SLAM中VIO的优势及入门姿势
点“计算机视觉life”关注,置顶更快接收消息!
本文由作者游振兴(专注机器人行业及如何讨好女朋友),由泡泡机器人SLAM授权转载
点文末阅读原文可跳转至作者知乎原文
一、前言
这篇文章作为我的硕士期间学习总结,将从导航定位层面介绍SLAM技术,并给初学者一些学习建议。不会涉及非常深的理论方面的东西,初衷是重点说清楚SLAM方法的应用价值和学习方向,笔者认为这个对初学者更加重要。这篇文章假设读者已经了解了SLAM的基本概念。
文章中提到的部分参考资料,我整理了一份传到了网盘上:
链接:
https://pan.baidu.com/s/1gWqXH1cdvyeID3y7ktXOZQ
密码:1m34
二、为什么研究SLAM
最近几年我们见证了机器人领域的快速发展,大疆的无人机已经很好地实现智能化飞行,谷歌的自动驾驶出行服务已经在局部范围进行试运营,波士顿动力的Atlas机器人一个漂亮的后空翻甚至让多数业内人士为止惊叹,AR/VR技术也在定义新的人机交互方式。这些都离不开稳定可靠的定位导航技术。
2.1从机器人定位导航/状态估计说起
SLAM的输出是运动体状态+环境地图,所以研究SLAM会有两个不同的侧重点,侧重前者可以用于机器人定位导航,侧重后者则用于三维重建,这篇文章假设读者关注的是前者,将SLAM作为机器人定位导航(状态估计)的一种方法展开下面的内容。
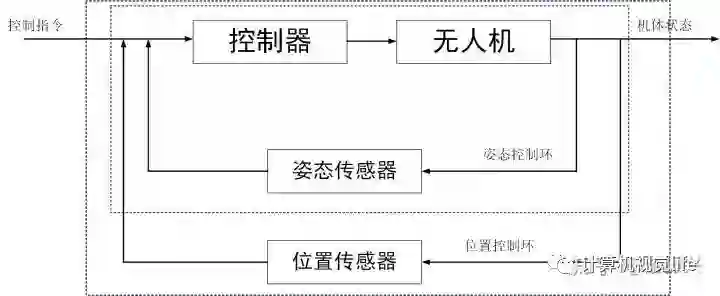
运动体可以抽象为空间中的刚体,它的状态可以使用六自由度(三轴位置、三轴姿态)进行描述。以无人机为例,对无人机的运动控制是通过内环姿态控制和外环位置控制实现的,内环控制实现了机体在空间中的基本运动,外环位置控制则是实现路径规划、航点飞行的基础。为了对无人机姿态进行控制,需要有姿态量的反馈,这个是通过IMU/AHRS传感器进行姿态解算实现的;同样,位置控制需要位置量的反馈,可以实现位置测量和估计的传感器有GPS、UWB、LiDAR、Camera。GPS和UWB是利用外部信号实现的定位,LIDAR和Camera则是利用SLAM算法实现位置估计。同时,控制理论中,速度量可以加快机体响应速度,也是一个非常重要的量,复杂的姿态和位置控制环路里一般会加入速度(角速度、线速度)控制。所以通常我们也会考虑速度的测量估计。
所以,如果事有兴趣将SLAM应用在机器人领域上,应该从机器人定位导航的层面上认识SLAM的地位,SLAM只是机器人定位导航的一种方法,不同传感器的不同特性使其适用于不同的场合,为了提高定位导航系统的可靠性稳定性,在实际中往往涉及多传感器融合。而SLAM方法进行定位导航的优势在于不需要外部先验信息,使用范围更广泛。
而且通过SLAM的学习,我们将学到定位导航需要的所有知识技能。下图是国内一家自动驾驶公司的招聘信息,我圈出了定位导航的职位要求。数学知识、滤波/优化方法、传感器融合,软件编程这些做机器人导航定位需要的知识技能,在SLAM的学习中都会涉及到。

2.2 SLAM在机器人领域的应用
前面已经说到,SLAM是机器人定位导航的一种方式,而且如果后端建图实现的是稠密地图,即获取到周围环境详细的深度信息,也是实现避障、路径规划的任务的基础。下图是港科沈绍劼老师团队利用VIO实现的无人机导航和单目稠密重建的工作。
(Autonomous aerial navigation using monocular visual-inertial fusion:https://www.bilibili.com/video/av10813325)
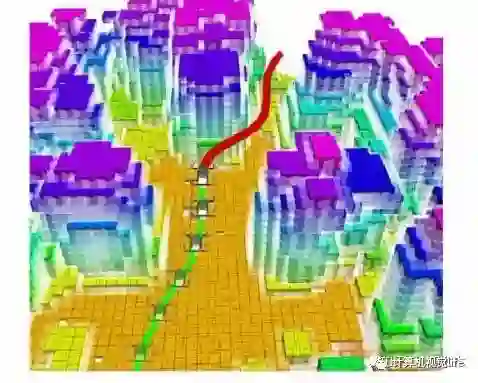
单目稠密重建地图进行无人机避障和路径规划
