TensorFlow 在行动:打造负责任的 AI

文 / Tulsee Doshi、Andrew Zaldivar
全球数十亿人正在使用以 AI 为核心的产品或服务,因此以 负责任 的方式部署 AI (Responsible AI) 显得尤为重要:保持信任并将用户利益放在首位。打造具有包容性、合乎道德准则且对社区负责任的产品一直是我们的首要任务,我们也将继续将之作为工作的重中之重。
两年前,Google 推出了 AI 原则,指引着我们应如何将 AI 应用于研究和产品。AI 原则阐明了我们在隐私性、尽责性、安全性、公平性和可解释性方面的 Responsible AI 目标。这些要素对于确保基于 AI 的产品为每位用户发挥正常效用至关重要。
AI 原则
https://www.blog.google/technology/ai/ai-principles/Responsible AI 目标
https://ai.google/responsibilities/responsible-ai-practices/
作为 Google Responsible AI 的产品主管和开发技术推广工程师,我们亲眼见证了开发者在使用 TensorFlow (tensorflow.google.cn) 等平台实现 Responsible AI 目标方面发挥的重要作用。TensorFlow 作为全球最受欢迎的 ML 框架之一,拥有数以百万计的下载量和全球开发者社区,不仅在 Google 内部得到了广泛应用,而且在全球也用于解决具有挑战性的现实问题。正因如此,我们在 TensorFlow 生态系统中不断扩展 Responsible AI 工具包,以便世界各地的开发者都可以更好地将这些原则整合到各自的 ML 开发工作流中。
在本文中,我们将概述使用 TensorFlow 构建 AI 应用的方法,以及构建过程中对 Responsible AI 原则的遵循。此处所指的工具集合仅仅是开始,我们希望它能不断发展,不单作为工具包,还是工具应用方面的经验集合和资源汇总库。
您可以在此获取我们下文讨论的所有工具:TensorFlow 的 Responsible AI 工具集合
(http://tensorflow.google.cn/resources/responsible-ai)。
用TensorFlow构建 Responsible AI 指南
您可以查看工作流和工具的 完整介绍 (tensorflow.google.cn/resources/responsible-ai)。
为简化讨论,我们将工作流分为 5 个关键步骤:
第 1 步:定义问题
第 2 步:收集和准备数据
第 3 步:构建和训练模型
第 4 步:评估模型
第 5 步:部署和监控
在实践过程中,我们希望开发者能够经常在这些步骤之间切换。例如,开发者可以训练模型、识别不良性能,然后返回收集和准备其他数据来解决这些问题。模型在部署后可能进行多次迭代和改进,而这些步骤也将重复进行。
无论完成这些步骤的时间和顺序如何,在每个阶段都存在关键的 Responsible AI 问题及可用的相关工具来帮助开发者调试和识别关键洞察。随着我们更详细地介绍每个步骤,您将看到我们列出的数个问题,以及我们推荐的可用于解答这些问题的一系列工具和资源。当然,我们仅列出了部分问题,但它们可以作为激发人们思考的范例。
请注意,这些工具和资源中有许多都能应用于整个工作流,而不是仅可在我们突出介绍的步骤中使用。例如,Fairness Indicators 和 ML 元数据可以用作独立工具,分别评估和监控模型中的意外偏差。这些工具也集成到了 TensorFlow Extended 中,这样一来,开发者不仅有了将模型投入生产的途径,还能借助统一的平台,更加流畅地完成工作流迭代。
第 1 步:定义问题
问题
我要构建什么?目标是什么?
我为谁构建?
他们将怎样使用我构建的产品?如果失败,用户会承受哪些后果?
