华人一作登ICCV 2021,实时超分新SOTA!AutoML显神威:1%参数量,超清视频70倍加速
新智元报道
新智元报道
作者:詹政
编辑:好困 小咸鱼
【新智元导读】东北大学王言治团队将网络结构搜索与剪枝搜索相结合,提出了全新的自动搜索框架。该AutoML框架得到的稀疏模型能够在移动设备上实时且高质量地处理视频超分辨率任务,最高可以将超清视频渲染加速70倍。
随着深度神经网络(deep neural network, DNN)的蓬勃发展,基于单张图像的超分辨率(single image super-resolution, SISR) 在近些年来取得了不断进步。
但基于深度学习的超分辨率(super-resolution, SR)方法在实际应用中常面临着计算和内存的巨大挑战,尤其是对于资源有限的平台,例如移动设备。
为了促进超分辨率在移动设备上的实时部署,东北大学王言治教授研究团队领衔提出了一种将超清网络结构和剪枝搜索相结合的自动搜索框架。
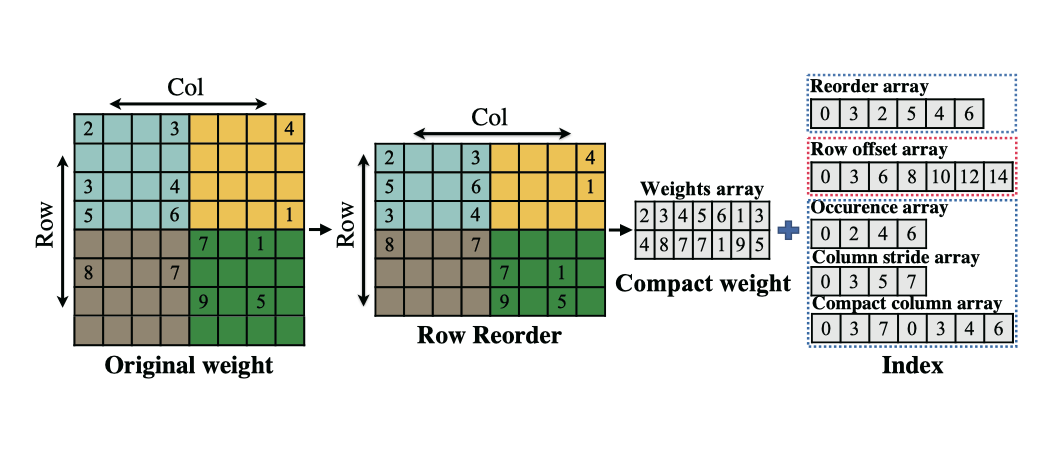
在本项工作中,作者采取了权重共享策略,引入了超级网络,并将该问题分解为三个阶段为:超级网络构建、编译器感知的结构和剪枝搜索,以及编译器感知的压缩倍率的搜索。
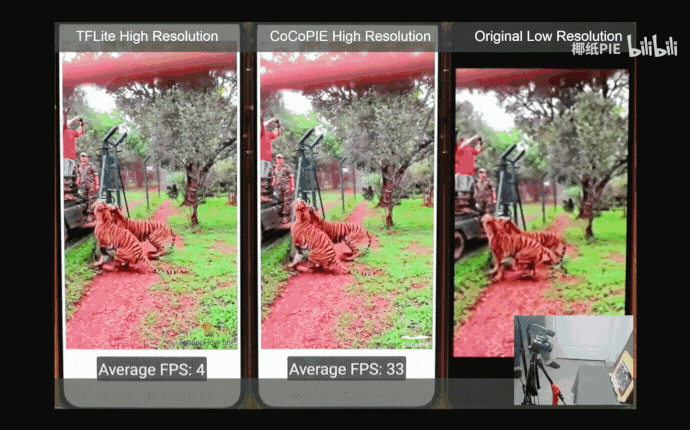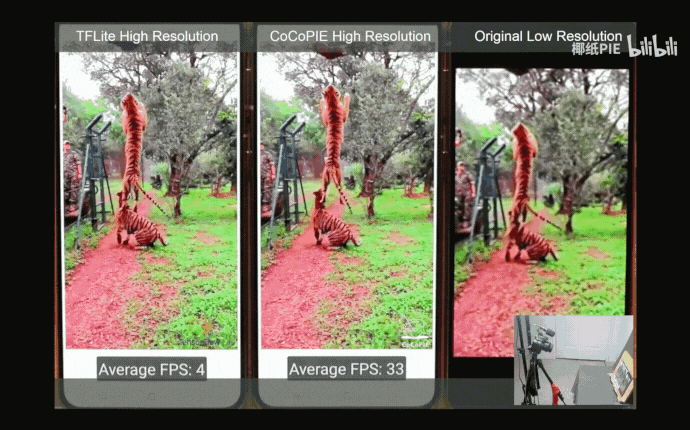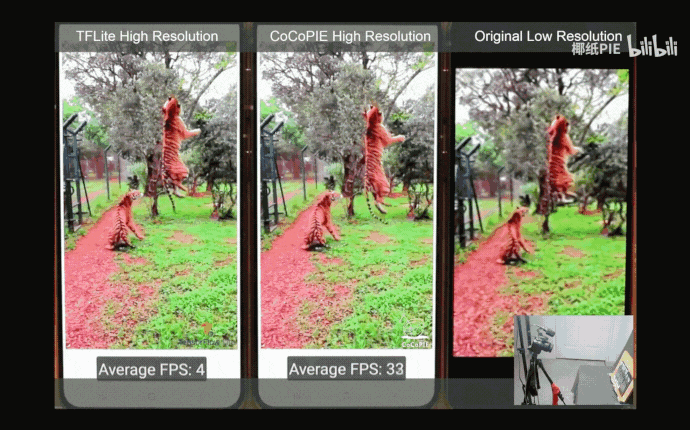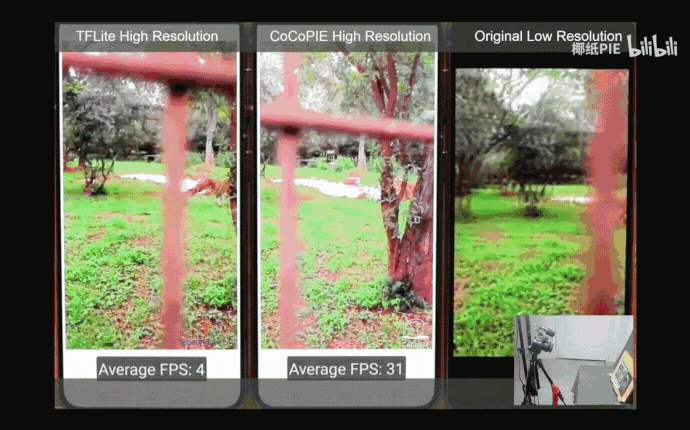
该套框架率先实现了在移动端(三星Galaxy S20)部署720p实时超清(每帧仅需数十毫秒),并保证了高图像品质。
目前,该文章已经被ICCV 2021会议收录。

论文链接:https://arxiv.org/pdf/2108.08910.pdf
