神经网络推理加速之模型量化
作者:赵鹏,陈新宇,秦臻南,叶军
翻译:包怡欣
1. 引言
在深度学习中,推理是指将一个预先训练好的神经网络模型部署到实际业务场景中,如图像分类、物体检测、在线翻译等。由于推理直接面向用户,因此推理性能至关重要,尤其对于企业级产品而言更是如此。
衡量推理性能的重要指标包括延迟(latency)和吞吐量(throughput)。延迟是指完成一次预测所需的时间,吞吐量是指单位时间内处理数据的数量。低延迟和高吞吐量能够保证良好的用户体验和工业生产要求。
许多云服务商和硬件供应商提供了一系列针对推理优化的基础设施,例如亚马逊的 SageMaker、Deep Learning AMIs,英特尔 ® 的 Deep Learning Boost、矢量神经网络指令集 (VNNI) 等。
除了硬件层面的优化,在算法层面,模型量化是加速神经网络推理的有效手段之一。Apache MXNet * 社区提供了丰富的量化工具,用户无需重新训练模型,只需通过量化工具就可以对训练好的模型进行量化。量化后的模型可以通过像 VNNI 这样的低精度(INT8)指令进行加速,有助于节省存储带宽,提高缓存命中率,减少能耗。
通过 MXNet * 进行模型量化后,ResNet50 V1 可在 AWS* EC2 CPU 实例中达到 6.42 倍的性能加速(其中运算符融合获得了 1.75 倍的加速,VNNI 的 INT8 指令则带来了 3.66 倍的加速),同时精度损失仅为 0.38%,可以说达到了速度和精度的完美平衡。
本文先描述模型量化的原理以及在 MXNet * 上的实现,然后讲述如何从用户角度使用量化工具,最后介绍在英特尔 ® 至强 ® 处理器上 VNNI 带来的性能提升。
2. 模型量化
MXNet * 支持从单精度(FP32)到有符号的 8 比特整型(s8)以及无符号的 8 比特整型(u8)的模型量化。u8 可以用于 CNN 网络的推理。对于大多数 CNN 网络而言,Relu 是常用的激活函数,其输出是非负的。因此,在 CNN 网络的推理中使用 u8 的优势显而易见——我们可以多使用 1 比特来表示数据从而达到更高的精度。s8 则适用于通用的模型量化。
在使用 MXNet * 进行模型量化时,用户无需重新训练模型,只需通过量化校准工具就可以对训练好的 FP32 模型进行量化加速,因此部署过程非常方便快捷。
模型的量化推理包含两个阶段:

图 1. MXNet INT8 推理流程示意图
