成果是无法短时间投入实用的。不仅仅我们提出的模型,很多存在于论文上的算法同样也会面临这样的实际问题。要想投入实用,那就面临的是场景和算力的固定,在这样的情况下怎样去提升算法和收集新数据,这与场景和数据固定是完全不一样的。比如,我们会遇到很多实际的问题,模型太大那就需要进行压缩,算力有限有时甚至只有CPU的资源,你的算法还能否满足性能要求,满足不了那如何去平衡,这些都是需要逐个优化的。并且很多时候,在满足这个条件后又会有一些新的问题出来。
此外,IJB-A的人脸验证与识别挑战赛,核心目标是验证与识别,但要知道,人脸识别系统除了验证与识别,还有一个重要的模块那就是人脸检测。人脸检测从某种意义上将更重要,这解决的是验证与识别的入口问题,人脸检测同样会遇到不同面部姿态、不同光照、不同分辨率、不同大小甚至人脸部分被遮挡的挑战,这都是需要特定的技术比如多尺度感受野、注意力机制和通用目标检测的方法来协同来解决。甚至是否可以借助身体的信息帮助我们做面部检测,这都是很有意思的研究方向。我们松下研究院在人脸检测方向也有长期的技术积累,这次参赛所用的人脸检测算法部分就来自于自己的研究成果。
活体检测是下一个目标
新智元:团队接下来的工作和计划?哪些问题/特定任务/挑战赛让你们感兴趣?
在IJB-A的人脸验证与识别挑战赛落下帷幕之际,我们最终能将算法在IJB-A上的性能做到很大提升,这当然值得整个团队既振奋又高兴,但在喜悦之后我们并没有停下脚步。首先,我在前面提到,我们对人脸合成的方法同样也抱有浓厚的兴趣,也希望充分利用从各种面部姿态数据中直接学习姿态不变的判别性表示和通过人脸合成的方法将大姿态的人脸正面化这两类方法的优势,做出新的算法突破,相关的论文我们已经在准备,在合适的时机会陆续放出。其次,除了IJB-A的挑战赛,NIST还举办了其他的人脸识别挑战其具有不同的设计目标,有的在注重性能的同时还要兼顾效率,这对算法的设计提出的更高的要求,有的应用场景更特殊,甚至需要重新采集新的数据,而现有的模型和算法能否推广到新的应用场景,这些都需要慎重思考和周密计划。此外MegaFace的挑战赛吸引了很多学术界和工业界的机构参与,我们也会考虑将我们的算法在该数据集上做内部评估。
长远来看,我们将会考虑整个人脸识别系统的设计,即包括人脸检测、人脸对齐(有些学者认为不重要,但我们觉得还是要取决于实际应用场景,有的可能根本不需要68个标定点,但有的场景可能需要的更多)和人脸检测与识别的整套系统。最终目标是开发出人脸识别领域有突破的产品。此外,人脸识别最大的挑战就是对双胞胎的识别,然而这方面的数据并不太容易收集,我们对尝试解决这个挑战有非常大的兴趣。
最后,一个让整套人脸检测与识别系统变得真实可用的技术就是活体检测,比较成熟和落地的方法是需要被检测对象配合的交互式动作活体检测,如点头,眨眼甚至唇语加语音数据联合判断。而静默活体检测则包括基于全局和局部特征分析、基于特征点对齐、基于微纹理、基于微表情,还有通过增加红外摄像头捕获材质表面的反射特性。最近,由腾讯提出的光线活体检测又将静默活体检测技术向前推进了一步,采用了和苹果公司相同的3D结构光原理,不同的是三维重构的方式不同。我们研究院也很关注这方面的进展,但并无相关技术积累,这也正好为我们寻求外部合作提供了可能。
解决人脸识别,对于性能和精度的追求将永不停歇
新智元:最后问一个比较大的问题:距离解决人脸识别,我们还有多久?人脸识别子任务中,哪些可以算已经解决,接下来最有可能被解救的是什么?为此需要做什么?