演示视频:https://www.bilibili.com/video/BV1if4y1M7xU?spm_id_from=333.999.0.0
基于单张图像的超分辨率的主旨是将低分辨率的图像转化为具有更清晰细节和更多信息的高分辨率图像。它具有广泛的应用前景,例如犯罪现场分析、医学图像处理等。与此同时,随着直播和录像的蓬勃发展,人们日常生活中接触着越来越多的视频内容。
然而,由于通信带宽的限制,视频内容呈现在手机上时往往清晰度较低,无法充分利用显示器的高分辨率。除此之外,直播通常对每帧的延迟具有实时性的要求。
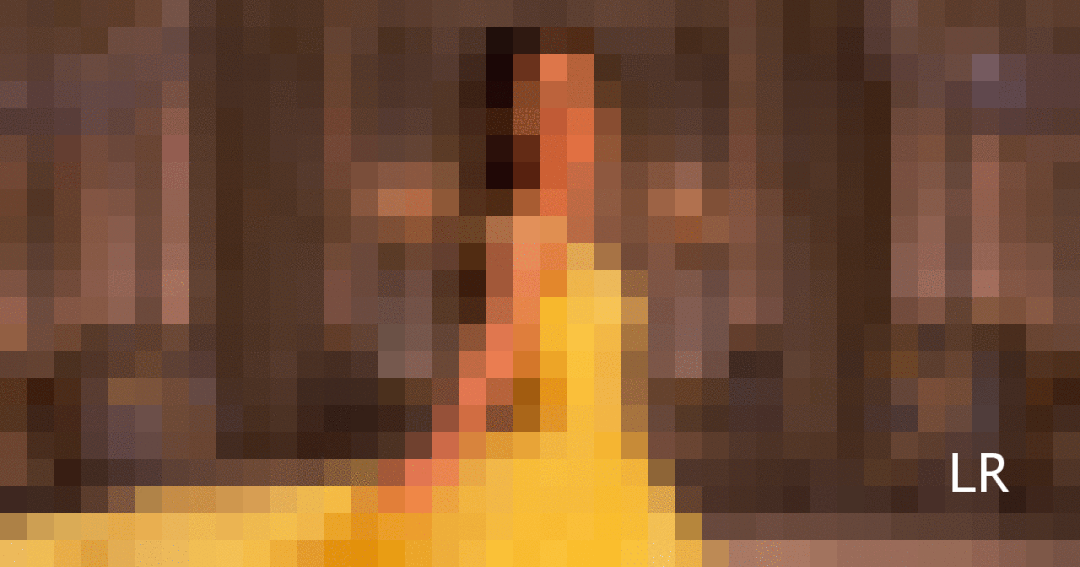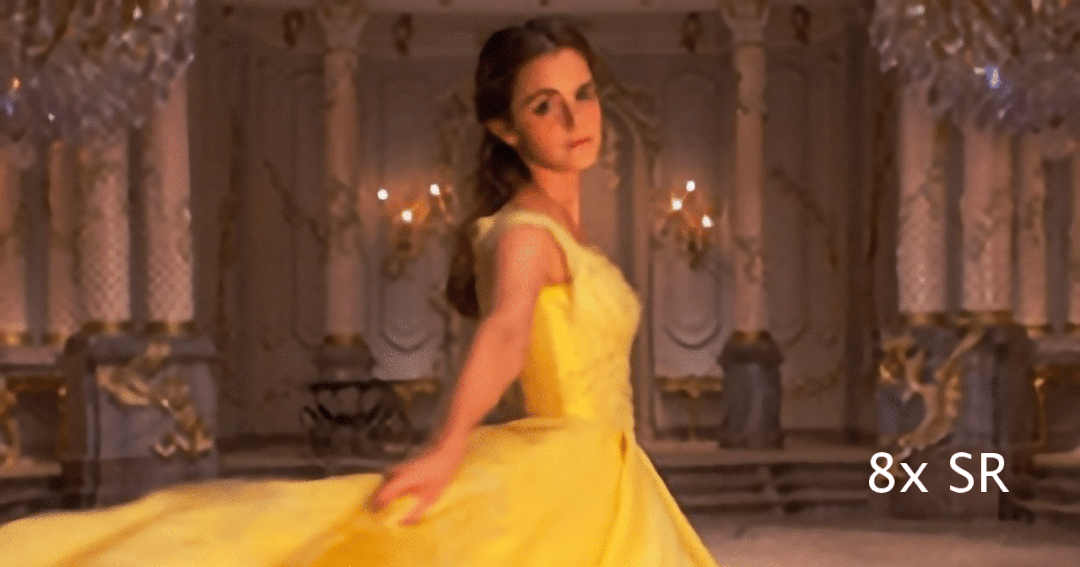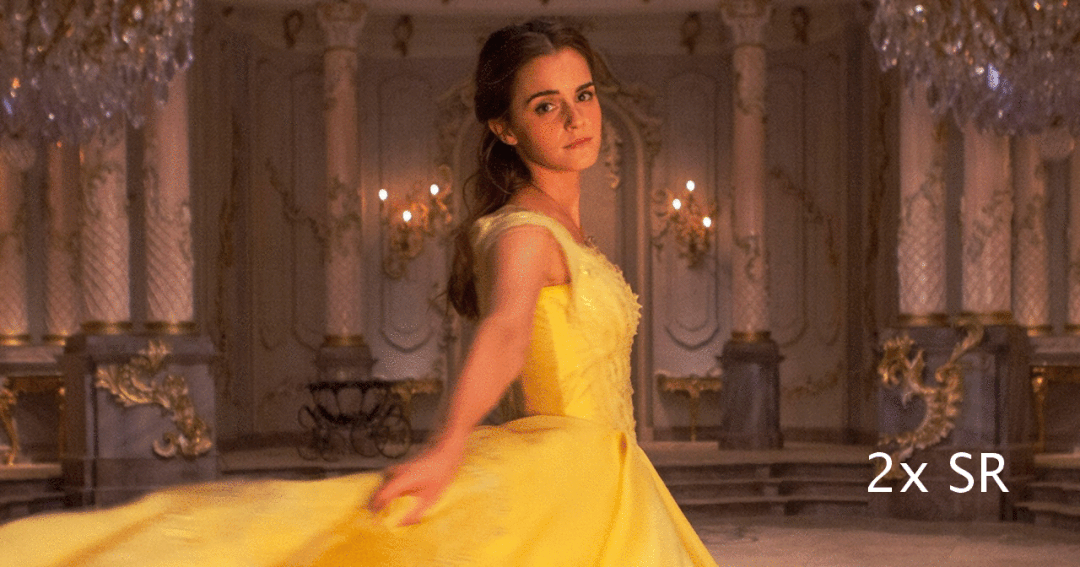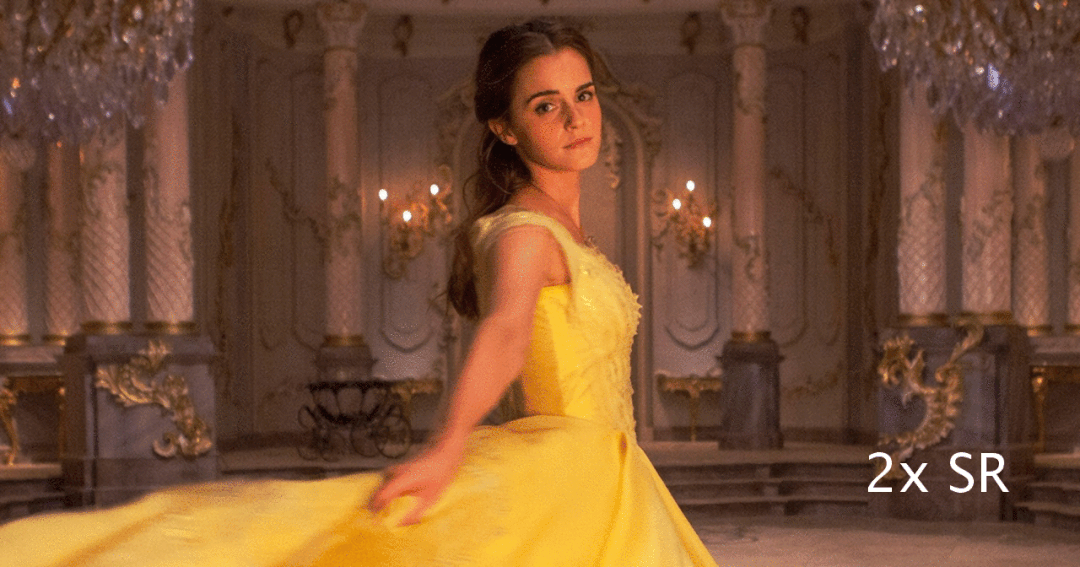
因此,在移动端本地实现实时的超清亟待研究。相较于经典的插值算法,基于深度网络的超清度方法可以在外部数据集上学习从低分辨率到高分辨的映射,因此往往能提供更为出色的视觉效果。但此类方法通常需要大量的计算的功耗,很难实现实时的部署。
方法实现
权重剪枝常用来去除神经网络的冗余度以降低资源需求并加速网络的前向推理。目前的权重剪枝工作主要分为非结构化的权重剪枝 (unstructured weight pruning)、粗粒度的结构化权重剪枝(coarse-grained structured pruning)和细粒度的结构化权重剪枝(fine-grained structured pruning)。
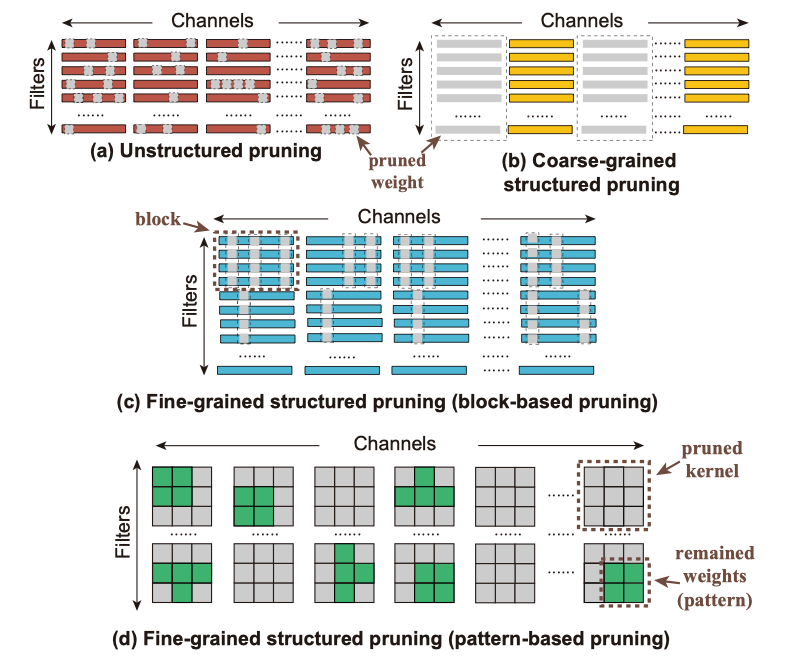
(a)非结构化的权重剪枝;(b)粗粒度的结构化权重剪枝;(c)细粒度的结构化权重剪枝-基于块;(d)细粒度的结构化权重剪枝-基于模式
