
论文题目
机器学习在固体材料科学中的最新进展和应用,Recent advances and applications of machine learning in solidstate materials science
论文简介
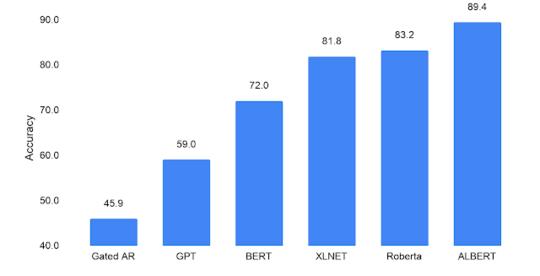
自从一年前BERT问世以来,自然语言研究已经拥抱了一个新的范例,利用大量现有文本来使用自我监督来预先训练模型的参数,而不需要数据注释。因此,不需要从头开始为自然语言处理(NLP)训练机器学习模型,我们可以从一个具有语言知识的模型开始。但是,为了改进这种新的自然语言处理方法,我们必须了解到底是什么对语言理解性能有贡献——网络的高度(即,层的数量)、宽度(隐藏层表示的大小)、自我监督的学习标准,或者完全其他什么? “ALBERT:一个自我监督的语言表征学习的小BERT”,接受在ICLR2020上,我们对BERT进行了升级,提高了12项NLP任务的最新性能,包括竞争性斯坦福问答数据集(SQuAD v2.0)和SAT式阅读理解竞赛基准。ALBERT是作为TensorFlow之上的一个开源实现发布的,它包含了许多现成的ALBERT语言表示模型。
论文作者
Radu Soricut ,Zhenzhong Lan,来自Google研究院的研究科学家
成为VIP会员查看完整内容
相关内容

Radu Soricut ,来自Google研究院的研究科学家
专知会员服务
12+阅读 · 2020年1月7日
Arxiv
11+阅读 · 2019年10月30日
Arxiv
15+阅读 · 2018年10月11日
相关主题




相关VIP内容
专知会员服务
12+阅读 · 2020年1月7日
相关资讯