AAAI 2022 | InsCLR:一种利用自监督训练提升实例检索的方法
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:Zelu Deng | 编辑:Amusi

InsCLR: Improving Instance Retrieval with Self-Supervision
论文:https://arxiv.org/abs/2112.01390
代码:https://github.com/zeludeng/insclr
实例检索是指给定一张包含某物体的图像(Query),然后从图像库(Index)中查找所有包含该物体的图像。目前实例检索任务常见的做法是,先利用有标注的数据结合分类损失,比如Arcface,进行训练,然后利用训练好的模型从图像中提取特征,利用特征计算相似性来得到与Query图像包含相同物体的Index图像。
本文的出发点是利用无标注的数据集进行训练,从而得到提取特征的模型。从整体来看,本文方法的核心是如何计算给定图像的正样本,其它的模块,比如w/o DA的Memory bank和Mini-batch selection,都旨在为挖掘正样本提供更加可靠的信息。从Ablation Study部分,Table 1中方法C和方法D的比较可以看出,挖掘的正样本可以极大地提升检索的效果,从65.2到73.1。
实验表明,在常见的Oxford和Paris数据集上,本文所提出的方法可以接近甚至超过部分有监督的方法,在GLDv2检索任务上,利用无标注的数据集,可以达到13.71的mAP@100,相应的ImageNet-pretrained和有监督训练的mAP@100分别为0.52和25.57。
所提方法
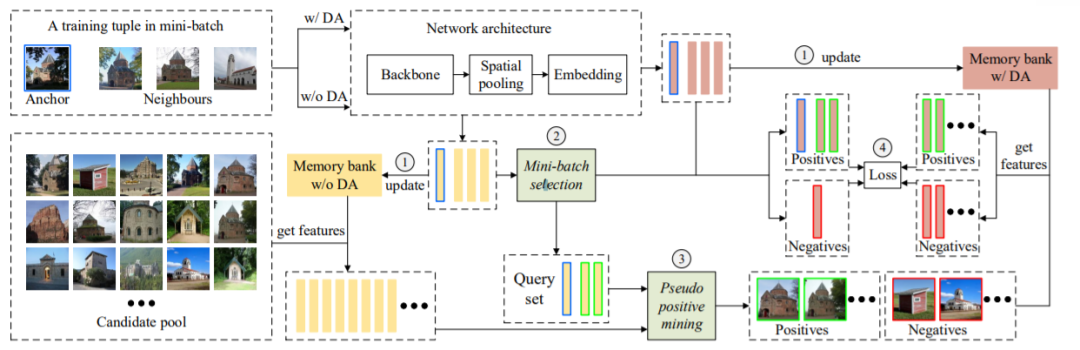
整个方法的流程如上图所示,包含如下四个步骤
-
提取特征后更新对应的Memory bank。 -
Mini-batch selection。 -
Pseudo positive mining。 -
计算损失更新参数。
首先是未在图中画出的训练前的准备工作:对于数据集中的每张图像,利用ImageNet-pretrained的模型提取特征,计算它与数据集其它所有图像的相似性,然后排序,最后将前 张图像作为该图像的候选集。我们假定,某图像的正样本只存在于它的候选集中,候选集外的图像都被认为是该图像的负样本,候选集的作用有两部分:第一,它使得挖掘正样本的开销可接受,第二,它为模型提供了Hard negative。
进一步介绍前,首先介绍训练元组的概念,训练元组是由一张图像(Anchor)以及它所对应的候选集中前 张图像构成的,我们暂且假定这 张图像具有相同的标签。此外,训练元组也对应了一个候选集,它是由训练元组中所有图像的候选集合并得到的(会经过去重等操作),我们将这个候选集称为训练元组候选集。
