搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了(十七)

极市导读
本文介绍这个工作来自谷歌,本工作认为:Transformer 这种结构在 CV 和 NLP 任务上表现良好并不代表仅仅由 Self-attention 机制构成的网络也能够表现良好。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
37 只使用纯粹的注意力机制就够了吗 (ICML 2021)
(来自谷歌,EPFL)
37.1 Attention is not all you need 原理分析
37.2 Attention is not all you need 代码解读
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
本文介绍这个工作来自谷歌,Attention is not all you need 这篇文章为网络架构中含有 attention 结构的模型提供了一个新的看法,这篇工作认为:Transformer 这种结构在 CV 和 NLP 任务上表现良好并不代表仅仅由 Self-attention 机制构成的网络 (即去掉 MLP 层,残差连接,Layer Normalziation 等等) 也能够表现良好。
本文证明了一件事:
随着输入在网络中向前传播,深度不断加深,仅仅由 Self-attention 机制构成的网络 (即去掉 MLP 层,残差连接,Layer Normalziation 等等) 的表达能力会逐渐降低。最终,输出会退化成一个秩为1的矩阵,每一排的值变得一致。这个问题,本文把它称为 Rank Collapse。而Transformer中的其他构件 (即 MLP 层,残差连接,Layer Normalziation 等等) 可以缓解这个问题。比如,Shortcut 操作和 MLP 在缓解 Rank Collapse 问题上起了关键作用。
1 新的路径分解方法来研究 Self-attention 网络
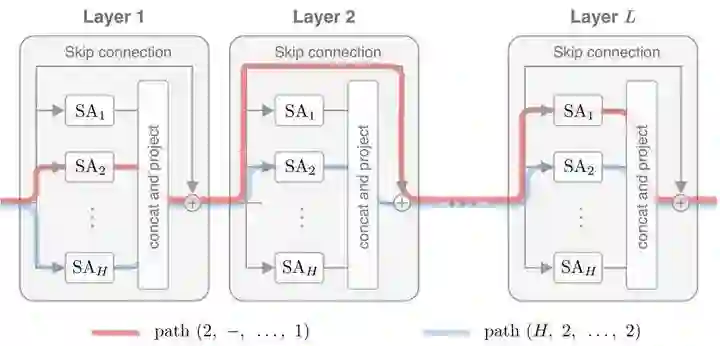
作者提出了一种新的路径分解方法来研究 Self-attention 网络,如下图1所示。路径分解方法将一个 Self-attention 网络视为不同的通路组成。在每1层,一条路径可以通过1个head或者跳过1个layer (因为有 Shortcut 连接)。在每个 attention layer 之后,追加 MLP 块,就构成了 Transformer的架构。把一个 Self-attention,分解为一个若干 "弱相互依赖" 的路径的线性组合,其中每个路径对应一个单 head 的 Self-attention。
或者说,增加了一个 dummy head,一个路径,会选择已有的 heads + dummy head中的任何一个 head 去通过:如果选择了已有的 heads (例如 个 head 中的某一个) ,那就是通过网关,如果选择了 "dummy head",那就是越过了当前 layer。
注释: 本文使用了一种特殊的范数,叫做 混合范数。比如矩阵 满足 ,注意到 其实并不是一种真正的范数,因为范数的三大条件是:
-
正定性,即 且当 时必有 。 -
齐次性,即 。 -
三角不等式,即 。
所以严格来讲 其实并不属于一种范数,因为 不满足三角不等式。
其他简写符号: 。
第1步是证明:一个只由 Self-attention 模块构成的网络的输出 (矩阵) 随深度的增加,其 Rank 呈指数衰减,最终会趋向于一个1秩矩阵,即所有 token 都一样。 当有100层,1000层,10000层。。。SANs 的时候,最终的每个词的向量表示都一样了?
