如何用Keras来构建LSTM模型,并且调参

本文为 AI 研习社编译的技术博客,原标题 :
Choosing the right Hyperparameters for a simple LSTM using Keras
作者 | Karsten Eckhardt
翻译 | 涂世文、小Y的彩笔
校对 | 邓普斯•杰弗 审核| 酱番梨 整理 | 菠萝妹
原文链接:
https://towardsdatascience.com/choosing-the-right-hyperparameters-for-a-simple-lstm-using-keras-f8e9ed76f046
注:本文的相关链接请点击文末【阅读原文】进行访问
如何用Keras来构建LSTM模型,并且调参

图片来自 Unsplash 上的 Mika Baumeister
搭建机器学习模型从来都没有像现在这么容易过,许多文章给出了有关于数据科学是什么,它能实现什么的高层次的概述,或是深入讨论了非常小的实现细节。这就使得一些有志数据科学家,像我之前那样,经常看着notebook想“它看起来太棒了,但为什么作者选择这种类型的结构?如何确定神经元的数量是这么多?为什么选择这种激活函数?”这篇文章中,我想给谈论如何用直觉做出决定帮你在构建模型时找到正确的参数等等,文章基于一个非常基础的 LSTM 由姓氏来预测性别。因为已经有许多很棒的关于数学和递归神经网络 (RNN) 的基本概念的课程,如:Andrew Ng’s deep learning specialization 或 Medium上的课程,所以我不会深入讨论它们,并把这些知识视为已知。我们将只关注如何在高层次用 Keras 实施它。目标是更实际的理解这些构建神经网络是需要做的决定,尤其是在如何选择超参数上。
整篇文章连同代码和输出可以在 Github 上找到。
关于 Keras:自从2017年支持 TensorFlow 以来,Keras 作为一个易于使用和直观的界面,已经更加复杂的机器学习库上引人瞩目。所以构建真实的神经网路并训练模型差不多是我们这个脚本中最短的部分。
第一步是决定我们想用的网络的类型,因为这个决定会影响我们的数据预处理过程。在任何名字中,字母的顺序都是很重要的,这意味着,如果我们想要用神经网络分析一个名字,RNN 是一个合理的选择。Long Short-Term Memory Networks (LSTM) 是一种特殊形式的RNN,当输入块链变长时,LSTM 找到正确特征的功能变得尤为强大。在我们的例子中,输入总是一个字符串(名字),输出是一个 1x2 向量,用来指示这个名字是否属于男人或女人。
在做了这个决定之后,我们将开始加载所有将要用到的的包和数据集 --一个包含超过 1.5 Mio 德国用户和他们名字性别的数据集,女性用 f 编码,男性用 m 编码。
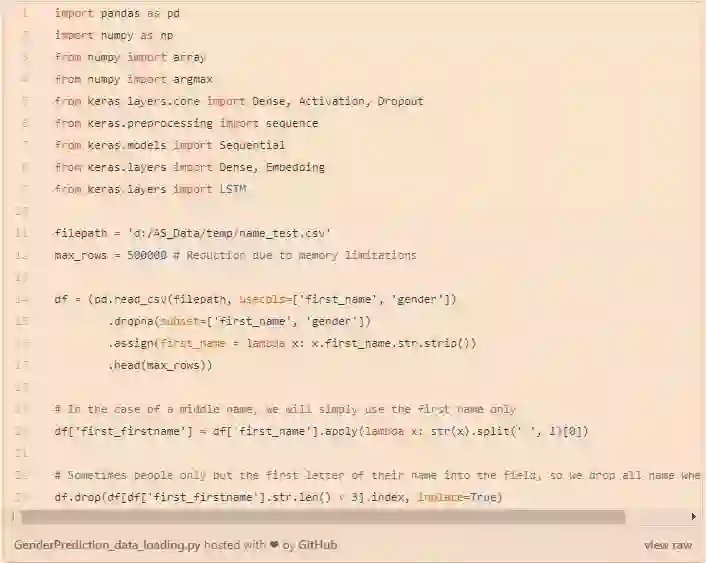
语句预处理
任何自然语言处理的接下来这一步都是将输入转换为机器可读的向量格式。理论上,Keras的神经网络能够处理不同尺寸的变量。在实践中,使用固定长度输入Keras可以显著提高效果,尤其是在训练期间。这种行为的原因是,这种固定的输入长度允许创建固定尺寸的张量,因此更稳定的权重。
首先,我们将把每个名字转换成一个向量。我们将使用的方法是所谓的独热编码。
这里,每个单词都由n个二进制子向量的向量表示,其中n是字母表中不同字符的数目(26使用英语字母表)。我们不能简单地将每一个字符转换成它在字母表中的位置,例如a-1、b-2等)的原因是,这将导致网络假定字符是按顺序排列的,而不是按类别排列的-字母z“值”不超过a。
例如:
S 表示为:
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]hello 表示为:
[[0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]既然我们已经确定了输入的形式,我们有两个决定要做:char向量应该有多长(我们允许有多少个不同的字符)和name向量应该有多长(我们想看多少个字符)。我们只允许使用德语字母表(标准拉丁语+öäü)中最常见的字符和连字符,这是许多旧名称的一部分。
为了简单起见,我们将把名称向量的长度设置为数据集中最长名称的长度,但将25作为上限,以确保输入向量不会因为一个人在输入过程中出错而变得太大。
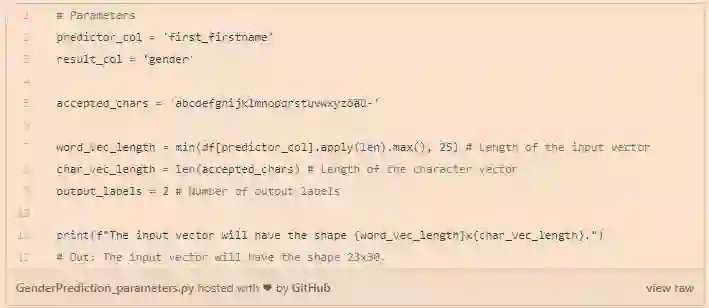
Scikit Learn已经在它的预处理库中加入了独热编码算法。然而,在这种情况下,由于我们的特殊情况,即我们不是将标签转换为向量,而是将每个字符串拆分为其字符,因此创建自定义算法似乎比预处理(否则需要的)要快。
已经表明,numpy数组需要的内存比python列表少4倍左右。出于这个原因,我们使用列表理解作为创建输入数组的一种更简单的方法,但是已经将每个单词向量转换为列表中的一个数组。在处理numpy数组时,我们必须确保组合的所有列表和/或数组具有相同的尺寸。