所有的开发流程都是从定义问题开始。AI 何时才能成为真正有价值的解决方案,要解决什么问题?在定义 AI 需求的过程中,请务必牢记您可能要为不同的用户构建产品,而且这些用户在产品上可能获得不同体验。
例如,如 Explorable 中所述,如果您正在构建用于筛查个体是否患有某种疾病的医学模型,此模型针对成人和儿童的学习和使用方式可能有所不同。模型失败时,可能会对医生和用户都产生负面影响。
PAIR 指导手册
《人与 AI (PAIR) 指导手册》(The People + AI Research (PAIR) Guidebook) 以设计以人为本的 AI 为重点,概述了开发产品时需要确定的关键问题,是您构建产品时的得力助手。指导手册汇总了来自 40 个产品团队 Google 员工的真知灼见。我们建议您在定义问题时通读所有关键问题,并使用其中提供的实用工作表!随着开发的不断深入,再回顾这些问题。
Explorables 是一组轻量级交互式工具,介绍了一些重要的 Responsible AI 概念。
第 2 步:收集和准备数据
问题
我的数据集代表了哪些用户?是否能代表我的所有潜在用户?
如何对我的数据集进行采样、收集和标记?
我该如何保护用户的隐私?
我的数据集可能会暗含哪些潜在偏差?
定义要使用 AI 解决的问题后,流程的关键部分在于收集已充分考虑社会和文化因素的数据,以解决之前定义的那些问题。例如,开发者如果想要基于明确的某种方言来训练语音检测模型,他们可能会考虑使用已处理过的资源作为数据源(如下例中已针对语料资源稀缺而处理过的数据集)。
数据集是 ML 模型的核心和灵魂,应将其本身视为产品。而我们的目标是为您提供工具,帮助您了解数据集所代表的对象,以及在数据收集过程中可能存在哪些差距。
TensorFlow 数据验证
您可以利用 TensorFlow Data Validation (TFDV) 分析数据集并在不同特征之间对数据进行切片,以了解数据的分布方式,以及可能存在差距或缺陷的位置。TFDV 结合了 TFX 和 Facets Overview 等工具,可帮助您快速了解数据集中各个特征的值的分布情况。这样,您不必创建单独的代码库即可监控训练和生产流水线是否偏斜。

哥伦比亚西班牙语使用者数据集的数据卡示例
在适当情况下,TFDV 生成的分析可用于为数据集创建数据卡 (Data Cards)。数据卡可视为数据集的 透明度报告,能够提供对收集、处理和使用实践的深入分析。例如,我们的一项研究驱动型工程计划专注于针对某些区域创建数据集,这些区域既缺乏构建自然语言处理应用的资源,又具有迅速增长的互联网渗透率。为帮助希望在这些地区研究语音技术的其他研究人员,负责此计划的团队首先为不同的西班牙语国家/地区创建了数据卡,其中包括上方显示的哥伦比亚西班牙语使用者数据集,提供了研究人员在使用其数据集时的预期效果模板。
有关数据卡的详细信息、如何创建数据卡的框架,以及有关如何将数据卡的各部分集成到所使用的流程或工具中的指南,将于近期发布。
第 3 步:构建和训练模型
问题
在训练模型时我该如何保护隐私或考量公平性?
我应该使用哪些技术?
训练 TensorFlow 模型可能是开发过程中最复杂的环节之一。如何在不影响用户隐私的情况下为 每位用户 表现最佳性能的方式进行训练?我们开发了一套工具,在简化此工作流程的各方面的,并在你设置 TensorFlow 流水线时启用最佳实践的:
TensorFlow Federated
联邦学习是机器学习的一种新方法,利用此方法,许多设备或客户端能够共同训练机器学习模型,同时将其数据保存在本地。数据保存在本地有利于保护隐私,并有助于防止因集中数据收集而产生的风险(如被窃取或大规模滥用)。开发者可以试着使用 TensorFlow Federated 库将联邦学习应用于自己的模型。
[新] 我们近期发布了一项教程,指导开发者使用 TensorFlow Federated 在 Kubernetes 集群上运行高性能模拟。
您还可以通过 差异化隐私 维护训练中的隐私性,此方法可在训练中增加噪音以隐藏数据集中的单个示例。TensorFlow Privacy 提供了一组优化器,使您从一开始就可以使用差异化隐私进行训练。
TensorFlow 约束优化和 TensorFlow Lattice
除了在训练模型时建立隐私注意事项之外,您还可能需要配置一组指标,并在训练机器学习问题时使用这些指标以获得理想结果。例如,除非您考虑将所有相关指标都组合在一起,否则可能很难在不同群组之间实现公平体验(更多请参考 TFCO 和 TensorFlow Lattice)。
Lattice 库提供了多种不同的研究型方法,支持基于约束的方法,可帮助您解决如公平性等更广泛的社会问题。下个季度,我们希望开发并提供更多 Responsible AI 训练方法,发布我们已在自身产品中使用的基础架构,努力解决公平性问题。我们很高兴继续构建工具套件和进行案例研究,以展示不同方法与不同用例之间的适用性是怎样的,并为每种用例提供机会。
第 4 步:评估模型
问题
我的模型是否能很好的保护隐私?
