深度学习之卷积神经网络

-欢迎加入AI技术专家社群>>
纵观过去两年,“深度学习”领域已经呈现出巨大发展势头。在计算机视觉领域,深度学习已经有了较大进展,其中卷积神经网络是运用最早和最广泛的深度学习模型,所以今天就和大家分享下卷积神经网络的工作原理。
首先来聊聊什么是深度学习?
什么是深度学习
“Deep learning is a branch of machine learning based on a set of algorithms that attempt to model highlevel abstractions in data by using a deep graph with multiple processing layers,composed of multiple linear and non-linear transformations.”这是维基百科对深度学习的一段描述,从这段描述中可知深度学习是机器学习的一个分支,主要目的是让算法能够自主地从数据上学习到有用特征的。
深度学习与传统机器学习的区别
数据建模的一般通用流程主要包含四个主要步骤(对原始数据进行预加工,特征抽取、特征选取、特征建模),如下图所示:

传统机器学习当中的数据预处理、特征抽取、特征选择是需要人工来确定的,而深度学习这些步骤全部交由算法来自主选择。这是深度学习与传统机器学习的主要区别,也是深度学习的主要特性。

传统机器学习

深度学习
神经网络
在介绍卷积神经网络之前,我们先来了解下神经网络的结构和训练过程。
神经网络结构
神经网络,也称人工神经网络(Artificial Neural Networks),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。一个神经网络模型通常由一个输入层、一个或多个隐藏层以及一个输出层组成,如下图所示:

其中输入层用来接收数据输入,隐藏层和输出层的神经元(上图中圆圈表示)是其上一层的神经元的输出数据进行处理。单个神经元(不包括输入层)的工作原理如下图所示:

图中所标字母w代表浮点数,称为权重。进入神经元的每一个输入(X)都与一个权重w相联系,正是这些权重将决定神经网络的整体活跃性。你现在暂时可以设想所有这些权重都被设置到了-1和1之间的一个随机小数。因为权重可正可负,故能对与它关联的输入施加不同的影响,如果权重为正,就会有激发(excitory)作用,权重为负,则会有抑制(inhibitory)作用。
当输入信号X进入神经元时,它们的值x将与它们对应的权重w相乘加上一个偏置b,作为图中神经元的输入I,其中大圆的‘核’是一个函数,叫激励函数f,它把I经过f重新映射产生函数的输出也即神经元的输出O,其计算公式如下:

如何训练神经网络
当我们定义好一个神经网络的结构,神经元的激活函数f,已知训练样本数据以及训练样本的期望输出,如何训练这个神经网络呢?神经网络的训练目标是使其网络输出与我们的期望输出尽可能保持一致(如我们给神经网络输入一张猫的图片时,我们希望神经网络的输出能够告诉我们这只猫,而不是一只狗)。其训练过程如下图所示:
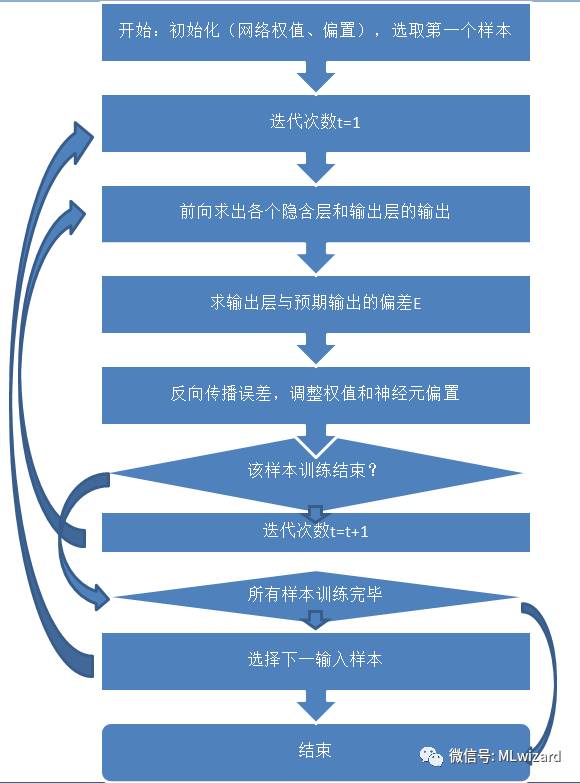
首先随机初始化连接权重和网络偏置(w,b),由训练样本输入经过隐藏层和输出层向后计算出网络的实际输出,然后通过误差计算公式计算出实际输出与期望输出之间的差距E。最后反向传播误差E,逐层调整连接权重和偏置的大小。
梯度下降
训练过程中如何反向传播误差E来调整权重和偏置呢?方法就是梯度下降(Gradient Descent),其思想是随机初始化一组参数(w,b),然后寻找一个能让误差函数E减小最多的参数组合(w,b),持续此过程直到误差函数到达一个最小值。
当所有训练样本训练结束后,最终可以得到一组训练参数(w,b)。最后,当我们用测试数据来输入到该神经网络模型中,就可以得到神经网络的预测输出了。
卷积神经网络
在介绍完神经网络的结构和训练流程后,我们来探讨下什么是卷积神经网络。卷积神经网络的基本结构如下图所示:
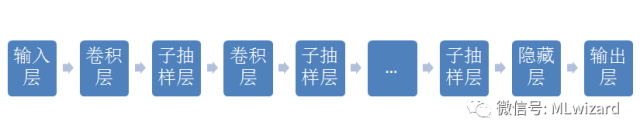
从上图可知,卷积神经网络与神经网络相比在结构上多了卷积层和子抽样层。然而我们不禁要问,为什么要加入这两种层次结构?
局部模式+参数共享
试想下,如果我们把一幅图片长宽分别为1000像素的图片输入到神经网络结构中,该神经网络第一层隐藏单元有100万个神经元,如下图所示
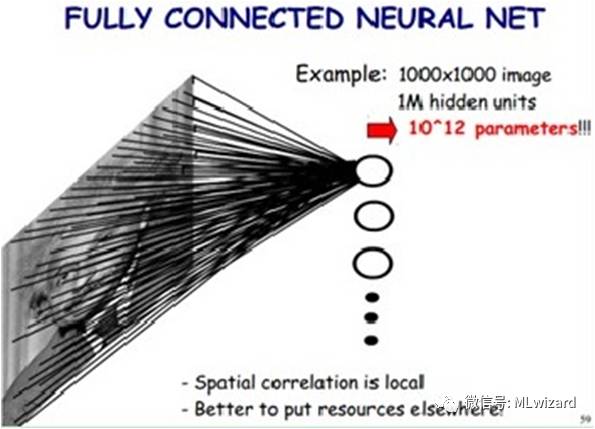
那么从输入层到第一层隐藏层的连接权重就多达1012个。如此庞大的参数导致 神经网络基本没办法训练。所以图像处理要想练成神经网络大法,必先减少参数加快速度。
一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。网络部分连通的思想,也是受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。所以卷积神经网络引入了图像处理中的局部模式。试想下如果我们使上面的神经网络中的每个神经元只与图像中的一个小区域(如10x10像素)相连,那么连接权重就从1012个减少到108个。但其实这样的话参数仍然过多,那么就启动第二级神器,即参数共享。如何再使每100个神经元的连接权重相等,即这100个神经元所提取的都是相同模式的特征,那么连接权重就从108个减少到10000个了。以上就是卷积神经网络的两大特点:局部模型和参数共享,这样就避免了神经网络的参数膨胀所带来的困扰。
卷积层
图像卷积操作是指对图像区域(下图中红色框区域)和卷积核矩阵进行逐个元素相乘再求和的操作。如下图所示:

一个3x3的卷积核在5x5的图像上做滑动步长为1的卷积操作,最终会得到一个3x3的卷积特征图。如下图所示:

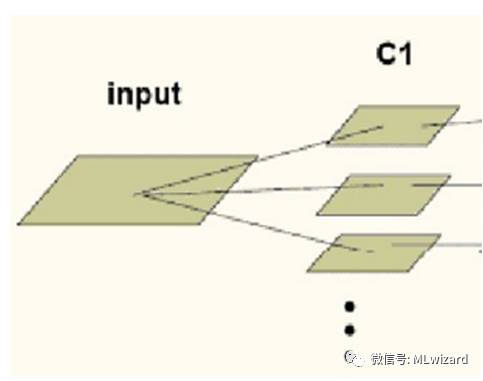
卷积神经网络的卷积层的对输入源图像input根据不同的卷积核进行卷积操作,再加上偏置,经过激活函数进行通重新映射,得到一系列的卷积特征图C1,如下所示:
子抽样层
由卷积操作过程可知,对一幅图像进行卷积操作所提取的特征图是有信息冗余的,故为了进一步对特征进行降维和抽象,在卷积神经网络中结构中引入了子抽样层。子抽样即用图像区域上的某个特定特征的平均值 (或最大值)来替代该区域,如下图所示:
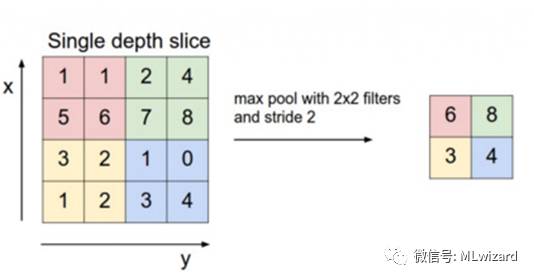
每个相同颜色的区域用其区域的最大值来表示,故一个4x4图像进行以2x2大小的区域进行子抽样,最后得到一个2x2大小的子抽样图。
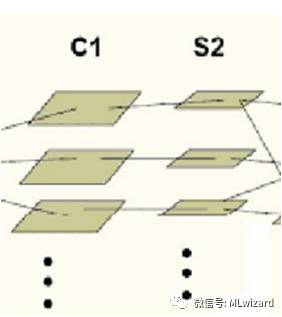
卷积神经网络的子抽样层的操作即对卷积层的输出特征图进行子抽样,最终会得到一系列的子抽样特征图,如下图所示:
卷积神经网络的训练过程
由卷积神经网络的结构可知,卷积神经网络是由一系列的卷积层和子抽样层连接上神经网络的隐藏层和输出层组成的。同样,当我们定义好一个卷积神经网络的结构,神经元的激活函数,已知训练样本数据以及训练样本的期望输出,如何训练该卷积神经网络呢?
同样地,我们初始化卷积层的卷积核、隐藏层输出层当中的连接权重、网络当中的偏置值。对结定的训练样本,从前向后计算各层输出,再根据误差计算函数得到期望输出与网络实际输出之间的误差E,然后误差反向逐层传播,调整输出层隐藏层当中的连接权重、网络当中的偏置值以及卷积层的卷积核大小,直至所有训练样本训练完毕。
输出层->隐藏层->子抽样层的误差反向传播过程
下图中红色框中的误差反向传播过程与神经网络训练过程中的误差传播过程一致。输出层->隐藏层->子抽样层误差反向传播,更新层间连接权重与偏置。