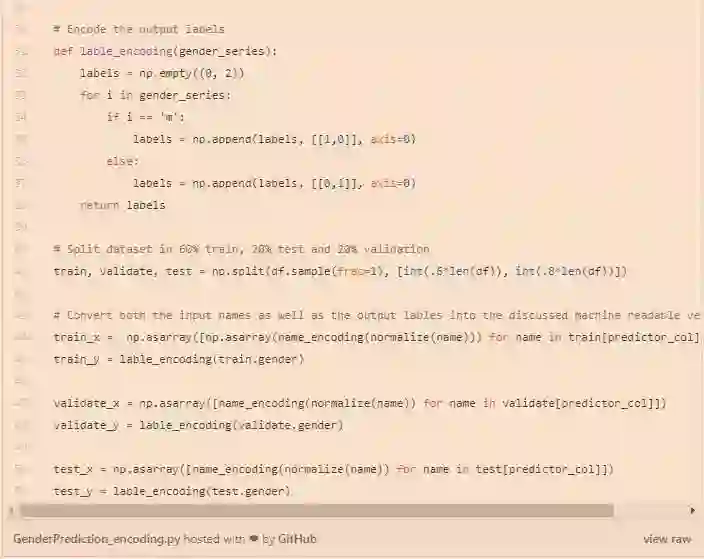
已经准备好了输入,我们就可以开始构建我们的神经网络了。我们已经决定了模型(LSTM)。在keras中,我们可以简单地将多个层叠加在一起,为此,我们需要将模型初始化为sequential()。
选择正确的节点数和层数
没有最终的明确的规则关于我们应该选择多少节点(或隐藏神经元)或者多少层,通常试验和错误的方法可以给你最好的结果。最常见的架构是 K 折交叉验证。然而,即使对于一个测试过程,我们需要选择一些(k)数量的节点。
下边的公式可能会帮你开始:
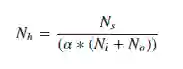
Ni 是输入神经元的数量,No 是输出神经元的数量,Ns 是在训练数据中样本的数量,α 代表了通常介于2到10之间的比例因子。我们可以计算8个不同的数来输入我们的验证过程中,并基于最终得到的验证损失找到最优的模型。
如果问题很简单并且时间紧迫,有各种其他法则来决定节点的数量,这几乎仅仅基于输入和输出神经元。我们需要注意的是,虽然使用方便,他们很少能产生最佳的结果。这只是其中的一个例子,我们将用这个作为基本的模型。
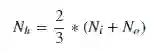