我的模型在不同用户群中的表现如何?
有哪些失败的案例,为什么会发生这样的情况?
对模型进行初始训练后,迭代过程随即开始。通常,模型的首个版本并无法达到开发者预期,因此通过易用的工具来识别发生问题的位置很重要。找到理解隐私和公平性问题的恰当指标和方法可能尤其具有挑战性。我们的目标是提供工具以支持相关工作,让开发者能够结合传统的评估和迭代步骤来评估隐私和公平性。
[新] 隐私测试库
上周,我们宣布推出 TensorFlow Privacy 的一个组件,即 TensorFlow Privacy 隐私测试库。这是我们希望发布的多项测试中的第一项,旨在支持开发者审视各自模型并识别其中存储单个数据点信息的实例,并且可能确保开发者展开进一步的分析,包括考虑训练具有差异化隐私的模型。
评估工具套件:Fairness Indicators、TensorFlow Model Analysis、TensorBoard 和 What-If Tool,您还可以研究 TensorFlow 评估工具套件,以了解模型中的公平性问题并调试特定示例。
利用 Fairness Indicators,在超大型数据集上评估分类和回归模型的通用公平性指标。工具随附一系列案例研究,可帮助开发者轻松理解与确定适合其需求的指标,并使用 TensorFlow 模型设置 Fairness Indicators。通过广受欢迎的 TensorBoard(插件)平台可实现可视化效果,而建模人员也已使用此平台跟踪各自的训练指标。最近,我们发布了一项案例研究,重点介绍了如何将 Fairness Indicators 与 Pandas 结合使用,以实现对更多数据集和数据类型的评估。
Fairness Indicators 构建于 TensorFlow Model Analysis (TFMA) 之上,包含了更全面的指标合集,可用于评估各种关注点的通用指标。
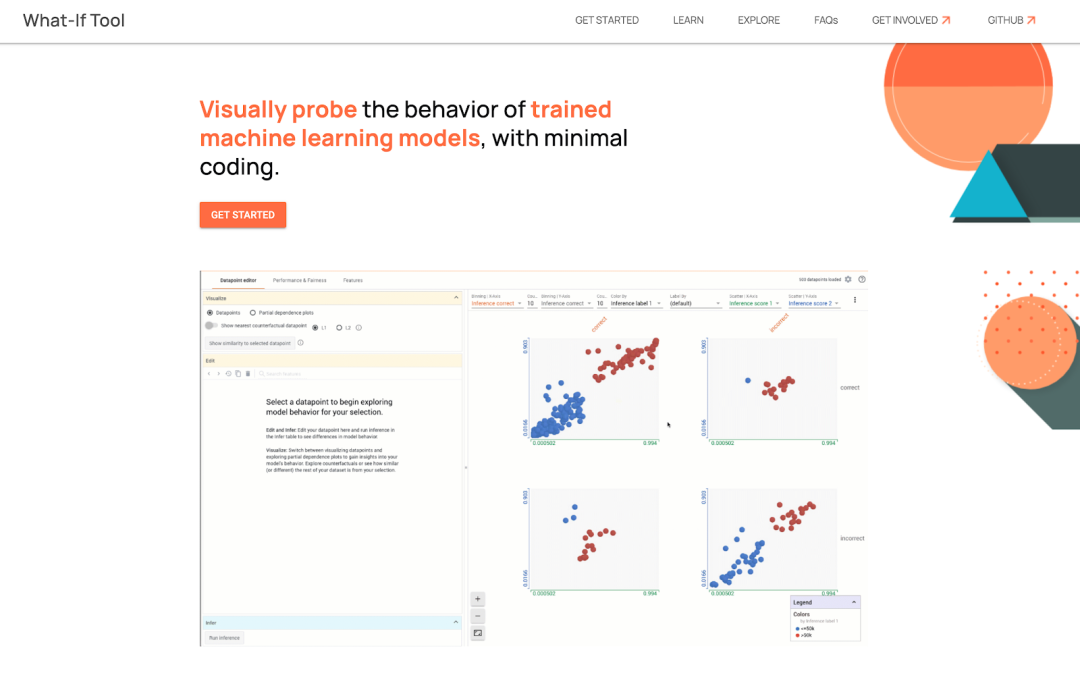
What-If Tool 可测试数据点上的假设情况
一旦识别了性能不佳的切片后,或者您希望更审慎地理解和解释错误,则可使用 What-If Tool (WIT) 来进一步评估模型,该工具可以直接通过 Fairness Indicators 和 TFMA 使用。您可以借助 What-if Tool 检查数据点层级的模型预测,从而加深对特定数据切片的分析。此工具提供了多种功能,从在数据点上测试假设情况(例如“如果该数据点来自不同类别会怎样?”)到可视化不同数据特征对模型预测的重要性等。
除了在 Fairness Indicators 中集成之外,What-If Tool 还可以作为独立工具用于其他用户流程,并可通过 TensorBoard 访问,或在 Colab、Jupyter 和 Cloud AI Platform Notebook 上使用。
通过 TensorBoard 访问
https://pair-code.github.io/what-if-tool/get-started/#tensorboard
[新] 现在,为帮助 WIT 用户更快入门,我们正发布一系列新的培训教程和演示,帮助用户更好地使用此工具的众多功能,包括善用反设事实解释模型行为和探索功能并识别常见偏差等功能。
可解释 AI Google Cloud 用户可以通过可解释 AI 进一步强化 WIT 功能,此工具包构建于 WIT 之上,引入了其他可解释性功能,包括可识别对模型性能影响最大的功能的积分梯度法。
您可查看 tensorflow.google.cn 上的教程,您可能对此类教程也感兴趣:如何处理不平衡数据集,并使用积分梯度法解释图像分类器(与上文所述类似)。
tensorflow.google.cn 上的教程
https://tensorflow.google.cn/tutorials

上面教程将解释此图片为何被归类为消防艇(很可能是因为喷水)
第 5 步:部署和监控
问题
随着时间推移,我的模型的表现如何?它在不同场景下的表现如何?我如何继续跟踪和改善其进度?