量化校准过程(预处理阶段),我们使用验证集中的一小部分图片(通常为整个数据集的 1-5%)来收集数据分布的信息,包括最小值 / 最大值、基于熵理论的最佳阈值、基于对称量化的量化因子等。最终,这些量化参数会被记录在新生成的量化模型中。
INT8 推理(运行阶段), 量化模型可以像原始模型一样被加载并用于推理
3. 模型优化
在深度学习领域,MXNet * 是最早提供完整量化方案的深度学习框架之一,其内置了很多高级的性能优化工具,如支持 INT8 的数据加载器、离线校准、图优化等。通过图优化实现的运算符融合,是对一些常见的操作进行功能合并,如 Conv+Relu, Conv+BN, Conv+Sum 等。运算符融合能够减少在量化过程中反复的数据类型转化,从而使得量化后的网络相比于原始模型更加简洁高效。下图中的 ResNet50 V1 显示了网络在运算符融合和量化前后的变化。
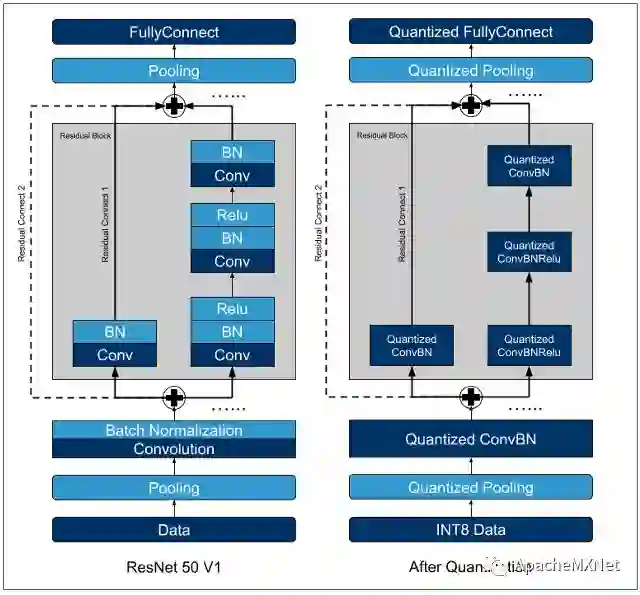
图 2. ResNet50 V1 网络结构(左图:FP32,右图:INT8)
另外值得一提的是,当用户在不同的硬件上部署量化模型时, 无论是否支持 VNNI 指令,MXNet * 的量化方案都是可用的。例如从 C5.18x.large (英特尔 ® 第一代可扩展处理器,不支持 VNNI 指令) 切换到 C5.24x.large (英特尔 ® 第二代可扩展处理器,支持 VNNI 指令),用户无需修改代码,同时又能获得大幅度的性能提升。
图 3. 英特尔 ® Deep Learning Boost
4. 模型部署
用户可以使用 MXNet * 的量化校准工具和 API 轻松地将他们的 FP32 模型量化成 INT8 模型。MXNet * 官方也提供了图像分类和物体检测 (SSD-VGG16) 的量化示例。用户还可以参考量化 API 来将这些工具集成到实际的推理任务中。
下面,以 SSD-VGG16 为例介绍 MXNet * 的模型量化过程。
4.1 准备阶段
使用以下命令安装 MXNet*,包含英特尔 ®MKL 库能够优化推理性能。
pip install --pre mxnet-mkl
首先,下载训练好的 SSD-VGG16 模型 和打包的二进制数据。创建 model 和 data 的目录,解压 zip 文件并重命名,如下所示:
data/
|--val.rec
|--val.lxt
|--val.idx
model/