前边提到过,对于要用的隐藏层的数量也一样有很大的不确定性。同样,任何给定用例的理想数量都是不同的,且最好通过运行不同模型来决定。通常,2层被认为足够检测更加复杂的特征。层数多更好,但也更加难训练。作为一个通用的法则 -- 1个隐藏层用于简单的问题,像这样,两个足够找到相当复杂的特征。
在我们的例子中,增加第二层仅仅在10个 epoch 后将准确率改善了 ~0.2% (0.9801 vs. 0.9819)。
选择额外的超参数
模型中每个 LSTM 层都应该结合一个 Dropout 层,它会在训练阶段忽略随机选定的某些神经元的输出,以此减轻单独神经元对某些特定权重的敏感性,这将在一定程度上防止模型出现过拟合的现象。为了在保证模型准确率的情况下防止过拟合,我们通常将 deopout_rate 设置为 20% 。
在我们的 LSTM 层完成了将输入转化为对预期输出预测的过程后,将会产生一个输出,通常我们需要对 LSTM 的输出结果的 shape 进行调整,使之和我们预期的输出相对应。在这里,我们输出的 Label 有两类,因此我们需要一个带有两个输出的神经元。
模型的最后一层需要添加激活层(在 Keras 中将激活函数一看做一个 Layer)。从技术上来说,这一步可以整合进全连接层(即 Keras 的 Dense Layer)中,但是将其分开是有特定的原因的。尽管在这里不相关,还是稍微提及一下:将全连接层和激活函数层分离,使得我们可以得到模型全连接层的输出。激活函数的选择需要视具体的应用而定。对于我们目前的问题来说,我们有多个预测类别(男性和女性),但是对于一个实例来说只能是属于一个类别。对于这种问题而言, softmax activation function 是最好的选择,因为它使得我们(以及模型)能够应用概率来解释模型的输出。
损失函数和激活函数通常会一起选定。若使用 Softmax 激活函数的话,我们通常会选择 Cross-Entropy 损失函数,准确的来说是 Binary Cross-Entropy 损失函数,因为我们需要解决的是一个二元分类问题。这两个函数搭配使用会使得模型有不错的效果,因为 Cross-Entropy 损失函数抵消了 softmax 激活函数两端的饱和阶段( plateaus )对模型产生的影响,这样就可以加速神经网络的学习进程了。(译者注: 查看 softmax 激活函数图像可知,其图像的两端达到一种很平稳的状态,一般称作 “plateau”,在这个阶段函数变化很平缓,对应的导数趋近于 0 ,神经网络的反向传播难以进行,所以神经网络的学习速度会变得很慢,通过选择特定的损失函数可以一定程度上减轻这个问题。)
对于优化器的选择, Adaptive Moment Estimation 和 Short _Adam_ 优化器在很多实践应用中被证明是非常有效的,而且只要修改小部分超参数便可以完成模型的优化过程。最后同样需要考虑的是模型的评估指标。Keras 提供了 multiple accuracy functions。在很多情况中,使用整体的 准确率 来评估模型的性能通常是一个最简便的选择。
模型构建、训练及评估
在直观理解了如何选择模型重要参数之后,让我们把它们放在一起,开始训练我们的模型吧。
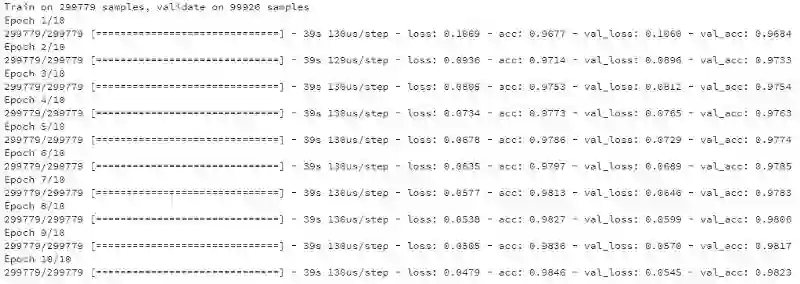
训练输出日志
从训练过程的日志中可以看出模型准确率达到了 98.2% ! 真是令人惊讶!当然仔细想一下,很可能是因为测试集中的名字在验证集中就出现过,所以才达到这么高的准确率。在这里,我们可以通过验证集合来查看预测错误的实例,做一下错误分析来不断调优我们的模型。