ML 元数据
模型卡片
部署模型时,您还可以在其部署中附上模型卡片,即一种按某种格式组织的文档,您可以利用此卡片传达模型的值及其存在的限制。通过模型卡片,开发者、政策制定者和用户能够了解已训练模型的各个方面,为更广泛的开发者生态系统做出贡献,提高清晰度和可解释性,从而尽量避免 ML 被用于不恰当情境。基于 2019 年初 Google 研究人员发表的学术论文中提出的框架,模型卡片已与 Google Cloud Vision API 模型一并发布,包括模型对象和面部检测 API,以及一些开源模型。
现在您可以从此论文和现有示例中获取灵感,开发自己的模型卡片。我们计划在未来两月内将 ML 元数据和模型卡框架相结合,为开发者提供更为自动化的方式来创建此类重要工件。我们会将模型卡片工具包添加到 Responsible AI 工具包集合中,敬请期待。
想要试用这些资源?前往 https://tensorflow.google.cn/resources/responsible-ai 获取所有资源。
写在后面
值得注意的是,虽然 ML 工作流中的 Responsible AI 是一项关键因素,但遵循 AI 伦理构建产品需要综合考量技术、产品、政策、流程和文化等多种因素。这些问题关系到各方各面,从根本上讲是一项 社会技术问题。
例如,公平性问题通常可以追溯到世界基础体系中存在的偏见历史。因此,积极履行 AI 责任不仅要评估和调整建模,还需对策略和设计进行更改以提供透明、严格的审查流程,以及可提供多种观点的多元化决策者。
所以,我们在本文中介绍的多种工具和资源都建立在 Google 开展的社会技术研究工作之上。如果没有强大的研究基础,这些 ML 和 AI 模型可能会被错误地集成到复杂的决策系统之中,无法产生积极的社会效益。我们以负责任的方式构建 AI 时所采取的措施包括:利用跨文化视角,在展开工作时立足于以人为本的设计,将透明性扩展到所有领域(无论专业知识如何),并将我们的学习成果付诸实践。
我们了解 Responsible AI 是一个不断发展的关键领域,这就是为什么当看到 TensorFlow 社区积极思考我们所讨论的问题,特别是采取行动时,我们感到充满希望。在最新的 Dev Post 挑战赛中,我们希望社区使用 TensorFlow 打造出结合了 AI 原则的出色产品。获奖作品探索了公平性、隐私性和可解释性等领域,并向我们展示了 Responsible AI 工具集成到 TensorFlow 生态系统库的必要性。我们将继续专注于这一领域,确保这些工具易于使用。
在您开始下一个 TensorFlow 项目时,我们期待您使用上述工具,并通过 tf-responsible-ai@google.com 向我们提供反馈。请与我们分享您的经验,我们也会继续分享实践成果,如此我们便可携手打造出真正造福所有人的产品。
如果您想详细了解 本文提及 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
Explorable / 先前讨论
https://pair.withgoogle.com/explorables/measuring-fairness/
PAIR 指导手册
https://pair.withgoogle.com/guidebook/
AI Explorables
https://pair.withgoogle.com/explorables/TensorFlow 数据验证
https://tensorflow.google.cn/tfx/guide/tfdvFacets Overview
https://pair-code.github.io/facets/研究驱动型工程计划
https://github.com/google/language-resources
教程
https://github.com/tensorflow/federated/blob/master/docs/tutorials/high_performance_simulation_with_kubernetes.ipynb