在自动驾驶里,一方面则是使用多传感器融合的方式提高定位系统的可靠性稳定性,这里面激光/视觉SLAM是其中一个重要的定位来源;另一方面在构建高精地图时,也会用到SLAM技术,高精地图被认为是实现自动驾驶的重要技术方案,使用地图采集车先构建出包含非常详细的环境细节的地图,在正常运行的自动驾驶车辆上则利用SLAM重定位技术从高精地图里获取定位信息。


2.3 SLAM在AR/VR领域的应用
从更广泛的意义上将, SLAM 技术实现了物体在空间中的定位,因此不仅仅在机器人领域, SLAM 可以应用在任何需要空间定位的场合。
AR(Augmented Reality) 增强现实技术是通过带有视觉传感器的设备实现在物理真实场景中添加虚拟信息,实现现实和虚拟场景的交互。如图,是Apple在 2017 年 推出的 ARKit在移动设备上实现的AR 效果示例,图中 ipad 显示通过后置摄像头拍摄的真实场景和虚拟场景叠加的效果,其中相机是真实的物体,咖啡杯和花瓶则是添加的虚拟物体,通过光线渲染等实现了很好的效果(使用者甚至无法区分出真实物体和虚拟物体)。举例说明 SLAM 技术在其中发挥的作用,当使用者通过 ipad 向 ipad 拍摄到的场景中添加虚拟信息,为了实现很好的逼真效果,第一步就是需要固定该虚拟物体相对真实环境中的位置,即 ipad 移动而视角发生变化时,虚拟物体和真实环境的相对位置不应该发生变化,而虚拟物体实际是存在于移动设备上的,换言之,我们需要精确估计出移动设备相对空间的位置变化。 ARKit 是通过VIO实现移动设备在空间中的精确定位。
VR(Virtual Reality) 虚拟现实技术则是通过虚拟现实头盔投射虚拟信息,给人身临其境的感觉,将使用者在实际空间中的移动反映到虚拟空间上可以很大程度地提高交互体验,通过追踪使用者佩戴头盔的位置可以实现这一效果,实现头盔空间定位的方式可以分为 Outside-in 方案和 Inside-out 方案,前者使用过外部辅助设备实现定位,后者则使用头盔自身传感器实现定位,显然后者的使用场景不受限制是一种更好的定位方式,而 Inside-out 定位目前被广泛采用的方案就是视觉惯性传感器融合实现 SLAM的 VINS 算法。
(凌感马赓宇:基于视觉+惯性传感器的空间定位方法:http://www.sohu.com/a/119892067_383098)
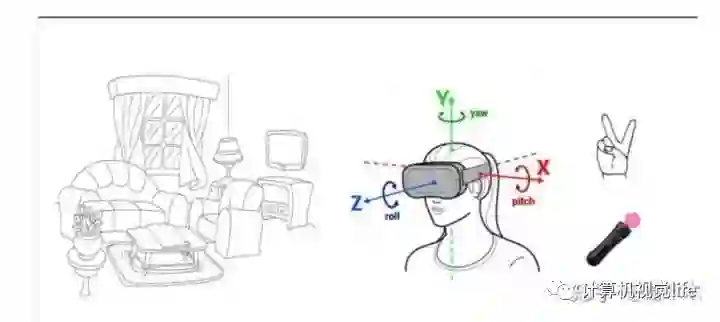
VIO用于VR头盔定位
2.4 VIO的优势
VIO(visual-inertial odometry)即视觉惯性里程计,有时也叫视觉惯性系统(VINS,visual-inertial system),是融合相机和IMU数据实现SLAM的算法,根据融合框架的区别又分为紧耦合和松耦合,松耦合中视觉运动估计和惯导运动估计系统是两个独立的模块,将每个模块的输出结果进行融合,而紧耦合则是使用两个传感器的原始数据共同估计一组变量,传感器噪声也是相互影响的,紧耦合算法上比较复杂,但充分利用了传感器数据,可以实现更好的效果,是目前研究的重点。
单目视觉 SLAM 算法存在一些本身框架无法克服的缺陷,首先是尺度的问题 ,单目 SLAM 处理的图像帧丢失了环境的深度信息,即使通过对极约束和三角化恢复了空间路标点的三维信息,但是这个过程的深度恢复的刻度是任意的,并不是实际的物理尺度,导致的结果就是单目SLAM 估计出的运动轨迹即使形状吻合但是尺寸大小却不是实际轨迹尺寸;由于基于视觉特征点进行三角化的精度和帧间位移是有关系的,当相机进行近似旋转运动的时候,三角化算法会退化导致特征点跟踪丢失,同时视觉 SLAM 一般采取第一帧作为世界坐标系,这样估计出的位姿是相对于第一帧图像的位姿,而不是相对于地球水平面 (世界坐标系) 的位姿,后者却是导航中真正需要的位姿,换言之,视觉方法估计的位姿不能和重力方向对齐。
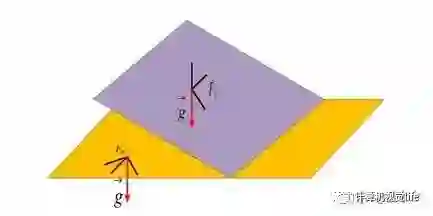