先前的工作通常对整个神经网络模型采取固定的剪枝方案。由于不同的剪枝方案往往会造成不同的超清效果和加速性能,寻求每一层最适合的剪枝方法相较于对整个模型采取同一种剪枝方法会带来更好的性能。此外,由于剪枝的效果也取决于未剪枝起始模型的性能,搜索一个具有良好超清表现的起始模型也尤为重要。
在这项工作中,为了实现在边缘设备上的实时超分辨率,作者提出了一种结合网络结构和权重剪枝的搜索框架。
其中,框架包含寻找每个单元块最适合的超清模块和每层网络最佳的权重剪枝配置。而最终得到的稀疏模型可以满足在移动设备上720p等高分率的实时推理需求,即每帧仅需几十毫秒,并保持和最先进的超清方法相近的图像质量。
搜索问题则包含堆叠单元数目的确定、每个单元块中超清模块的选取、以及每层的剪枝方案和压缩率的选取。
然而,如果采取直接搜索的方式,由于搜索空间太过庞大,计算开销会过于昂贵。因此,为了减少时间和计算方面的搜素成本,该工作通过引入超级网络,利用权重共享的策略,将该搜索问题分解为三个阶段:
超级网络构建;
编译器感知的结构和剪枝搜索;
编译器感知的压缩倍率的搜索。
其中,超级网络构建包含超级网络的初始化和超级网络的训练。
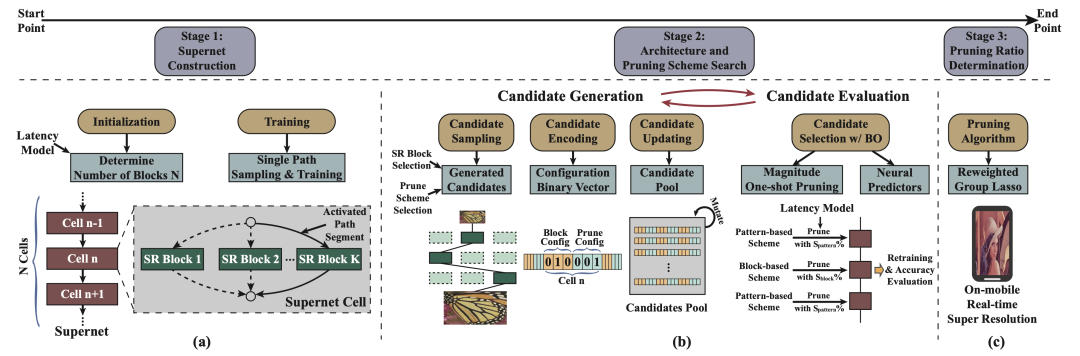
框架示意图:(a)超级网络构建;(b)编译器感知的结构和剪枝搜索;(c)编译器感知的压缩倍率的搜索
在初始化过程中需要确立超级网络堆叠单元的数目,而超级网络训练则为后续两个阶段提供了良好的起始网络模型。
下一步是进行每个单元块中超清模块以及每层网络中剪枝方案的选取。该步骤的目标是找到一个理想的网络,能在最大化图像质量的同时在编译器的帮助下满足实时部署的需求。具体而言,当网络推理延迟t≤50ms时,可以认为满足了实时性的需求。
最后一个步骤是压缩倍率的确定。通过利用加权动态正则化方法(reweighted dynamic regularization method),可以自动得到每一层的压缩倍率。