假设 是输入矩阵,它包含有 个tokens,每个 token (单词) 用 维度表示。模型包含 层 MHSA , 即多头自注意力层。每个 MHSA 包含 个 head。则第 个 head 的 MHSA 的输出可以写成:
式中, 是 Value matrix。 是 attention map,按照下式来计算:
上式就是标准的 Self-attention 的实现方式。其中, 。
每一层的输出是将所有注意力头的输出 (沿着最后一个维度) concat 起来,并线性投影到一个适当大小的子空间上:
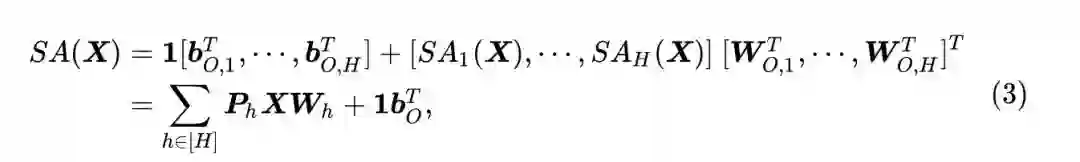
其中, 。每一层都有相同数量的 head 。 是第 层 的输出。 。
SAN 的输出可以根据3式表示为:
展开递归,得到:
2 SAN 的路径分解
深度为 ,且有 个 head 的 self-attention 网络每一层的输出为:
式中, 是个依赖输入的转移矩阵。而 和 是不依赖于输入的变量。
对于任意的转移矩阵 ,有: 。
6式可以看成是 个长度为 的路径:
转移矩阵 可以完成 tokens 之间的混合。
下面作者证明每一条路径都会逐渐收敛到一个 1秩矩阵 (rank-1 matrix)。有趣的是,这种聚合作用在增加更多的层时是没有帮助的。尽管路径的数量是指数增加的,但每条路径都是双指数衰减的,并且导致了一个 rank-1 的输出。
3 SAN 的收敛性
接下来会介绍几个 Lemma,分别证明在:
-
single-head, single-layer -
multiple-heads, single-layer -
single-head, multiple-layers -
multiple-heads, multiple-layers
这四种情况下,下面的这个残差是如何变化的。
Lemma A.1 (single-head, single-layer):
即,残差遵循:
Lemma A.1 证明:
unscaled attention 的权重值可以这样计算:
根据 softmax 的平移不变性,有:
式中, 。
使用速记表示: 。
scaled attention 的权重值就可以写成:
因为上式的第1项的任意一行里面的每一列的值是相同的,所以满足 softmax 的平移不变性[1]。所以第1项可以安全地去掉。所以我们有:
式中, 。
令 ,则注意力权重重新加权的输入为:
其中第4行的不等式来自下面的 Lamma A.2,且根据 Lamma A.2, 满足条件:
同样有: 。
因为 self-attention layer 的输出是: ,所以有:
式中, 。
现在我们对不等式的右侧做约束,有:
这一项的成立来自赫尔德不等式 (Holder's inequality) 以及 。
把式 P.6 代入式 P.7 得:
根据 P.7 式还可以得到:
根据 P.8,P.9 式的这2个范数有,两式相乘后开根号有:
Lemma A.1 得证。
Lamma A.2 (A technical lemma):
假设 是与 相关联的行随机矩阵, 是与 相关联的行随机矩阵,则:
式中, 是对角矩阵, 且有: 。
Lemma A.2 证明:
首先从行随机矩阵的定义开始:
由于 ,所以 和 之间的关系为:
通过泰勒展开,可以进一步放缩到:
Lemma A.2 得证。
Lemma A.3 (multiple-heads, single-layer):
对于任何包含 个 heads 的 SAN 来讲有:
式中, 。
Lemma A.3 证明:
multi-head attention layer 的输出可以表示为:
式中, 。
因为 multi-head attention layer 的输出是: ,所以有:
式中,
对式 P.14 应用三角不等式,得到 混合范数:
根据 P.15,P.16 式的这2个范数,两式相乘后开根号,按照 Lemma A.1 的后续步骤即得到 Lemma A.3。
Lemma A.3 得证。
Lemma A.4 (single-head, multiple-layers):
对于任何包含 层的 single-head SAN 来讲,有:
Lemma A.4 证明:
将递归从最后一层向后展开到第一层,并应用引理 Lemma A.1,得到:
Lemma A.4 得证。
Lemma A.5 (multiple-heads, multiple-layers):
对于任何包含 层和 个 heads 的 SAN 来讲,有:
式中, 。
Lemma A.5 证明:
Lemma A.5 的证明思路与 Lemma A.2 一致,此处省略。
Lemma A.5 得证。
4 的变化规律
通过以上 Lemma A.1-A.5,我们特别关注 会如何变化:
对于任何包含 层和 个 heads 的 SAN 来讲,如果满足 ,则随着网络的加深,相当于 双指数收敛到一个1秩矩阵。
我们解释一下 P.19 式的含义:
首先 代表的是输入的 这个张量和一个1秩矩阵 的差距有多大。
那么 越小,则代表 这个张量和一个1秩矩阵 的差距就越小。
当满足 时,括号里面的值小于1,则 会逐渐收敛,也就是说:在更深的层, 这个输入张量和一个1秩矩阵 的差距会很小,即:特征收敛到了1秩矩阵。