子抽样层->卷积层的误差反向传播过程
当前层为子抽样层,上一层为卷积层,局部误差如何从子抽样层反向传播回到卷积层?假设2x2下采样层的局部误差图如下图所示,
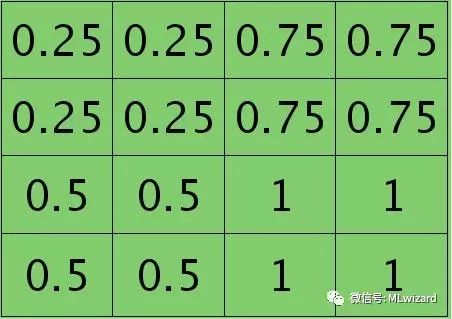
其中子抽样规则为平均采样方法,则卷积层的局部误差就是子抽样层各局部误差的平均值(若为极大值采样规则,前向计算时需要保存各个子抽样层的采样矩阵才能在误差后向传播时知道误差怎么反向传播),如下图所示:
卷积层->子抽样层的误差反向传播过程
当前层为卷积层,上一层为子抽样层,假设卷积层mapB是经过3*3的卷积核对子抽样层mapA进行卷积后得到的,如下图所示:
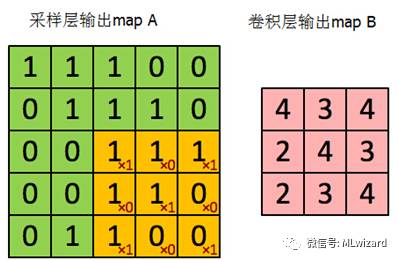
局部误差如何从卷积层反射传到子抽样层?假设卷积层的对应的局部误差图如下图所示:

卷积核矩阵为K=[k1,k2,k3,k4,k5,k6,k7,k8,k9]=[1,0,1,0,1,0,1,0,1],卷积层局部误差矩阵D=[d1,d2,d3,d4,d5,d6,d7,d8,d9]=[0.2,0.1,0.1,0.1,0.2, 0.2, 0.2, 0.1, 0.2],结合梯度下降的求导的链式法则,则k1的调整步骤如下:

其中ŋ为参数学习率,即每次参数沿梯度下降的方向调整的幅度大小。
至此,就全部介绍完了卷积神经网络的训练过程,根据误差反向传播调整卷积核、连接权重、偏置。当训练样本库训练结束后,一个卷积神经网络模型就训练完毕了。
总结
卷积神经网络在训练过程中可不断调整卷积核的大小,即深度学习当中自主选择特征的过程。由图像卷积操作可知,不同的卷积核对提取不同种类图像的特征,这也反过来验证了深度学习可以自主选择数据特征的特性。
其结构中卷积层和子抽样层是实现卷积神经网络特征提取功能的核心模块。卷积神经网络模型通过采用梯度下降法最小化损失函数对网络中的权重参数逐层反向调节,通过大量的输入和频繁的迭代训练提高网络的精度,从而得到输入到输出的映射。
在”深度学习搞一切视觉问题“的趋势下,手写数字的识别、图像分类、图像分割甚至连谷歌围棋AlphaGo都中都看到了卷积神经网络的身影,就让我们共同期待其在物体识别、语音识别、无人驾驶等AI领域的更cool的”变身“吧。