超级网络构建
在架构和剪枝搜索中,稀疏模型的性能在很大程度上取决于初始模型的准确度。为了获得各种训练完备的初始模型,最直接的方式是对每个架构进行单独训练。但这样的方式会造成巨大的训练开销。
因此,作者采用训练一个超级网络的方式来取代对每个架构单独训练的方法。对于任何一个新模型,仅需激活超级网络中的相应路径,即可获得训练完备的未剪枝初始模型,无需从头开始每一个新模型。
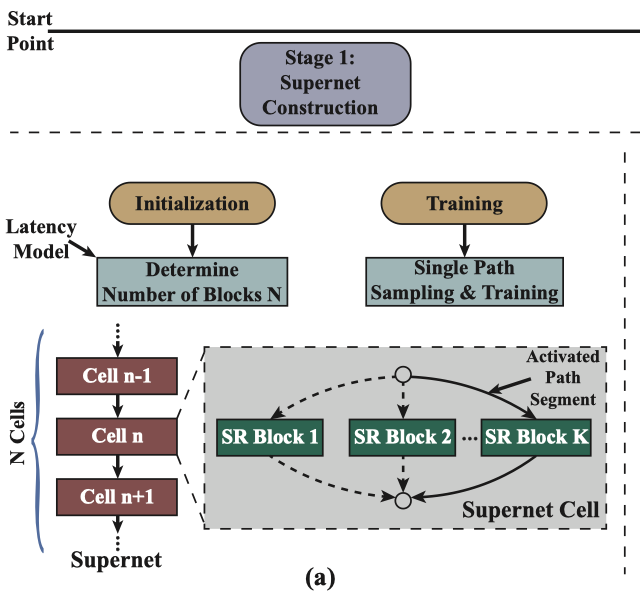
作者对架构搜索空间A进行编码形成一个超级网络,表示为S(A,W),其中W代表权重的合集。超级网络由N个单元块堆叠而成。每个单元块包含K个超清模块作为选项。
在本项工作中,作者采用两个具有高图像质量的超清模块:WDSR-A和WDSR-B作为超清模块选项。该框架不受限于超清模块的选取,可以推广到不同类型的超清模块。单元块n中的每个超清模块k的输出与下一个单元块n+1中的所有超清模块连接。
每个超级网络单元块中的超清模块选取定义为一个路径段,所有N个路径段的可能组合形成了架构搜索空间A,A的大小为KN。N个路径段构成了一条路径,即一个超清候选模型。在对超级网络训练的过程中,只有一条路径被激活,而其他未被选择的路径则不参与训练。
构建一个超级网络包含两个必要的步骤:
确定超级网络堆叠单元块的数目N;
充分训练超级网络以提供高图像质量的起始点并降低后续搜索过程的开销。
超清中广泛采用的几项技例如像素重组(pixel shuffling)和全局残差路径(global residual path)等通常难以被优化实现加速,会造成固定的延迟开销。
除此之外,每个单元块中的残差连接也会造成一定的难以降低的延迟开销,而该开销会随着堆叠单元块数目的增多而累积。因此,为满足实时部署的需求,堆叠单元块的数目应被合理选取。