距离解决人脸识别问题,我们还有多久? 这个问题确实不好回答,我们无法给出具体期限,因为每当解决一个子问题的时候,你会发现又有新的子问题产生,但我们相信这一天不会多遥远,或许很快就能来临。事实上,对于可控的约束条件下,在被摄者完全配合的场景中,如正面证件照、正面的大头照以及正面的网络摄像头采集的面部照片,对于1:1的人脸验证问题,很多基于深度学习的算法都已经可以获得接近99.9%甚至100%的性能,并且也都已经落地到成熟的产品中,如现今火热的手机刷脸解锁、机场或车站的刷脸进站以及刷脸支付,刷脸时代确确实实离我们越来越近。
对于无约束条件下,在被摄者不完全配合的场景中,接近正面的面部照片如LFW人脸数据,对于1:1的人脸验证问题,同样很多基于深度学习的算法都超过了人类97.53%的水平达到99.83%的新高度。这也证明在无约束条件下,对于接近正面的人脸验证问题也基本得到了解决。但是对于像IJB-A这样的人脸数据,在完全无约束条件下,被摄者完全不配合的场景中,很多被拍摄者的面部姿态变化巨大,光照变化剧烈以及由于采集装置的多样性导致具有不同的分辨率,面对这些挑战,很多基于深度学习的算法都还有进一步提升的空间。
这也是我前面说的,尽管该挑战赛目前已经落下帷幕,但是在该数据集上对性能和精度的追逐不会就此停歇,希望这将是下一个被拯救的子问题。我们希望对人工智能深度学习的研究,尤其人脸验证与识别这个子任务,工业界与学术界一起合作,共同推动人脸识别乃至整个人工智能领域到另一个新高度。
熊霖 Panasonic R&D Center Singapore 研究工程师,西安电子科技大学模式识别与智能系统专业博士,专注于无约束/大规模人脸识别,深度学习架构工程,迁移学习等方面的研究。https://github.com/bruinxiong,https://www.researchgate.net/profile/Lin_Xiong4/contributions
赵健 NUS LV Group 在读博士,专注于以人为中心的基于深度神经网络模型与算法的图像理解方面的研究,包括人脸识别、图像生成以及细粒度人物图像解析等。http://www.lv-nus.org/,https://zhaoj9014.github.io
徐炎 Panasonic R&D Center Singapore 研究工程师,西安电子科技大学电子与通信工程专业硕士,专注于人脸检测、配准及识别模块的研究与设计。
新加坡松下研究院成立于1990年,致力于多媒体和网络,机器学习,人工智能,计算机视觉及3D技术算法的软硬件的研发。在申省梅的带领下,我们在人工智能特别是人脸识别领域积累了多年的技术和大量的数据。
新加坡国立大学学习与视觉组(NUS LV Group)由颜水成教授创建,冯佳时教授领军,是目前各大学术机构在深度学习与计算机视觉领域的顶级团队之一。其人脸识别团队一直是LV组中不可或缺的顶梁柱并屡创佳绩。
[1] L. Xiong, J. Karlekar, J. Zhao et al. A Good Practice Towards Top Performance of Face Recognition: Transferred Deep Feature Fusion. arXiv preprint arXiv: 1704.00438, 2017.
[2] Y. Xu, Y. Cheng, J. Zhao Z. Wang, L. Xiong et al. High Performance Large Scale Face Recognition with Multi-Cognition Softmax and Feature Retrieval. ICCV 2017 Workshop.
[3] J. Zhao, L. Xiong et al. Dual-Agent GANs for Photorealistic and Identity Preserving Profile Face Synthesis. NIPS 2017.
[4] A. Shrivastava, et el. Learning from simulated and unsupervised images through adversarial training. CVPR 2017.
[5] O. M. Parkhi, et al. Deep Face Recognition. BMVC 2015.
[6] S. Sengupta, et al. Frontal to profile face verification in the wild. WACV 2016.
[7] F. Schroff, et al. FaceNet: A Unified Embedding for Face Recognition and Clustering. CVPR 2015.
[8] C. Ding, et al. Robust Face Recognition via Multimodal Deep Face Representation. IEEE TMM 2015
[9] I. Masi, et al. Pose-Aware Face Recognition in the Wild. CVPR 2016.
[10] R. Huang, et al. Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis. ICCV 2017.
[11] L. Tran, et al. Representation Learning by Rotating Your Faces. IEEE TPAMI 2017.
[12] R. Gross, et al. Multi-PIE. IVC 2010.
[13] G. B. Huang, et al. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. Technical Report 07-49, University of Massachusetts, Amherst, October 2007.
[14] N. Kumar, et al. Attribute and simile classifiers for face verification. In Computer Vision, 2009 IEEE 12th International Conference on, pages 365-372. IEEE, 2009.
[15] L. Wolf, et al. Face recognition in unconstrained videos with matched background similarity. In IEEE Computer Vision and Pattern Recognition, pages 529-534. IEEE, 2011.
[16] D. Yi, et al. Learning face representation from scratch. arXiv preprint arXiv:1411.7923, 2014.
[17] I. Kemelmacher-Shlizerman, et al. The megaface benchmark: 1 million faces for recognition at scale. CVPR 2016.
[18] Y. Guo, et al. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. ECCV 2016.
[19] B. F. Klare, et al. Pushing the frontiers of unconstrained face detection and recognition: IARPA Janus Benchmark A. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015.
加入社群
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号: aiera2015_1 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名-公司-职位;专业群审核较严,敬请谅解)。
此外,新智元AI技术+产业领域社群(智能汽车、机器学习、深度学习、神经网络等)正在面向正在从事相关领域的工程师及研究人员进行招募。
加入新智元技术社群,共享AI+开放平台