重力向量构建了视觉坐标系和世界坐标系的联系
通过引入 IMU 信息可以很好地解决上述问题,首先通过将 IMU 估计的位姿序列和相机估计的位姿序列对齐可以估计出相机轨迹的真实尺度,而且 IMU 可以很好地预测出图像帧的位姿以及上一时刻特征点在下帧图像的位置,提高特征跟踪算法匹配速度和应对快速旋转的算法鲁棒性,最后 IMU 中加速度计提供的重力向量可以将估计的位置转为实际导航需要的世界坐标系中。同时,智能手机等移动终端对 MEMS 器件和摄像头的大量需求大大降低了两种传感器的价格成本;硬件实现上, MEMS 器件也可以直接嵌入到摄像头电路板上。综合以上,融合 IMU 和视觉信息的 VINS 算法可以很大程度地提高单目 SLAM 算法性能,是一种低成本高性能的导航方案,在机器人、AR/VR 领域得到了很大的关注。
从另外一个角度理解视觉惯性融合的意义,我们一般采用运动方程和测量方程描述机器人的运动过程,具体到视觉惯性紧耦合运动估计问题,这里的第k 时刻的状态 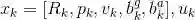
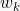

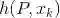
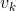
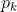
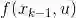
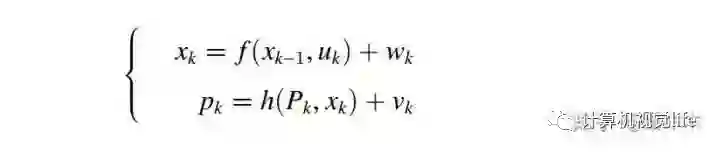
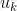

三、学习资源
3.1 书籍
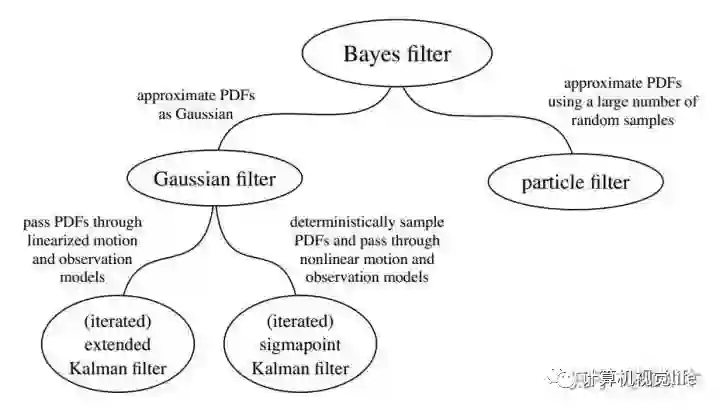
入门书籍推荐高博的《视觉SLAM十四讲》,这本书不仅涵盖了SLAM和状态估计相关的基本理论知识,而且高博给出了每个理论模块的编程实现,第一遍建议可以先不细推公式,把书浏览一遍了解主要内容,第二遍就可以动手跟着书一点点撸代码了。之后就可以学习目前主流的开源框架,在对SLAM有较深的了解和实践之后,建议读《state estimation for robotics》和《Multi View Geometry》,前者是介绍状态估计理论非常完备的一本书,举例来说,作者从机器人的运动和测量方程出发,根据马尔科夫假设和贝叶斯公式,将目前主流的滤波(EKF,UKF,PF)方法统一在贝叶斯估计的框架下。后者涵盖了SLAM视觉几何的所有理论知识。
《Lie groups, Lie algebras, projective geometry and optimization for 3D Geometry, Engineering and Computer Vision》。
推公式的时候发现矩阵白学了?宝宝不哭,这有一本《the Matrix CookBook》送给你。
3.2 VIO 开源框架
VIO目前实现比较好的有vinsmono,okvis,MSCKF。前两个是基于非线性优化的方案而且框架比较相似,后者是基于滤波优化的方案,也是Google Tango上使用的方法,MSCKF目前并没有开源,不过宾夕法尼亚的Kumar实验室18年有一个相似的工作,目前已经开源(https://github.com/KumarRobotics/msckf_vio)。此外还有ROVIO(https://github.com/ethz-asl/rovio)。值得注意的是,虽然在纯视觉SLAM中,学界已经公认基于非线性优化方法的SLAM方法效果要好于滤波的方法,但在VIO中,非线性优化和滤波方法目前还没有很明显的优劣之分。我的理解是结合相机和IMU两种传感器的信息,提供了对当前状态更多的观测,使得算法对历史观测之间约束信息的依赖降低,这也是为什么okvis、vinsmono采用滑动窗口法(global bundle adjustment和filter 的折中)也能取得很好效果的原因。