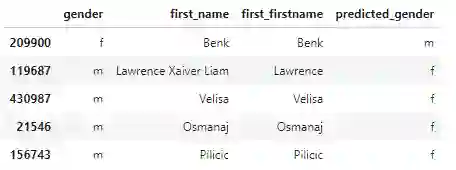
模型验证集输出
从部分结果来看,导致模型预测错误是因为一些人将名字的 姓氏 和 名字填反了。因此,下一步我们可以考虑将原始数据中这些实例去掉。现在,模型的预测结果看起来非常好了。对于这样高的准确率,这个模型以及可以用于很多真实场景来。当然,模型如果多训练几个 Epoch 没准还可以进一步提升准确率,但是需要特别注意模型在验证集合上的表现,防止出现过拟合。
最后的一点思考
在这篇文章中,我们成功的构建了一个小模型用来依据名字来预测对应的性别,并在给定的 德国(German) 姓氏数据集上达到了超过 98% 的准确率。尽管 Keras 使得我们不需要写很多复杂的深度学习算法代码,但是我们仍然需要对超参数进行选择。在一些情况下,比如激活函数的选择,我们能够依赖一些准则或者根据具体的问题来定。然而,在一些其他情况下,要达到最好的结果,往往需要不断的验证不同的超参数并对结果进行评估,这将是一个非常耗时的工作。
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
https://ai.yanxishe.com/page/TextTranslation/1313
AI研习社每日更新精彩内容,观看更多精彩内容:
盘点图像分类的窍门
深度学习目标检测算法综述
生成模型:基于单张图片找到物体位置
AutoML :无人驾驶机器学习模型设计自动化
等你来译:
如何在神经NLP处理中引用语义结构
你睡着了吗?不如起来给你的睡眠分个类吧!
高级DQNs:利用深度强化学习玩吃豆人游戏
深度强化学习新趋势:谷歌如何把好奇心引入强化学习智能体

2月2日至2月12日,AI求职百题斩之每日挑战限时升级,赶紧来答题吧!
0208期 答题须知
请在公众号菜单【每日一题】→【每日一题】进入,或发送【0208】即可答题并获取解析。

点击阅读原文,查看更多内容