|--ssd_vgg16_reduced_300–0000.params
|--ssd_vgg16_reduced_300-symbol.json
然后,你可以使用如下命令来验证 FP32 的模型:
# USE MKLDNN AS SUBGRAPH BACKEND
export MXNET_SUBGRAPH_BACKEND=MKLDNN
python evaluate.py --cpu --num-batch 10 --batch-size 224 --deploy --prefix=./model/ssd_
4.2 量化阶段
MXNet * 为 SSD-VGG16 提供了一个量化脚本。用户可以通过设置不同的配置项将模型从 FP32 量化成 INT8,包括 batch size、量化用的 batch 数目、校准模式、目标数据类型、不做量化的层,以及数据加载器的其他配置。我们可以使用如下指令进行量化,默认情况下脚本使用 5 个 batch(每个 batch 包含 32 个样本)进行量化:
python quantization.py
量化后的 INT8 模型会以如下形式存储在 model 目录下。
data/
|--val.rec
|--val.lxt
|--val.idx
model/
|--ssd_vgg16_reduced_300–0000.params
|--ssd_vgg16_reduced_300-symbol.json
|--cqssd_vgg16_reduced_300–0000.params
|--cqssd_vgg16_reduced_300-symbol.json
4.3 部署 INT8 推理
使用如下指令执行 INT8 模型的推理:
python evaluate.py --cpu --num-batch 10 --batch-size 224 --deploy --prefix=./model/cqssd_
4.4 结果可视化
从 Pascal VOC2007 验证集中取一张图片,其检测结果如下图所示,图 4.1 显示的是 FP32 模型的推理结果,图 4.2 显示的是 INT8 模型的推理结果。
结果可视化的指令如下:
# Download demo image
python data/demo/download_demo_images.py