TensorFlow Model Analysis
https://tensorflow.google.cn/tfx/model_analysis/install一系列案例研究
https://tensorflow.google.cn/tfx/fairness_indicatorsTensorBoard 插件
https://github.com/tensorflow/tensorboard/blob/master/docs/fairness-indicators.md案例研究
https://colab.research.google.com/github/tensorflow/fairness-indicators/blob/master/fairness_indicators/documentation/examples/Fairness_Indicators_Pandas_Case_Study.ipynbWhat-If Tool
https://pair-code.github.io/what-if-tool/通过 Fairness Indicators 和 TFMA 使用
https://colab.sandbox.google.com/github/tensorflow/fairness-indicators/blob/master/fairness_indicators/documentation/examples/Fairness_Indicators_Example_Colab.ipynb#scrollTo=jtDpTBPeRw2d通过 TensorBoard 访问
https://pair-code.github.io/what-if-tool/get-started/#tensorboardColab/Jupyter
https://pair-code.github.io/what-if-tool/get-started/#notebooksCloud AI Platform Notebook
https://pair-code.github.io/what-if-tool/get-started/#cloud-ai一系列新的培训教程
https://pair-code.github.io/what-if-tool/learn善用反设事实解释模型行为
https://pair-code.github.io/what-if-tool/learn/tutorials/counterfactual探索功能并识别常见偏差
https://pair-code.github.io/what-if-tool/learn/tutorials/features-overview-bias/可解释 AI
https://cloud.google.com/explainable-ai不平衡数据集
https://tensorflow.google.cn/tutorials/structured_data/imbalanced_data积分梯度法
https://storage.googleapis.com/cloud-ai-whitepapers/AI%20Explainability%20Whitepaper.pdf模型卡片/Google 研究人员发表的学术论文
https://arxiv.org/abs/1810.03993Google Cloud Vision API 模型
https://modelcards.withgoogle.com/model-reports现有示例
https://modelcards.withgoogle.com/aboutDev Post 挑战赛
https://responsible-ai.devpost.com/获奖作品
https://responsible-ai.devpost.com/submissions


了解更多请点击 “阅读原文” 访问资源合集。

分享 💬 点赞 👍 在看 ❤️
以“三连”行动支持优质内容!