每次训练,首先随机选择 个训练元组,不同的训练元组具有不同的标签,随后,如图中左上部分所示,这64张图像会有两个版本,经过数据增强的(w/ DA)和没有经过数据增强的(w/o DA),这两种版本的图像都会经过模型得到特征,然后更新相应的Memory bank,如图中步骤1所示。w/ DA的Memory bank,其用法和XBM一样,用于损失计算。而w/o DA的Memory bank,其作用是图像间的相似性计算,相似性在Mini-batch selection和Pseudo positive mining中,是判断某图像是否是正样本的重要指标。使用w/o DA的Memory bank而不是w/ DA的,原因在于数据增强具有随机性,以此得到的相似性是不可靠的,实验也表明(论文部分图4),如果使用w/ DA的Memory bank计算相似性,效果会非常差。
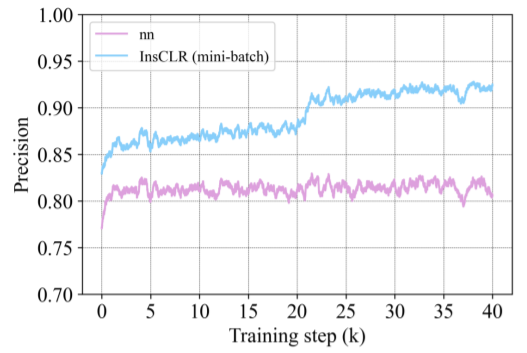
接下来,是对每个训练元组进行“过滤”,对应图中的步骤2 Mini-batch selection。从方法来说,Mini-batch selection是计算 张图像与Anchor图像的相似性,然后保留相似性大于阈值 的图像,相似性小于阈值 的图像作为Hard negative,注意经过Mini-batch selection后,训练元组候选集也要相应更新。从想法上来看,Mini-batch selection是出于对计算候选集的模型的不信任,随着训练的进行,模型也在不断地进化,因此相似性也会越来越可靠,从而利用此相似性更正正样本。附录的图6(如下)也证明了我们的观点:Mini-batch selection逐渐提升着训练元组内的Precision。
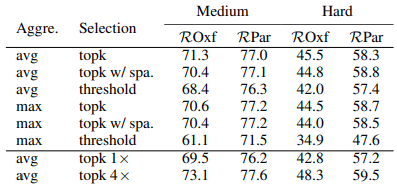
随后,是Pseudo positive mining的过程,对应图中的步骤3,该过程是利用“过滤”后的训练元组从训练元组候选集发掘正样本,它是一个迭代的过程。首先将查询集设置为“过滤”后的训练元组,然后计算查询集与候选集中每一张图像的得分,根据得分从候选集中挑选图像进入查询集。重复这个过程。在表2中(下图),我们比较了不同的得分计算方式和挑选策略,发现avg加topk 4x的效果最好。
最后是损失计算部分,这部分我们采用的是XBM中的方法。
实验效果
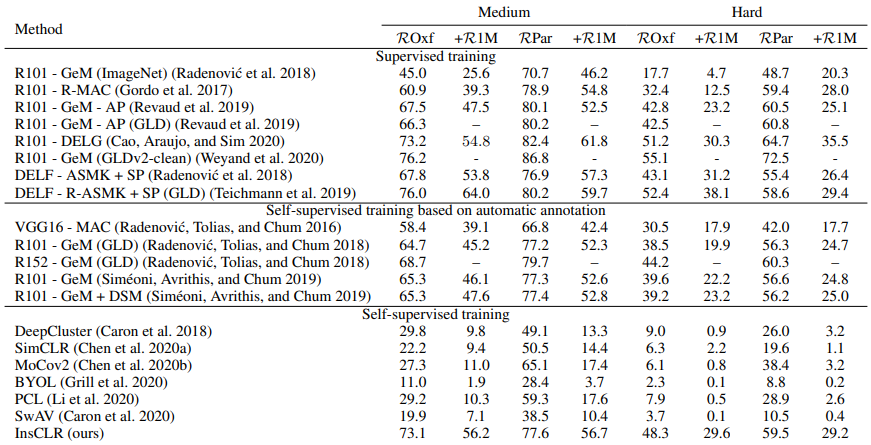
可以看到,在两个常见的实例检索数据集上,我们的方法已经超过了部分有监督的方法,而采用相同训练集的有监督方法R101 - GeM (GLDv2-clean),在某些指标上我们也与之比较接近。

在GLDv2 retrieval task上,我们的方法也展现了不错的性能。
未来方向
本文的核心是正样本的挖掘,而由于GLDv2数据集本身的特性:同一类的物体存在尺度、视角等差异,导致类内差异很大,如下图:

因此,仅用池化后的特征计算相似性选取的正样本,可能并不会包含尺度或视角差异过大的图像,因此,可以考虑结合Spatial verification(SP)的信息。比如在训练前计算每张图像的候选集时,利用SP对每张图像的候选集进行“精排”,或者在Mini-batch selection和Pseudo positive mining时也参考SP的结果。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号