# visualize float32 detection
python demo.py --cpu --network vgg16_reduced --data-shape 300 --thresh 0.4 --deploy --prefix=./model/ssd_
# visualize int8 detection
python demo.py --cpu --network vgg16_reduced --data-shape 300 --thresh 0.4 --deploy --prefix=./model/cqssd_
图 4.1. SSD-VGG 检测结果, FP32

图 4.2. SSD-VGG 检测结果, INT8
5. 性能
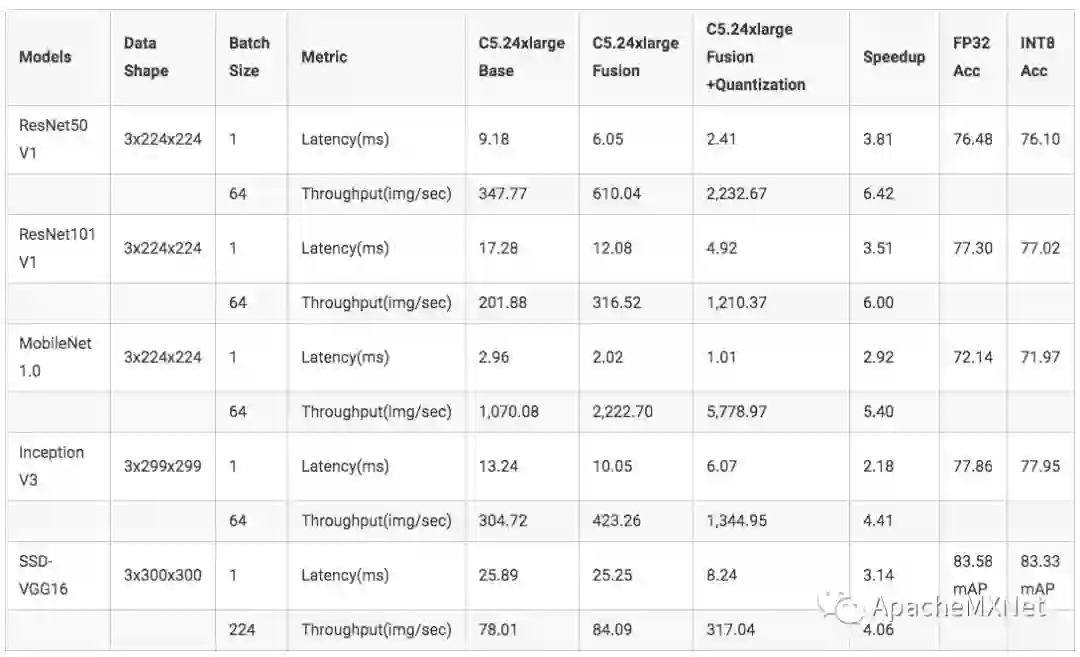
本节将展示模型量化的性能提升,所测数据均来自 AWS EC2 C5.24xlarge 实例上的英特尔 ® 第二代可扩展处理器(支持 VNNI 指令)。完整的硬件和软件配置请参阅通知和免责声明。更多的模型和性能数据请参考 Apache / MXNet C ++ 接口和 GluonCV 模型中的示例。
通过运算符融合和模型量化,图 5 中的总吞吐量得到了从 6.42X 到 4.06X 不等的显著提高。其中,运算符融合带来的加速随着模型中可融合的运算符数量的多少而变化。
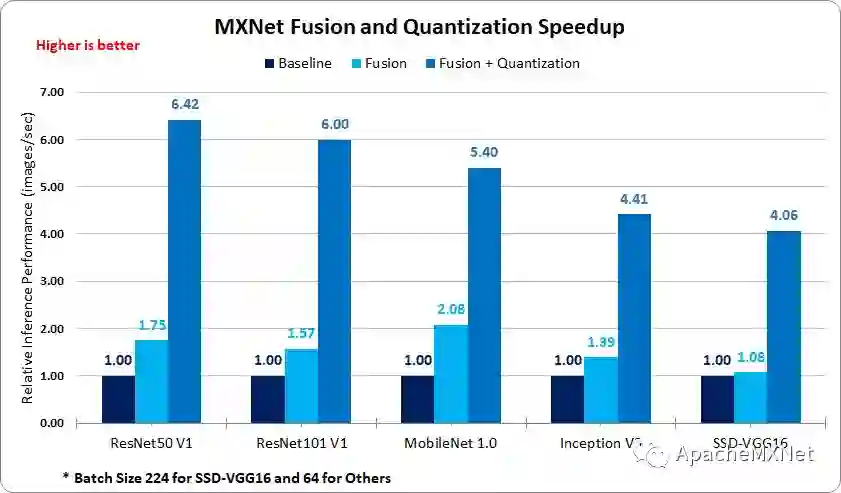
图 5. MXNet* 融合和量化加速对比
模型量化则可以为大部分模型提供稳定的加速,ResNet 50 v1 为 3.66X,ResNet 101 v1 为 3.82X,SSD-VGG16 为 3.77X,其值非常接近于 INT8 的理论加速比——4X。
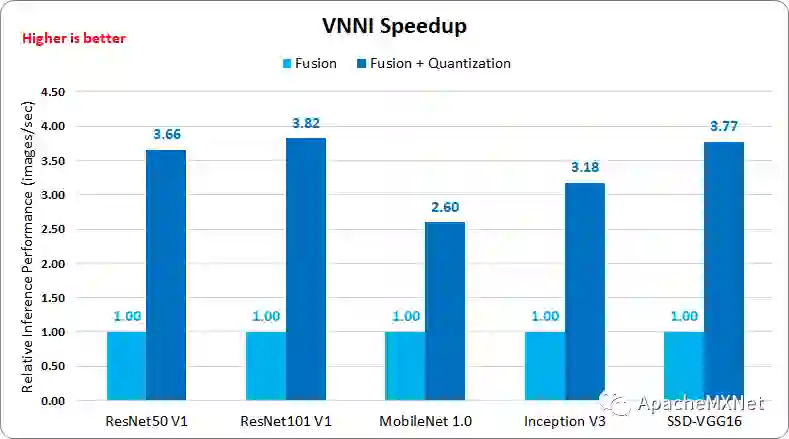
图 6. MXNet* VNNI 加速比
在图 7 中的延迟测试中,运行时间越短表示性能越好。除了 SSD-VGG16 之外,我们测试的模型都可以在 7 毫秒内完成推理。特别是对于需要在移动端部署的 MobileNet V1,其网络计算时间只需 1.01 毫秒,达到了极佳的速度。另外,实际生产环境通常并不需要使用 CPU 中的所有核心进行推理任务,建议可以选取适当的计算核心(比如 4 个),以达到推理时间和成本的最优配比。
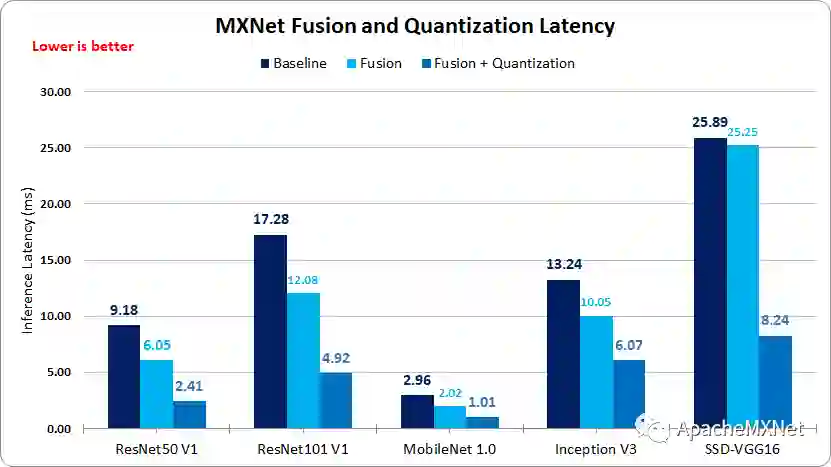
图 7. MXNet* 延迟比较
除了极佳的加速,量化后的模型的准确性也非常接近于 FP32 模型的精度,如图 8 所示,量化后的精度损失低于 0.5%。