vinsmono的代码和论文比较一致,是目前大家学习参考比较多的开源框架。
VIO中,目前多采用流形空间上预积分的方法对IMU数据进行预处理,核心思路是在两帧之间计算IMU的帧间运动增量,在迭代优化时直接使用运动增量,提高计算效率。这部分参考论文《On-Manifold Preintegration for Real-Time Visual-Inertial Odometry》,整篇论文推导的思路是先推导出流形空间上的运动状态的表达公式,然后为了能够整合到最大后验估计的优化框架里,分离出运动表达式中的噪声项,使其近似满足高斯分布,之后推导了在bias变化时的运动估计值的更新方法。
前面有提到VIO用到了以IMU作为控制输入的运动方程,Joan Sola 写的《Quaternion kinematics for the error-state Kalman filter》对以IMU测量值为运动输入的运动方程的误差递进形式进行了详细推导,如果在vinsmono和okvis的运动递进方程的雅克比矩阵推导遇到困难,或者对四元数方法进行运动描述不了解,可以仔细阅读下这篇文章。文章对坐标系的locally和globally的解释也让人印象深刻。
VIO的初始化是系统工作非常关键的部分,这部分可以参考vinsmono以及ORB作者写的的VIO文章《Visual-Inertial Monocular SLAM with Map Reuse》。两篇文章思路比较相似,先是通过单目运动估计的方法获取多帧图像的位姿,然后以此为运动参考估计其他参数,整个过程和相机IMU标定比较相似。初始化主要完成三部分工作:1. 为非线性估计系统提供一个运动初值 2. 估计尺度、IMUbias 3. 估计重力向量在视觉坐标系下的投影向量,以此将视觉坐标系对齐到世界坐标系下。
vinsmono的代码中协方差矩阵递进公式采用的是中值积分的方法,推导思路和Joan Sola文章中的一致,具体推导可以参考https://www.zhihu.com/question/64381223/answer/255818747,此外有篇博客也对vinsmono的整体框架做了整理总结https://blog.csdn.net/u012871872/article/details/78128087。
vonsmono代码中的融合部分是非常值得学习参考的,但是代码中的视觉处理部分多是直接使用OPENCV的函数,而且代码风格是C++/C 混合的。所以推荐看下ORBSLAM的代码,首先编程实现非常规范,对编程学习有很大的参考价值,而且整个代码对opencv的依赖较低,视觉部分的特征提取,视觉运动估计,都是作者自己编程实现的,对理解视觉几何的实现有很好的帮助,泡泡有篇公开课对ORBSLAM的代码进行了梳理
https://pan.baidu.com/s/1c1QOoHM
密码: xfjd
网上相关的博客也很多。
3.3 相机-IMU标定
相机IMU标定的目的是获取两个传感器坐标系之间的空间关系和数据延迟,是VIO系统工作的前提工作。相机-IMU标定可以看成状态估计的逆过程,标定是通过标定板获取每个时刻的精确运动状态,计算出模型参数(坐标系间旋转位移、时间延迟、IMUbias),而运动估计则是在已知两个传感器坐标系间的模型参数,估计每个时刻的运动状态。
目前有现成的标定库可以使用
/kalibr/wiki/Camera-IMU-calibration(http://github.com/ethz-asl/kalibr/wiki/Camera-IMU-calibration)
我写了一个使用方法总结,在资源链接里。
此外,相机-IMU标定需要事先知道相机和IMU的内参;做SLAM中我们也经常需要对新的相机进行内参标定。推荐ROS自带相机标定工具
http://wiki.ros.org/camera_calibration
可以实现在线标定。使用方法我写了一个文档,在资源链接里。IMU内参即陀螺仪加速度计的噪声参数,Kalibr 也给了一些说明。
3.3 数据集
计算机视觉发展如此迅速,我觉得有两点是有促进作用的。其一是整个领域开源的思想,使得其他人不需要重复造轮子或者对一方面的工作可以很快的上手;另一点就是网上公开的数据集,这些采直实际物理环境的数据集一方面给了大家进行算法对比的标准,另一方面可以在缺少实验条件的情况下快速验证算法。
飞行数据集,目前使用比较多的是EUROC数据集,给出了几种场景下飞行平台采集到的双目图像,IMU数据以及VICON提供的运动基准值。
无人车的数据集,最流行的当数KITTI(http://www.cvlibs.net/datasets/kitti/)
定位误差有ATE和RPE两种评测指标,TUM给了评测估计值和基准值误差Python脚本
https://vision.in.tum.de/data/datasets/rgbd-dataset/tools#evaluation
而且对两种误差的解释,TUM的评测脚本是假设估计轨迹和真实轨迹都是实际物理尺度的。ORB作者改写了一个自动缩放尺度的脚本
http://github.com/raulmur/evaluate_ate_scale
可以用来评测单目SLAM运动估计效果。
3.4 工具软件
C++是做SLAM的主流编程语言,需要重点掌握,也是很多公司非常重视的技能,C++学习可以参考北大的C++公开课:
https://www.coursera.org/learn/cpp-chengxu-sheji/home/welcome
配合着网站给出的作业一起搞。Pyhton的基本语法比较简单,网上介绍的资料比较多,Python中的Matplotlib可以很方便的替代Matlab 进行数据分析的事情,
Linux 下的C++、Python开发环境推荐Clion和PyCahrm,两款软件是同一个公司出的,学生可以利用edu邮箱在官网上申请免费使用。
Cmake是目前主流的C++工程构建方法,可以参考《Cmake Practice》。
在进行软件版本更新之间,是不是经常需要进行备份?有时候新写的代码崩溃又需要返回到之前的版本。Git 可以高效的完成这件事情(而且能做的不止这些),这种高效的开发工具你值得拥有。见网易云课堂:Git实用教程
同时,需要对Linux系统有一些宏观了解,并掌握基本的命令,学习资源推荐一网易云课堂:Linux 入门基础 ,讲解的非常清晰。
ROS的资料推荐官网的wiki,网上也有很多介绍的博客。
时常进行知识整理对我们学习会有很好的促进作用,常用的云笔记本有为知笔记,有道笔记等,使用markdown语法可以很方便的写出一篇排版比较清晰的笔记。笔者用的是为知笔记,支持Markdown和LaTeX语法,更重要的是可以在Linux上使用(不过最近版本更新,Linux版本一直登陆出错,囧)。
本文版权属于公众号:泡泡机器人SLAM,如需转载请联系
liufuqiang_robot@hotmail.com
相关文章
从零开始一起学习SLAM | 不推公式,如何真正理解对极约束?
从零开始一起学习SLAM | 理解图优化,一步步带你看懂g2o代码
深度学习遇到SLAM | 如何评价基于深度学习的DeepVO,VINet,VidLoc?

欢迎关注公众号:计算机视觉life,一起探索计算机视觉新世界~
好文!给个好看啦~