本文通过构建延迟模型来确立堆叠单元块的数目。延迟模型可以快速准确的估计在目标设备(例如三星S20智能手机)上整体模型的推理延迟。延迟模型包含不同类型的网络层的延迟查找表,例如1X1卷积层、3X3卷积层、5X5卷积层、残差链接等。
对于每一种网络层,作者都会考虑几种不同的设置,包括卷积核的数目和输入输出特征图的大小。
延迟模型是通过在目标设备上测量实际推理延迟得到的,并且是编译器感知的。由于不涉及训练过程,延迟模型的构建时间可以忽略不计。此外,延迟模型中还包含不同剪枝方式及压缩率下的稀疏模型的延迟推理,将被用于阶段2中。
在目标设备上模型整体的推理延迟可以通过累计每层的延迟得到。超级网络的堆叠单元数目可以由候选超清模型的目标延迟t来确定。此外,将堆叠单元数目与候选超清模型的选取分开进行可以有效降低搜素的复杂度。
在超级网络的训练过程中,训练目标是最小化损失函数 L(A, W)。候选超清模型a将直接从超清网络中继承权重W(a)。因此,超清网络的训练需要保证每一个候选结构a ∈ A 的权重都被充分训练。
在本文中,作者采取单路径采样和训练的策略来加速超级网络的收敛。
编译器感知的结构和剪枝搜索
在搜索过程中,每一个候选g包含每个单元块中超清模块的选取以及每一层的剪枝方案选取。
编译器感知的结构和剪枝搜索包含两个主要步骤:
候选的生成;
候选的评估。
为了提升搜寻效率,该文在候选的生成中采取基于进化的候选更新,并在候选的评估中采用贝叶斯优化(Bayesian optimization,BO)。
本文将每一个候选g编码为一个二进制向量,用于表示每一个单元块中的某种超清模块和每一层的某种剪枝方法是否被选取。在剪枝中,每一层的压缩倍率也应被确定。然而,搜寻每层的压缩倍率也会带来不小的开销。因此,在本阶段中,压缩倍率被设置为满足目标延迟的最小压缩倍率。