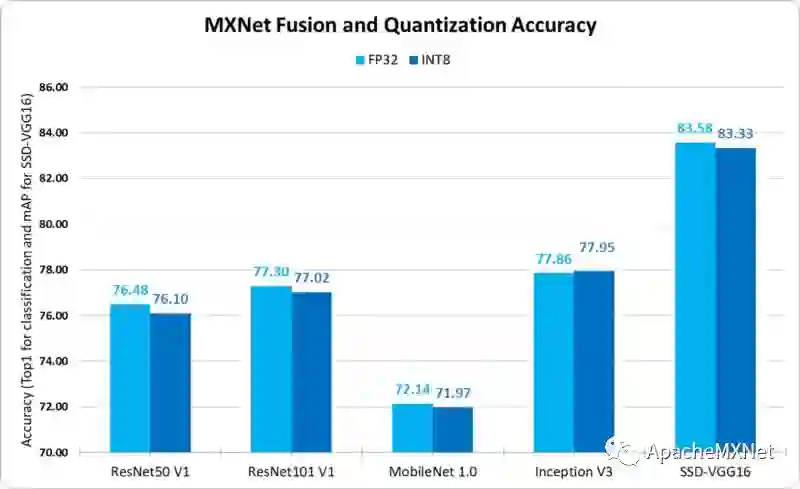
图 8. MXNet* 融合和量化精度对比
6. 总结
对于图像分类和物体检测的 CNN 网络,经过运算符融合和 INT8 量化后进行推理能够带来显著的加速。
量化后的 INT8 模型的精度与 FP32 模型的精度很接近,差异小于 0.5%。
第二代英特尔 ® 至强 ® 可扩展处理器,使用英特尔 ®DL Boost 和新的 VNNI 指令集,能够让用户无需修改代码即可进一步提升模型的计算性能(~4X)。
7. 感谢
感谢 Apache 社区和亚马逊 MXNet 团队的支持。感谢 Mu Li, Jun Wu, Da Zheng, Ziheng Jiang, Sheng Zha, Anirudh Subramanian, Kim Sukwon, Haibin Lin, Yixin Bao, Emily Hutson , Emily Backus 提供的帮助。另外也感谢 Apache MXNet 的用户提出的很多中肯的意见和建议。
8. 附录
9. 通知和免责申明
性能测试中使用的软件和工作集群可能只针对英特尔 ® 微处理器的性能进行了优化。
如 SYSmark 和 MobileMark 等的性能测试是通过特定的计算机系统、组件、软件、操作符和函数进行测量的,上述任何因素的改变都可能引起结果的改变。您需要综合其他信息和性能测试,包括与其他产品组合时该产品的性能,以帮助您全面评估您的预期购买。更多完整信息请访问 www.intel.com/benchmarks。
性能结果基于 AWS 截至 2019 年 7 月 1 日的测试,并不能反映所有公开可用的安全更新。没有任何产品或组件是绝对安全的。
测试配置:
重现脚本: https://github.com/intel/optimized-models/tree/v1.0.6/mxnet/blog/medium_vnni
软件: Apache MXNet 1.5.0b20190623
硬件: AWS EC2 c5.24xlarge 实例, 基于英特尔 ® 第二代可扩展至强 ® 处理器(Cascade Lake),全核频率为 3.6GHz,单核最高频率可达 3.9GHz
英特尔、英特尔标识和英特尔至强是英特尔公司或其在美国和 / 或其他国家的子公司的商标。* 其他名称和品牌可能被视为他人的财产。© 英特尔公司