学界 | 百度提出冷聚变方法:使用语言模型训练Seq2Seq模型
选自arXiv
机器之心编译
参与:路雪、蒋思源
近日,百度研究院发表论文提出冷聚变(Cold Fusion)方法,即在 Seq2Seq 模型训练过程中加入语言模型,实现更快地收敛、更好的泛化,以及仅需少量标注数据即可实现向新域的完全迁移。机器之心对这篇论文进行了介绍。
论文地址:https://arxiv.org/abs/1708.06426

摘要:带有注意力机制的序列到序列(Seq2Seq)模型在多项生成自然语言句子的任务中表现优秀,如机器翻译、图像字幕生成和语音识别。在以语言模型的形式利用非标注数据后,其性能进一步提高。在本研究中,我们提供了一种冷聚变(Cold Fusion)方法,并展示该方法在语音识别中的有效性。我们展示了使用冷聚变方法的 Seq2Seq 模型能够更好地利用语言信息,并且能够实现(1)更快收敛、更好的泛化;(2)使用少于 10% 的标注数据进行训练时能几乎完成向新的域的完全迁移。
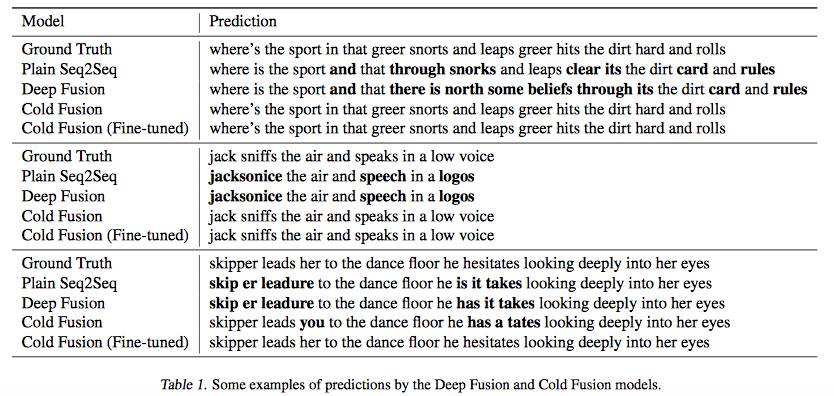
表 1. 深度聚变(Deep Fusion)和冷聚变的预测示例。
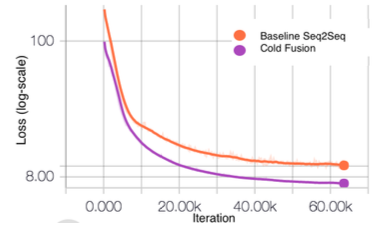
图 1. 基线模型(橙色)和我们提出的模型(紫色)在开发集上的交叉熵损失和迭代数之间的函数关系。使用语言模型的训练可以一定程度上加速收敛。
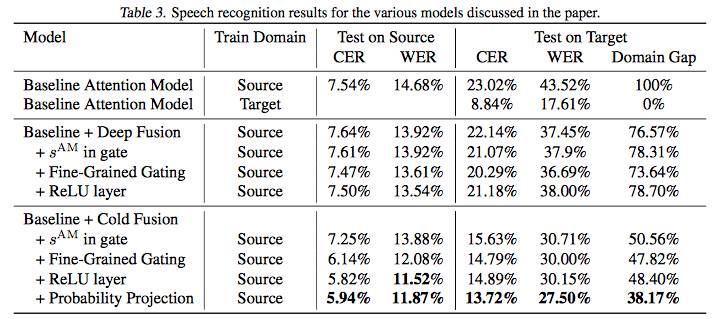
表 3. 论文中讨论的不同模型的语音识别结果。
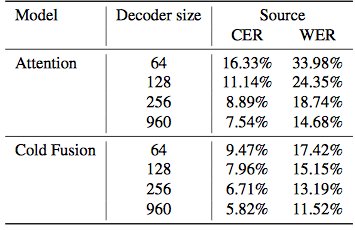
表 4. 解码器维度对该模型的性能影响。冷聚变模型的性能随着解码器变小而缓慢下降,这证明冷聚变模型的有效任务能力比无聚变的模型大得多。
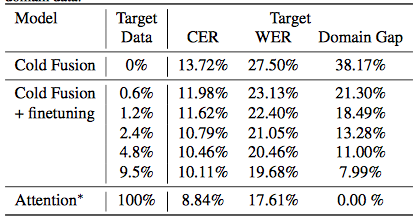
表 5. 微调后的声学模型在目标训练数据的子集上的结果。最后一行代表在所有目标域数据上进行训练的注意力模型。
结论
在该研究中,我们展示了一种新型 Seq2Seq 通用模型架构,其解码器和预训练的语言模型一起训练。我们研究并确认,架构变化对该模型充分利用语言模型中的信息至关重要,这也帮助模型实现更好地泛化;通过利用 RNN 语言模型,冷聚变模型产生的词错率比深度聚变模型低 18%。此外,我们证明冷聚变模型能够更轻松地迁移至新的域,仅需要 10% 的标注数据,即几乎可完全迁移至新的域。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