在每次迭代中,还需要更新候选池。为了更有效地更新候选池,本文采用基于进化的候选更新方法。所有被评估的候选及其表现都会被记录下来。同时,评估表现最佳的候选将被进行变异操作,通过随机改变一个超清模块或一个随机层的剪枝方案,来得到新的候选。
具体而言,本文将首选择评价最高的H个候选,并迭代的改变这H个候选中的每一个,知道产生了C个新的候选。
由于剪枝和重新训练会造成很高的时间成本,本文采取贝叶斯优化来加速候选的评估。当C个候选产生后,首先使用贝叶斯优化来选取B(B<C)个具有更优潜在性能的候选。被选中的候选将被进行准确的超清性能评估,而未被选中的候选则不会进行准确评估。这种方法可以有效减少实际评估的候选数目。
贝叶斯优化包含两个重要组成部分,一个是训练一组神经网络预测器,另一个是根据预测器的数值选取候选。神经网络预测器组用于提供平均超清预测值以及未经评估的候选的相应不确定性估计。此后,贝叶斯优化将选择能够最大化获取函数的候选。

贝叶斯优化评估
编译器感知的压缩倍率的搜索
区别于先前工作采用的Lasso优化或交替方向乘子法(Alternating Direction Methods of Multipliers , ADMM),本文采取动态正则化方法来自动选取每一层的最佳压缩倍率。
该算法的基本方式是为每一个权重或剪枝模式赋予一个惩罚因子,在训练(剪枝)过程中,对数值大的权重降低惩罚因子,而对数值小的权重增大惩罚因子。在收敛后,每层所需的压缩倍率将被自动确定。
该方法适用于不用的剪枝方案和不同类型的网络层。
实验结果
在实验中,所有超清模型的训练都在DIV2K的训练集 。在测试过程中,该文采用了四个基准数据集Set5、Set14、B100和Urban100。PSNR和SSIM是根据YCbCr颜色空间的亮度通道计算的。延迟的测试是在三星Galaxry S20智能手机的GPU上进行的。
与其他最近先进的超清方法的对比如下表所示。PSNR和SSIM作为度量图像质量的指标。所有的输出都具有相同的高分辨率,即720p-1280X720。在评估过程中,作者采用了不同的目标延迟t的数值。
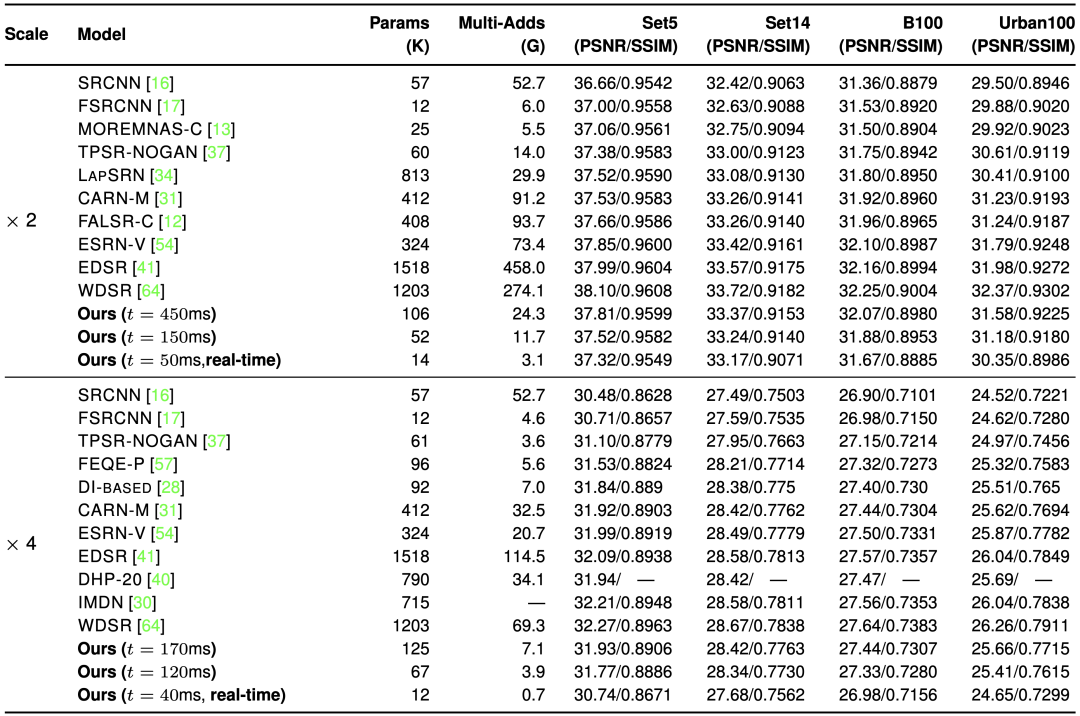
与其他先进的高效超清模型的对比
由于实时运行通常需要至少20帧/秒,本文对x2升采样任务采用t为50毫秒,x4升采样任务采用t=40毫秒来获得满足实时推理需求的模型。
当目标延迟为450毫秒时,本文得到的模型对x2升采样任务可以采用更少的累加累积操作数(Multiply-Accumulate Operations,MACs)获得优于CARN-M和FALSR-C的PSNR/SSIM表现。
当t=150毫秒时,本文的得到的模型可以采用相近或更少的累加累积操作数获得比FSRCNN、MOREMNAS-C和TPSR-NOGAN。此外,这两种目标延迟下得到的模型都取得了比SR CNN和LapSRN更好的表现。
与ESRN-V、EDSR和WDSR相比,本文的得到的模型在保持高PSNR/SSIM的同时极大地节省了累加累积操作数。特别地,当t=50毫秒时,本文提出的方法获得了满足实时性要求的超轻量级模型,该模型仍然保持着不错的PSNR/SSIM表现。
对于x4升采样任务,本文以t=120毫秒获得的模型比SRCNN、FSRCNN、以及FEQE-P性能更佳。当目标延迟t=170毫秒时,本文获得的模型比DI和CARN-M具备更佳的PSNR/SSIM表现,同时需要相似甚至更少的累加累积操作数。此外,当t=40毫秒时,本文获得的模型在保持不错的PSNR/SSIM表现的同时,满足了实施推理的需求。
下图中展示了本文获得的模型与其他超清模型在x4升采样任务上的视觉表现对比。可以看出,本文获得的模型在极大地节约了模型参数与累加累积操作数的同时,生成的高分辨率图像在视觉上与WDSR几乎无异。

与其他超清模型在x4升采样任务上的视觉表现对比,模型名字下列出了模型所需的参数及累加累积操作数
此外,本文还进行了基于编译器优化的实时性的评估,结果如下图所示。可以看出,对于相同的超清模型,本文的编译器优化方法相较于其他加速框架在各种升采样尺度上均实现了最高的推理帧数(frames-per-second,FPS)。
用于测试的x2及x3模型是通过设置t=50毫秒获得的,而x4为设置t=50毫秒取得的。
从图中还可以看出,本文提出的方法的推理帧数是满足实时性需求的,在x2及x3任务上,本文得到的模型的推理帧数高于20,在x4任务上则高于25。
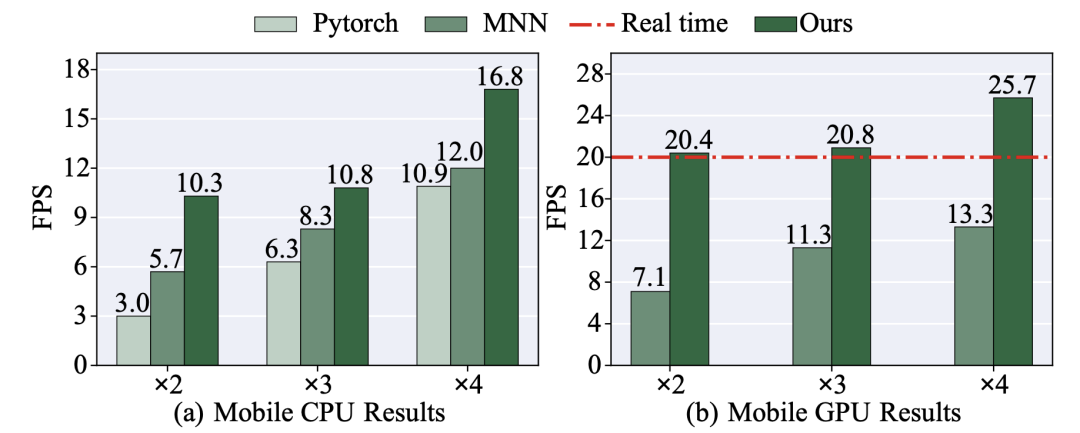
在移动端与其他最先进的移动加速框架的比较
MobiSR和FEQE-P也在移动设备上进行了超清推理。在移动端GPU上,它们的推理延迟分别为2792毫秒和912毫秒,这是远远超过实时性需求的。
需要强调的是,本文率先在移动端实现了实时超清推理,并且可以保证模型在720p任务上具备与其他高效超清模型具有竞争力的图像质量。
作者还研究了结构搜索和剪枝搜索各自的影响。对于x2任务,仅仅采取结构搜索在Set5上达到了37.84的PSNR,略高于同时采取结构和剪枝搜索得到的结果。但是由于没有采取剪枝搜索,计算量无法得到优化,推理速度较低,仅为1.82 FPS。
在使用t=150毫秒仅采取剪枝搜索时,取得的模型达到了6.8FPS,但PSNR较低,在Set5上为37.4。因此可以看出,剪枝搜素有效提高了加速性能,而结构搜索可以有效缓解由于剪枝导致的超清性能损失。
总结
本文将网络结构搜索与剪枝搜索相结合,提出了相应的自动搜索框架。该框架得到的稀疏模型可以实现在移动设备上的实时超清,并且可以保证与其他先进的有效超清模型相较有竞争力的图像质量。
参考资料:
https://arxiv.org/pdf/2108.08910.pdf
https://www.bilibili.com/video/BV1if4y1M7xU?spm_id_from=333.999.0.0



