经典回顾 | Collaborative Metric Learning
作者 | 老潇
链接 | https://zhuanlan.zhihu.com/p/27259610
编辑 | 机器学习与推荐算法
问题介绍
相关工作
Metric Learning
具体的来说就是通过学习一种数据与数据间的距离度量形式,将现有的数据映射到第三方空间,通过学习到的距离度量来衡量数据间的similarity,度量在数学上满足三角不等式,及两边的长度和不小于第三边,例如


CML
主要内容就是,给定所有数据和一个数据集
度量使用的欧几里得距离:
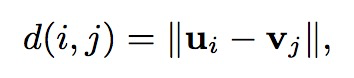
距离的损失函数:
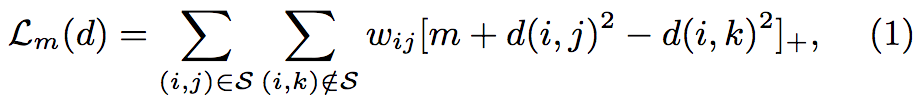
其中





下图表示了在梯度训练时的过程:
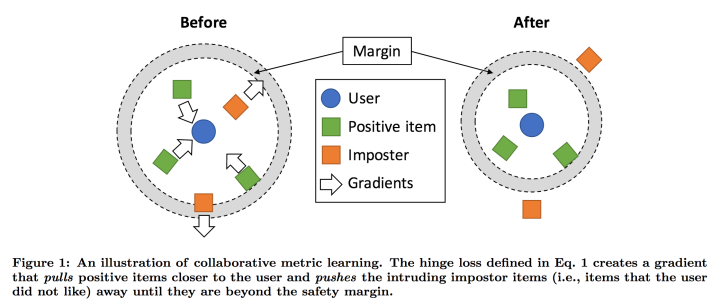
可以看到在loss的控制下,正相关的item与user的距离沿着梯度缩小,而不相关的则相反。其中impostor表示在安全边界内出现的负样本(与user不相关的item)
Approximated Ranking Loss
距离损失函数中的
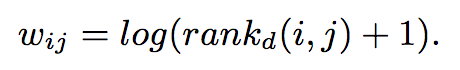
目的是来惩罚排名靠后的正相关item项其中。
其中
1、对于每个user-item对

2、让
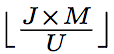
其中,
特征损失函数:
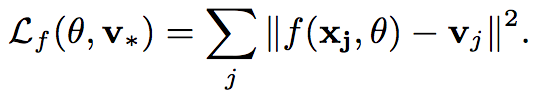
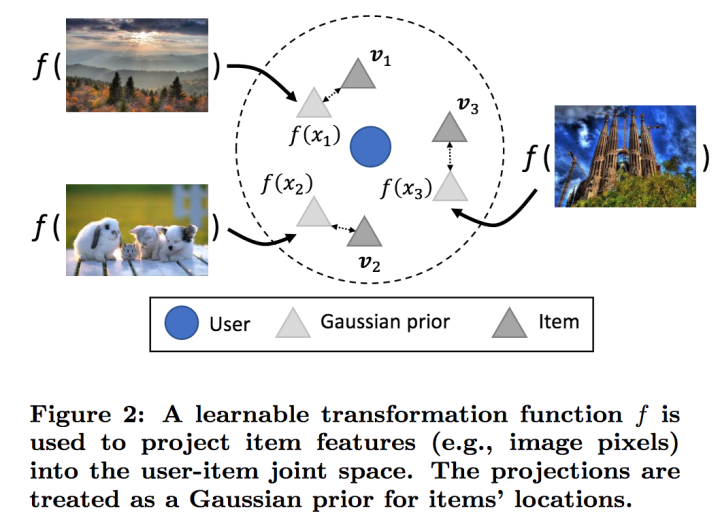
本文中借助的隐式反馈则为用户喜欢的item的feature,

正则项损失函数:
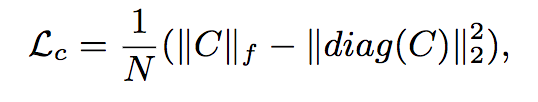
其中
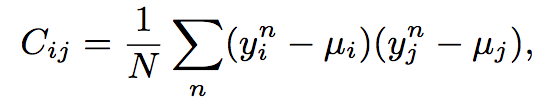
其中


训练过程:
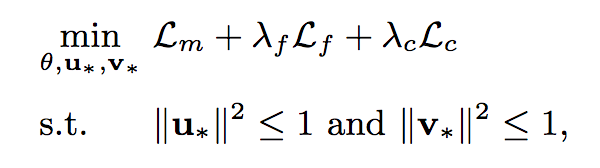
这是总的损失函数,下方的限制条件为保证空间可计算性。整个过程为Mini-Batch SGD训练,学习率采用AdaGrad控制。训练步骤如下:
1、从
2、对于每一对,抽样
3、对于每一对,保留使得距离损失函数最大的那个负样本item(k),并组成一个batchN。
4、计算梯度并更新参数。
5、重复此过程直到收敛。
实验结果
本文将CML与CF中的许多方法在各领域都进行了对比实验。
实验数据集包括:
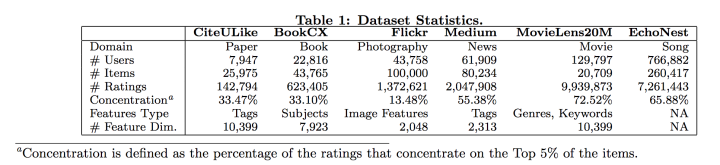
其中Concentration表示了评分集中在Top 5%物品的比例,可以反映该数据集对于热门物品的偏爱程度,与用户个性化物品偏爱程度。
实验结果:
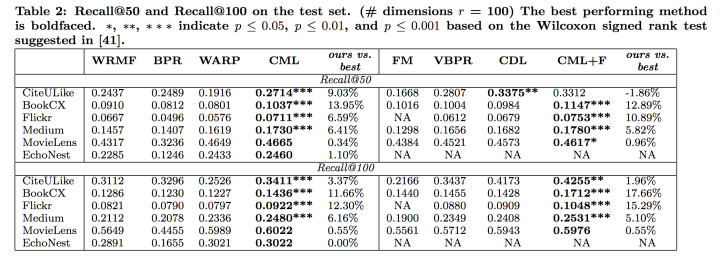
实验结果中可以看到,CML超过了几乎所有的方法,并且是在各领域都达到了state-of-the-art。
并且CML方法在对于注重用户兴趣的数据集上比较好,说明CML能很好的发现用户的preference。

选取了图像集来说明CML在只关注与user-item关系的情况下对item-item的similarity也产生了很好的效果。
总结
本文将metric learning与cf结合起来,通过充分利用metric learning学习距离的优势来挖掘user-item间的潜在关系,并且在各领域都能取得好成绩,文中也提到学习用户与物品距离成为了推荐在CF后的新方向。

🧐分享、点赞、在看,给个三连击呗!👇