这种特征收敛到1秩矩阵的现象,作者称之为:秩崩塌
既然 Transformer 模型会出现秩崩塌的现象,但是为什么实际应用中还可以获得良好的训练呢?作者研究了一下3个角色的作用:Skip-Connections,Multi-Layer Perceptrons (MLP),Layer Normalization。
5 抑制秩崩塌现象的方法:skip-connection 很重要
Corollary A.1 (SAN with skip-connections):
对于任何包含 层和 个 heads 的,带有 Skip-Connection 的 SAN 来讲,假设有: ,所有的 heads ,所有的 layers ,输出的界限是:
不会导致秩崩塌现象。
Corollary A.1 证明:
对于带有 Skip-Connection 的 SAN 来讲,Lemma A.1 中的 single-head, single-layer 现在变成了:
为了得到一个 multi-layer bound,我们向后展开递归。
我们首先考虑一个单头模型,并且有: ,我们得到:
下面我们将递归从最后一层向后展开到第一层,在展开的第 个 step 时, P.22 式中两项的最大值要么是 ,要么是 。假设网络深度为 ,有 次是前者最大。注意选择的顺序并不重要,重要的是被选择的次数。因此有:
将式 P.23 拓展到有 个 heads 的情况:
Corollary A.1 得证。
Skip-Connection 操作使得通过路径分解,总有一条路径跳过所有层,即总存在长度为0的路径。Skip-Connection 操作使得 不会收敛,即不会导致秩崩塌现象。
6 抑制秩崩塌现象的方法:MLP 有一定帮助
这一节研究 MLP 的作用,MLP 可以写成下式:
Corollary A.2 (SAN with MLPs):
对于任何包含 层和 个 heads 的,带有 Skip-Connection 的 SAN 来讲,假设有: ,所有的 heads ,所有的 layers , 的 Lipschitz constant 是 ,则输出的界限是:
不会导致秩崩塌现象。
Corollary A.2 证明:
证明思路和 Lemma A.3 的证明很相似,根据 P.14,P.15 式有:
对式 P.28 应用三角不等式,得到 范数:
因为有 MLP 层的作用, 通过 MLP 层之后的 boundary 会发生变化:
类似式 P.7,对式 P.30 应用赫尔德不等式 (Holder's inequality) 和三角不等式得到:
根据式 P.6 有:
代入 P.31,P.30 之后,有:
最后, 递归展开 boundary,有:
Corollary A.2 得证。
MLP 操作也可以使得 收敛,即也会导致秩崩塌现象。但是由于 的作用收敛速度会减慢。 越大,收敛速度就越慢。应该强调,使用 MLPs 来抵消秩崩溃并不是没有缺点:增加 Lipschitz 常数会减慢残差收敛速度,同时也会降低模型对输入扰动的敏感性和鲁棒性。更大的 Lipschitz 常数也可能对优化提出更大的挑战,因为会导致更大的梯度方差。
7 抑制秩崩塌现象的方法:Layer Normalization 没有用
Layer Normalization 是对输出特征进行 shifting 和 rescaling 操作,如下式所示:
式中, 是 每一列的均值。 是对角矩阵, 每个值代表 每一列 的标准差。
令 ,上式可以写成:
虽然 和 都是依赖与输入的变量,但是式 P.35 依然能够等效成没有 LN 的形式,所以 Layer Normalization 对抑制秩崩塌现象不起作用。
总结
本文分为两部分。
第1部分通过 5个 Lemma 证明了在 single-head, single-layer,multiple-heads, single-layer,single-head, multiple-layers,multiple-heads, multiple-layers 这四种情况下,残差 是如何变化的。发现 都会逐步收敛到0,即在更深的层, 这个输入张量和一个1秩矩阵 的差距会很小,即:特征收敛到了1秩矩阵。这种特征收敛到1秩矩阵的现象,作者称之为秩崩塌。
第2部分说明了既然 Transformer 模型会出现秩崩塌的现象,但是为什么实际应用中还可以获得良好的训练呢?作者研究了一下3个角色的作用:Skip-Connections,Multi-Layer Perceptrons (MLP),Layer Normalization。通过证明发现:Skip-Connections,Multi-Layer Perceptrons (MLP) 可以起到抑制秩崩塌的效果,而 Layer Normalization 对抑制秩崩塌不起作用。
参考
[1] Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. Multi-head attention: Collaborate instead of concatenate. 2020.
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选






