RetinaNet在航空图像行人检测中的应用

一次RetinaNet实践
作者 | Camel
编辑 | Pita
航空图像中的目标检测是一个具有挑战性且有趣的问题。随着无人机成本的降低,航空影像数据量的激增,拥有能够从航空数据中提取有价值的信息的模型将非常有用。
RetinaNet是最著名的单级目标检测器,在本文中,我将在斯坦福无人机数据集的行人和骑自行车者的航空图像上测试RetinaNet。
我们来看下面的示例图像。
这是一个具有挑战性的问题,因为大多数目标只有几个像素宽,某些目标被遮挡,阴影下的目标更难检测。
Retina Net
Retina Net 是一个单级目标检测器,使用特征金字塔网络 (FPN) 和焦点损失函数(Focal loss)进行训练。
特征金字塔网络是本文引入的多尺度目标检测结构,它通过自上而下的路径和横向连接将低分辨率、语义强大的特征与高分辨率、语义薄弱的特征相结合。这样做的结果是,它在网络中的多个层级上生成不同尺度的特征图,这有助于分类和回归网络。
焦点损失旨在解决单阶段目标检测问题,因为图像中可能存在大量的背景类和几个前景类,这会导致训练效率低下。大多数位置都是容易产生任何有用信号的负片,大量这些负样本使训练不堪重负,降低了模型性能。焦力损失基于如下所示的交叉熵损耗,通过调整γ参数,可以从分类良好的样本中减少损失贡献。
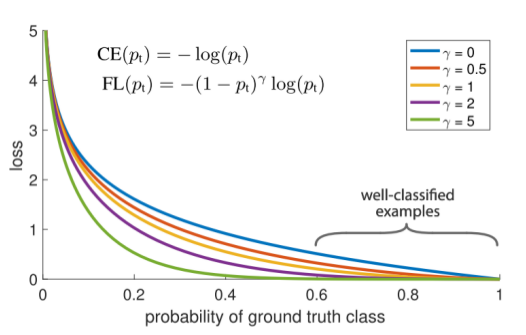
焦点损失解释
在本文中,我将讨论如何在Keras上训练Retina Net模型。关于RetinaNet背后的理论,请参考[1]。我的代码可以在Github上下载[2]。训练后的模型在航空目标检测方面的效果可以参考如下动图:

Stanford Drone 数据集
斯坦福无人机(Stanford Drone)数据是在斯坦福校园上空通过无人机收集的航拍图像数据集。这个数据集是目标检测和跟踪问题的理想选择,它包含约了60个航拍视频。每个视频,有6类标注 :"行人"、"自行车"、"滑板"、"购物车"、"汽车"和"巴士"。数据集非常丰富,不过行人和骑行者这2类大约占所有标注的85%-95%。
训练RetinaNet
为了训练RetinaNet,我在Keras使用了keras-retinanet的代码实现[3],它的帮助文档非常好,运行起来没有任何错误。
从大量斯坦福德无人机数据集中选择图像示例。我采用了大约 2200 张训练图像,包含30000 多个标注信息,并保存了大约 1000 张图像进行验证。我已经把我的图像数据集放在google drive[4] 上。
以 RetinaNet 所需的格式生成标注。RetinaNet 要求所有标注都采用该格式。
path/to/image.jpg,x1,y1,x2,y2,class_name
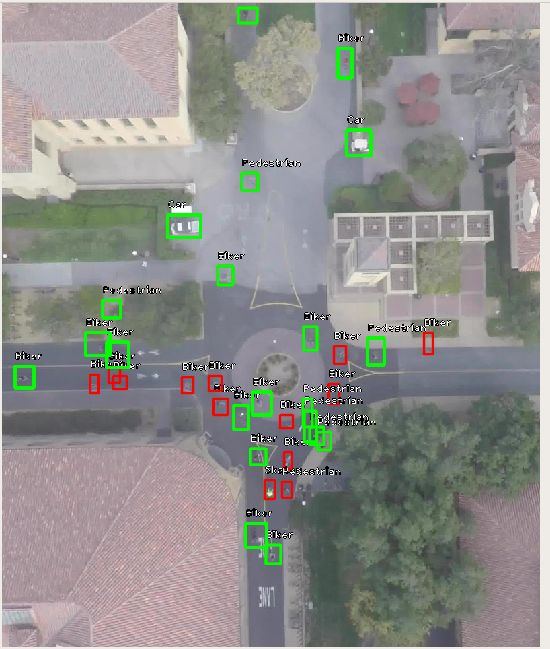
调整锚点大小:RetinaNet 的默认锚点大小为 32、64、128、256、512。这些锚点大小适用于大多数目标,但由于我们处理的是航空图像,某些目标可能小于 32。这个代码工程里提供了一个方便的工具,用于检查现有锚点是否有效。在下图中,绿色标注被锚点中的标注覆盖,红色标注将被忽略。可以看出,相当一部分标注对于最小的锚点大小来说也太小。
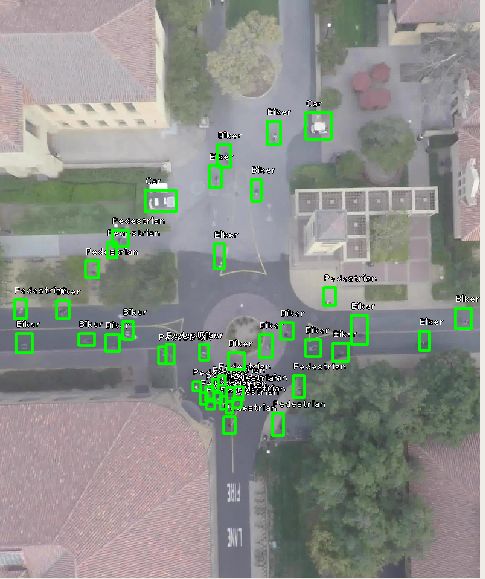
因此,我调整了锚点,丢弃512中最大的锚点,而是添加一个大小为16的小锚点。这显著改善了结果,如下所示:
keras_retinanet/bin/train.py --weights
snapshots/resnet50_coco_best_v2
.1.0.h5 --config config.ini csv
train_annotations.csv labels.csv --val-annotations
val_annotations.csv
到这里,就完成了!
这个模型训练速度很慢,我训练一晚上。
Biker:
0.4862
Car:
0.9363
Bus:
0.7892
Pedestrian:
0.7059
Weighted:
0.6376
结论
RetinaNet是一个强大的模型,使用特征金字塔网络。它能够用在航拍物体检测场景中,即使是目标尺寸极小、极具挑战性的数据集也可以。我大概花了一晚上的时间训练 RetinaNet,而训练出的模型性能还不错。接下来我准备探索如何进一步调整RetinaNet 架构,在航拍物体检测中能够获得足够高的精度。
参考资料:








