搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了(二十)

极市导读
本文介绍这篇文章是 Swin Transformer 系列的升级版 Swin Transformer v2。除此以外,本文一并介绍 Swin MLP 的代码实现,Swin Transformer 作者们在已有模型的基础上实现了 Swin MLP 模型,证明了 Window-based attention 对于 MLP 模型的有效性。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
39 Swin Transformer v2: 扩展容量和分辨率
(来自 微软亚研院,中科大)
39.1 Swin Transformer v2 原理分析
39.2 Swin MLP 代码解读
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
本文介绍这篇文章是 Swin Transformer 系列的升级版 Swin Transformer v2。Swin Transformer 是屠榜各大CV任务的通用视觉Transformer模型,它在图像分类、目标检测、分割上全面超越 SOTA,在语义分割任务中在 ADE20K 上刷到 53.5 mIoU,超过之前 SOTA 大概 4.5 mIoU!可能是CNN的完美替代方案。除此之外,本文一并介绍 Swin MLP 的代码实现,Swin Transformer 作者们在已有模型的基础上实现了 Swin MLP 模型,证明了 Window-based attention 对于 MLP 模型的有效性。
Swin Transformer Block 有两种,大致结构和 Transformer Block 一致,只是内部 attention 模块分别是 Window-based MSA 和 Shifted Window-based MSA。Window-based MSA 不同于普通的 MSA,它在一个个 window 里面去计算 self-attention,计算量与序列长度 成线性关系。Window-based MSA 虽然大幅节约了计算量,但是牺牲了 windows 之间关系的建模,不重合的 Window 之间缺乏信息交流影响了模型的表征能力。Shifted Window-based MSA 就是为了解决这个问题。将下一层 Swin Transformer Block 的 Window 位置进行移动,得到不重合的 patch。
在 Swin Transformer 的基础上,研究人员进一步开发出了用于底层复原任务的 SwinIR,Swin Transformer 和 SwinIR 的解读如下:
https://zhuanlan.zhihu.com/p/404001918
本文讲解 Swin Transformer V2 的原理。Swin Transformer V2 应该基于 DeepSpeed 框架,但是暂时还没有开源,所以本文另外讲解 Swin 在 Vision MLP 模型上的官方实现:Swin MLP 的代码。
39 Swin Transformer v2: 扩展容量和分辨率
论文名称:Swin Transformer V2: Scaling Up Capacity and Resolution
论文地址:
https://arxiv.org/pdf/2111.09883.pdf
39.1 Swin Transformer v2 原理分析:
Swin Transformer 提出了一种针对视觉任务的通用的 Transformer 架构,MSRA 进一步打造了一个包含3 billion 个参数,且允许输入分辨率达到1560×1560的大型 Swin Transformer,称之为 SwinV2。它在多个基准数据集 (包含 ImageNet 分类、COCO 检测、ADE20K 语义分割以及Kinetics-400 动作分类) 上取得新记录,分别是 ImageNet 图像分类84.0% Top-1 accuracy,COCO 目标检测63.1/54.4 box / mask mAP,ADE20K 语义分割59.9mIoU,Kinetics-400视频动作识别86.8% Top-1 accuracy。
Swin Transformer v2 的核心目的是把 Swin Transformer 模型做大,做成类似 BERT large 那样包含 340M 参数的预训练大模型。在 NLP 中,有的预训练的大模型,比如 Megatron-Turing-530B 或者 Switch-Transformer-1.6T,参数量分别达到了530 billion 或者1.6 trillion。
另一方面,视觉大模型的发展却滞后了。Vision Transformer 的大模型目前也只是达到了1-2 billion 的参数量,且只支持图像识别任务。部分原因是因为在训练和部署方面存在以下困难:
-
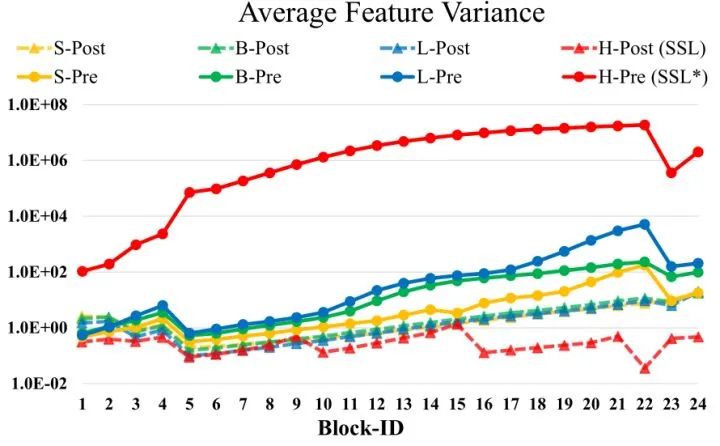
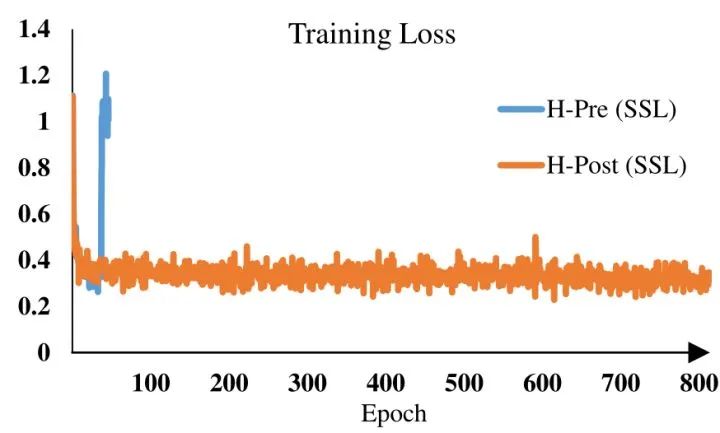
问题1: 训练中的不稳定性问题。在大型模型中,跨层激活函数输出的幅值的差异变得更大。激活值是逐层累积的,因此深层的幅值明显大于浅层的幅值。如下图1所示是扩大模型容量时的不稳定问题。当我们将原来的 Swin Transformer 模型从小模型放大到大模型时,深层的 activation 值急剧增加。最高和最低幅值之间的差异达到了104。当我们进一步扩展到一个巨大的规模 (658M 参数) 时,它不能完成训练,如图2所示。
-
问题2: 许多下游视觉任务需要高分辨率的图像或窗口,预训练模型时是在低分辨率下进行的,而 fine-tuning 是在高分辨率下进行的。针对分辨率不同的问题传统的做法是把位置编码进行双线性插值 (bi-cubic interpolation),这种做法是次优的。如下图3所示是不同位置编码方式性能的比较,当我们 直接在较大的图像分辨率和窗口大小测试预训练的 Imagenet-1k 模型 (分辨率256×256,window siez=8×8) 时,发现精度显著下降。

-
问题3: 当图像分辨率较高时,GPU 内存消耗也是一个问题。
为了解决以上几点问题,作者提出了:
-
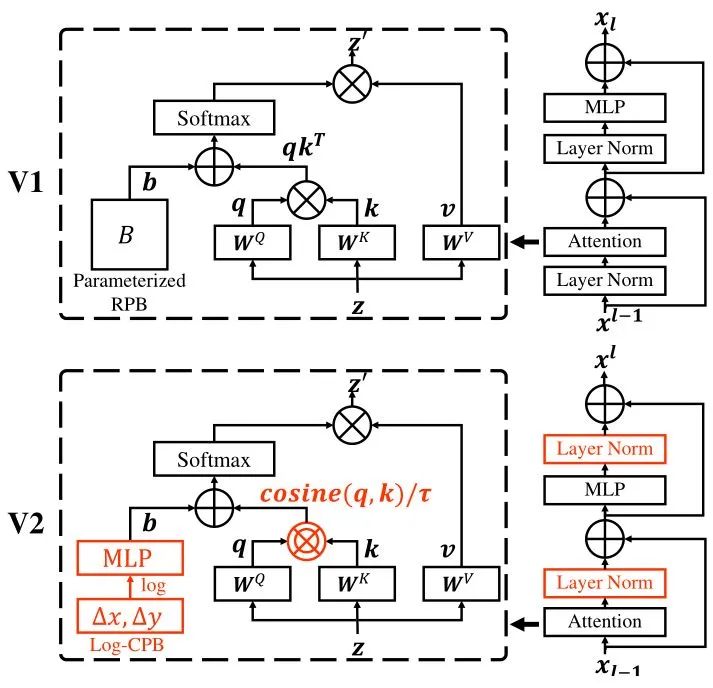
方法1:post normalization 技术:解决训练中的不稳定性问题。
把 Layer Normalization 层放在 Attention 或者 MLP 的后面。这样每个残差块的输出变化不至于太大,因为主分支和残差分支都是 LN 层的输出,有 LN 归一化作用的限制。如上图1所示,这种做法使得每一层的输出值基本上相差不大。在最大的模型训练中,作者每经过6个 Transformer Block,就在主支路上增加了一层 LN,以进一步稳定训练和输出幅值。
-
方法2:scaled cosine attention 技术:解决训练中的不稳定性问题。
原来的 self-attention 计算中,query 和 key 之间的相似性通过 dot-product 来衡量,作者发现这样学习到的 attention map 往往被少数像素对所支配。所以把 dot-product 改成了 cosine 函数,通过它来衡量 query 和 key 之间的相似性。
式中, 是下面讲得相对位置编码, 是可学习参数。余弦函数是 naturally normalized,因此可以有较温和的注意力值。
-
方法3:对数连续位置编码技术: 解决分辨率变化导致的位置编码维度不一致问题。该方法可以更平滑地传递在低分辨率下预先训练好的模型权值,以处理高分辨率的模型权值。
我们首先复习下 Swin Transformer 的相对位置编码技术。
式中, 是每个 head 的相对位置偏差项 (relative position bias), 是 window-based attention 的 query,key 和 value。 是 window 的大小。
附:Swin Transformer 的位置编码方法详解
注意 Swin Transformer 的位置编码是加在 attention 矩阵上的,attention 是个四维张量,它的维度是:
为了表述的方便,下文我们取 num_heads = 1,window_size = (3,3)。Swin Transformer 的位置编码的原理,原文讲得不是非常清楚,网上博客也没有谈及原文设计的根本原因,今天在这里我们用几张图表示。
首先我们看一个 window:
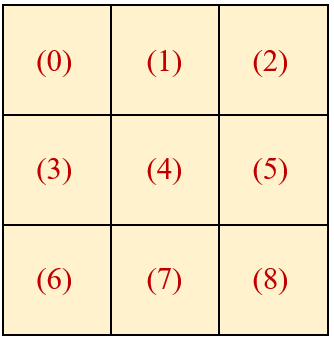
这里面有9个patch。
注意 Swin Transformer 的位置编码 是加在 Attention 矩阵上的,也就是说位置编码后面2维必然是个9×9的矩阵,那么这个9×9的矩阵的含义是什么?
比如位置编码 的第 个元素 ,它代表的是 Window 里面第 个 Patch 和第 个 Patch 的相对位置关系。
比如 ,它代表的是 Window 里面第 个 Patch 和第 个 Patch 的相对位置关系,也就如下图6所示。再比如 ,它代表的是 Window 里面第 个 Patch 和第 个 Patch 的相对位置关系,也就如下图7所示。 代表着斜对角的位置关系; 代表着斜对角的位置关系。
所以应该有 ,因为它们都代表着斜对角的位置关系。
所以应该有 ,因为它们都代表着上下有间隔的位置关系。
等等。
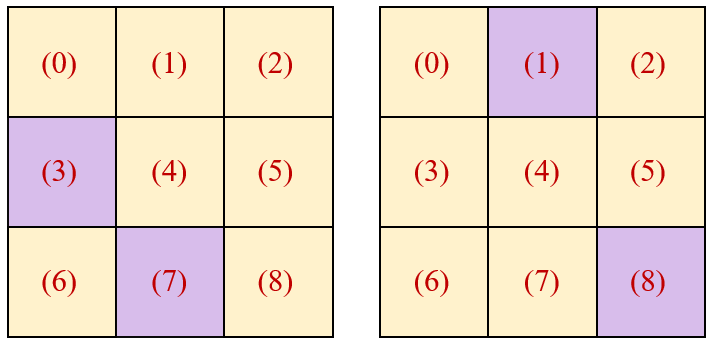
所以最终得到的位置编码应该如图7所示,图7中相同的数字代表此处位置编码应该一样。容易验证图7满足:
, 。
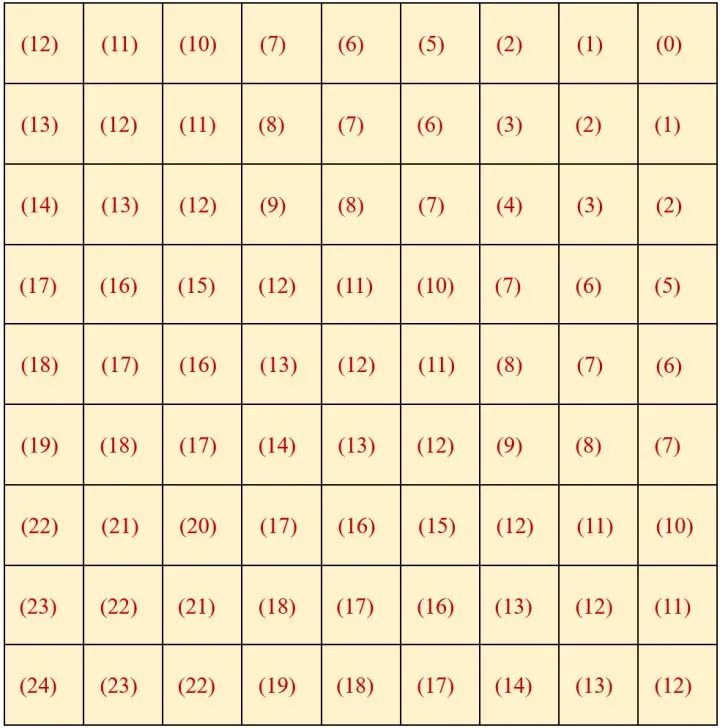
那现在的问题就是如何得到 了。得到 里面的值稍微有点复杂,我们通过代码进一步了解:
下面这段代码是 Swin Transformer 代码中的相对位置编码部分。为了表述的方便,我们取 num_heads = 1,window_size = (3,3)。
num_heads = 1
window_size = (3,3)
首先建立一个相对位置编码表 relative_position_bias_table ,是 nn.Parameter 类型,里面一共有 (2M-1)(2M-1)=25 个值。注意为什么是 (2M-1)(2M-1) 个不同的值稍后会解释。
relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
下面是得到相对位置索引:
coords_h = torch.arange(window_size[0])
coords_w = torch.arange(window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += window_size[1] - 1
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
输出的是 relative_position_index 是:
tensor([12, 11, 10, 7, 6, 5, 2, 1, 0, 13, 12, 11, 8, 7, 6, 3, 2, 1,
14, 13, 12, 9, 8, 7, 4, 3, 2, 17, 16, 15, 12, 11, 10, 7, 6, 5,
18, 17, 16, 13, 12, 11, 8, 7, 6, 19, 18, 17, 14, 13, 12, 9, 8, 7,
22, 21, 20, 17, 16, 15, 12, 11, 10, 23, 22, 21, 18, 17, 16, 13, 12, 11,
24, 23, 22, 19, 18, 17, 14, 13, 12])
刚好有 (2M-1)(2M-1)=25 个值。
所以相对位置编码表 relative_position_bias_table 里面需要有25个值,即 。 中的值按照 relative_position_index 从 relative_position_bias_table 里面取出后再与 attention 相加:
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
预训练学习到的相对位置偏差矩阵,在下游任务上进行 fine-tuning 时,由于输入分辨率变化,window size 也有可能变化,导致无法直接迁移过来,Swin 的做法和 ViT 一致,采用双线性插值 (bi-cubic interpolation),这种做法是次优的。
作者引入对数空间连续位置偏差 (log-spaced continuous position bias),使相对位置偏差在不同的 window 分辨率之下可以较为平滑地过渡。
把上面的 relative_position_bias_table 记作 "parameterized biases",作者的新方法不是直接优化 parameterized biases,而是采用了一个小的 meta network (2层 MLP,带有 ReLU 激活函数) 来生成 parameterized biases:
当输入分辨率发生变化时,window size 也会变化,作者采用对数空间的相对位置坐标:
其中, , 是线性空间的坐标; , 是对数空间的坐标。
比如预训练任务的 window size = 8×8,Fine-tuning 任务的 window size = 16×16。
使用原始坐标的话,相对位置的范围将从 变化到 。外推比是 。
使用原始坐标的话,相对位置的范围将从 变化到 。外推比是 ,比原来减小了4倍。
方法4:节省 GPU memory 的方法:
1 Zero-Redundancy Optimizer (ZeRO) 技术:
来自论文:Zero: Memory optimizations toward training trillion parameter models
传统的数据并行训练方法 (如 DDP) 会把模型 broadcast 到每个 GPU 里面,这对于大型模型来讲非常不友好,比如参数量为 3,000M=3B 的大模型来讲,若使用 AdamW optimizer,32为的浮点数,就会占用 48G 的 GPU memory。通过使用 ZeRO optimizer, 将模型参数和相应的优化状态划分并分布到多个 GPU 中,从而大大降低了内存消耗。训练时使用 DeepSpeed framework,ZeRO stage-1 option。
2 Activation check-pointing 技术:
来自论文:Training deep nets with sublinear memory cost
Transformer 层中的特征映射也消耗了大量的 GPU 内存,在 image 和 window 分辨率较高的情况下会成为一个瓶颈。这个优化最多可以减少30%的训练速度。
3 Sequential self-attention computation 技术:
在非常大的分辨率下训练大模型时,如分辨率为1535×1536,window size=32×32时,在使用了上述两种优化策略之后,对于常规的 GPU (40GB 的内存)来说,仍然是无法承受的。作者发现在这种情况下,self-attention 模块构成了瓶颈。为了解决这个问题,作者实现了一个 sequential 的 self-attention 计算,而不是使用以前的批处理计算方法。这种优化在前两个阶段应用于各层,并且对整体的训练速度有一定的提升。
在这项工作中,作者还一方面适度放大 ImageNet-22k 数据集5倍,达到7000万张带有噪声标签的图像。还采用了一种自监督学习的方法来更好地利用这些数据。通过结合这两种策略,作者训练了一个30亿参数的强大的 Swin Transformer 模型刷新了多个基准数据集的指标,并能够将输入分辨率提升至1536×1536 (Nvidia A100-40G GPUs)。此外,作者还分享了一些 SwinV2 的关键实现细节,这些细节导致了 GPU 内存消耗的显著节省,从而使得使用常规 GPU 来训练大型视觉模型成为可能。作者的目标是在视觉预训练大模型这个方向上激发更多的研究,从而最终缩小视觉模型和语言模型之间的容量差距。
不同 Swin V2 的模型配置:
-
SwinV2-T: C= 96, layer numbers ={2,2,6,2} -
SwinV2-S: C= 96, layer numbers ={2,2,18,2} -
SwinV2-B: C= 128, layer numbers ={2,2,18,2} -
SwinV2-L: C= 192, layer numbers ={2,2,18,2} -
SwinV2-H: C= 352, layer numbers ={2,2,18,2} -
SwinV2-G: C= 512, layer numbers ={2,2,42,2}
对于 SwinV2-H 和 SwinV2-G 的模型训练,作者每经过6个 Transformer Block,就在主支路上增加了一层 LN,以进一步稳定训练和输出幅值。
Experiments
模型: SwinV2-G,3B parameters
Image classification
Dataset for Evaluation: ImageNet-1k,ImageNet-1k V2
Dataset for Pre-Training: ImageNet-22K-ext (70M images, 22k classes)
训练策略: 分辨率使用192×192,为了节约参数量。2-step 的预训练策略。首先以自监督学习的方式在 ImageNet-22K-ext 数据集上训练 20 epochs,再以有监督学习的方式在这个数据集上训练 30 epochs,SwinV2-G 模型在 ImageNet-1k 上面达到了惊人的90.17%的 Top-1 Accuracy,在 ImageNet-1k V2 上面也达到了惊人的84.00%的 Top-1 Accuracy,超过了历史最佳的83.33%。
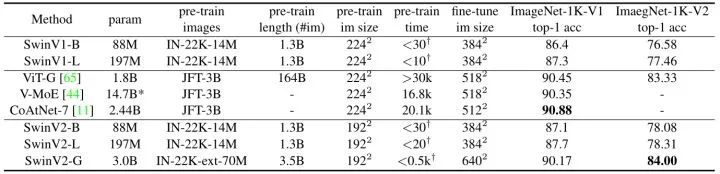
同时,使用 Swin V2 的训练策略以后,Base 模型和 Large 模型的性能也可以进一步提升。比如 SwinV2-B 和 SwinV2-L 在 SwinV1-B 和 SwinV1-L 的基础上分别涨点0.8%和0.4%,原因来自更多的 labelled data (ImageNet-22k-ext, 70M images), 更强的 Regularization,或是自监督学习策略。
Object detection,Instance Segmentation
Dataset for Evaluation: COCO
Dataset for Pre-Training: Object 365 v2
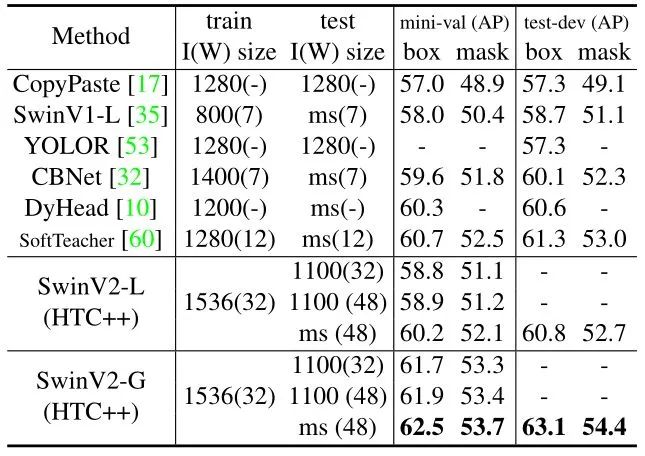
如下图6所示 SwinV2-G 模型与之前在 COCO 目标检测和实例分割任务上取得最佳性能模型进行了比较。SwinV2-G 在 COCO test-dev 上实现了 63.1/54.4 box/max AP,相比于 SoftTeacher (61.3/53.0) 提高了 + 1.8/1.4。
Semantic segmentation
Dataset for Evaluation: ADE20K
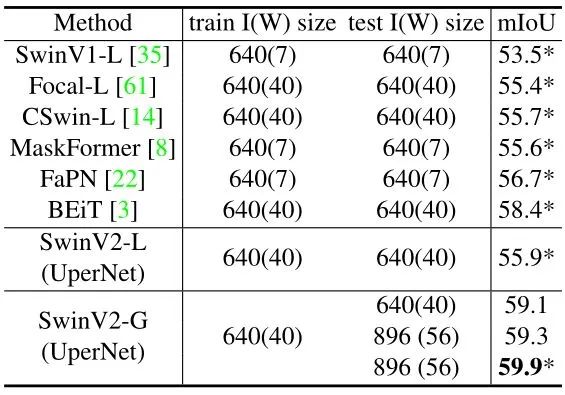
如下图7所示 SwinV2-G 模型与之前在 ADE20K 语义分割基准上的 SOTA 结果进行了比较。Swin-V2-G 在 ADE20K val 集上实现了 59.9 mIoU,相比于 BEiT 的 58.4 高了 1.5。
Video action classification
Dataset for Evaluation: Kinetics-400 (K400)
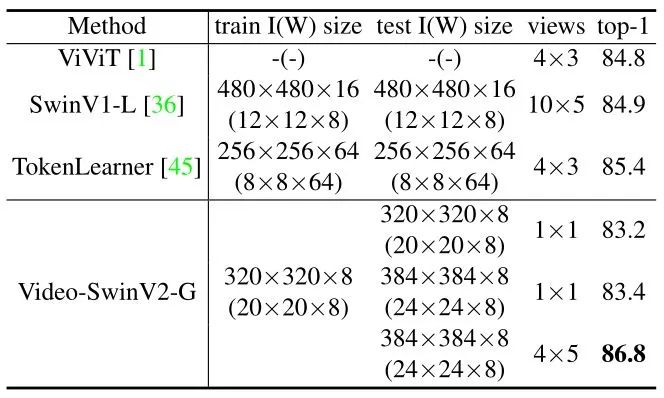
如下图8所示 SwinV2-G 模型与之前在 Kinetics-400 动作分类基准上的 SOTA 结果进行了比较。可以看到,Video-SwinV2-G 实现了 86.8% 的 top-1 准确率,比之前的 TokenLearner 方法的 85.4% 高出 +1.4%。
对比实验:post-norm 和 scaled cosine attention 的作用
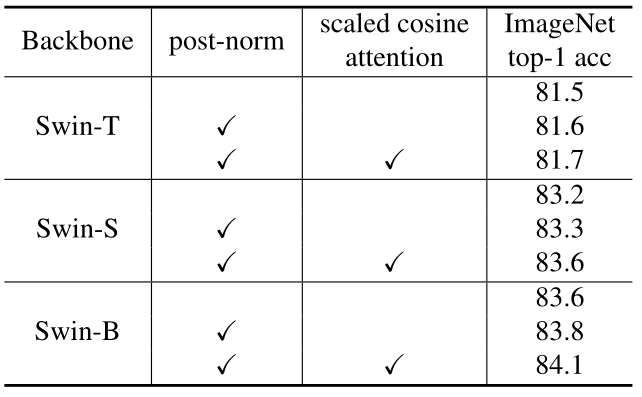
如下图9所示,这两种技术均能提高 Swin-T,Swin-S 和 Swin-B 的性能,总体提高分别为 0.2%,0.4% 和 0.5%。说明该技术对大模型更有利。更重要的是,它们能让训练更稳定。对于 Swin-H 和 Swin-G 模型而言,自监督预训练使用原来的 Swin V1 无法收敛,而 Swin V2 模型训练得很好。
39.2 Swin MLP 代码解读:
代码来自:
Swin MLP 代码来自 Swin Transformer 的官方实现。Swin Transformer 作者们在已有模型的基础上实现了 Swin MLP 模型,证明了 Window-based attention 对于 MLP 模型的有效性。
把张量 (B, H, W, C) 分成 window (B×H/M×W/M, M, M, C),其中M是 window_size。这一步相当于得到 B×H/M×W/M 个大小为 (M, M, C) 的 window。
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
把 window (B×H/M×W/M, M, M, C) 变回张量 (B, H, W, C)。
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
一个 Swin MLP Block
class SwinMLPBlock(nn.Module):
r""" Swin MLP Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
drop (float, optional): Dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.padding = [self.window_size - self.shift_size, self.shift_size,
self.window_size - self.shift_size, self.shift_size] # P_l,P_r,P_t,P_b
self.norm1 = norm_layer(dim)
# use group convolution to implement multi-head MLP
self.spatial_mlp = nn.Conv1d(self.num_heads * self.window_size ** 2,
self.num_heads * self.window_size ** 2,
kernel_size=1,
groups=self.num_heads)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# shift
if self.shift_size > 0:
P_l, P_r, P_t, P_b = self.padding
shifted_x = F.pad(x, [0, 0, P_l, P_r, P_t, P_b], "constant", 0)
else:
shifted_x = x
_, _H, _W, _ = shifted_x.shape
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# Window/Shifted-Window Spatial MLP
x_windows_heads = x_windows.view(-1, self.window_size * self.window_size, self.num_heads, C // self.num_heads)
x_windows_heads = x_windows_heads.transpose(1, 2) # nW*B, nH, window_size*window_size, C//nH
x_windows_heads = x_windows_heads.reshape(-1, self.num_heads * self.window_size * self.window_size,
C // self.num_heads)
spatial_mlp_windows = self.spatial_mlp(x_windows_heads) # nW*B, nH*window_size*window_size, C//nH
spatial_mlp_windows = spatial_mlp_windows.view(-1, self.num_heads, self.window_size * self.window_size,
C // self.num_heads).transpose(1, 2)
spatial_mlp_windows = spatial_mlp_windows.reshape(-1, self.window_size * self.window_size, C)
# merge windows
spatial_mlp_windows = spatial_mlp_windows.reshape(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(spatial_mlp_windows, self.window_size, _H, _W) # B H' W' C
# reverse shift
if self.shift_size > 0:
P_l, P_r, P_t, P_b = self.padding
x = shifted_x[:, P_t:-P_b, P_l:-P_r, :].contiguous()
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
注意 F.pad(x, [0, 0, P_l, P_r, P_t, P_b], "constant", 0) 的对象是 x,维度是 (B, H, W, C)。
padding相当于是第3维 (C 这一维) 不填充,第2维 (W 这一维) 左右分别填充 P_l, P_r,第1维 (H 这一维) 左右分别填充 P_t, P_b。
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C:
这句代码把 shifted_x 分成 nW*B 个 windows,其中每个 window 的维度是 (window_size, window_size, C)。# reverse shift
if self.shift_size > 0:
P_l, P_r, P_t, P_b = self.padding
x = shifted_x[:, P_t:-P_b, P_l:-P_r, :].contiguous()
else:
x = shifted_x
这里是如果进行了 shift 操作,则最后取得结果也应该是没有 padding 的部分,正好是 shifted_x[:, P_t:-P_b, P_l:-P_r, :]。
一个 Swin MLP Block 的 FLOPs,注意 WSA 的计算量是:
FLOPs (WSA) = (window_size * window_size)^2 * dim * number_window
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# Window/Shifted-Window Spatial MLP
if self.shift_size > 0:
nW = (H / self.window_size + 1) * (W / self.window_size + 1)
else:
nW = H * W / self.window_size / self.window_size
flops += nW * self.dim * (self.window_size * self.window_size) * (self.window_size * self.window_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops
每个 stage 之间的 PatchMerging连接,把 resolution 变为一半,dim 变为2倍。
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
def flops(self):
H, W = self.input_resolution
# norm
flops = H * W * self.dim
# reduction
flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
return flops
Patch Merging 操作把相邻的 2×2 个 tokens 给合并到一起,得到的 token 的维度是 。
Patch Merging 操作再通过一次线性变换把维度降为 。
一个 Swin MLP Layer
class BasicLayer(nn.Module):
""" A basic Swin MLP layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
drop (float, optional): Dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., drop=0., drop_path=0.,
norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList([
SwinMLPBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
drop=drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
def flops(self):
flops = 0
for blk in self.blocks:
flops += blk.flops()
if self.downsample is not None:
flops += self.downsample.flops()
return flops
包含 depth 个 Swin MLP Block。
注意计算 FLOPs 的方式:每个 blk 和 downsample 都自带 flops() 方法,可以直接来调用。
PatchEmbedded 操作
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
和 ViT 的 Patch Embedded 操作一样,本质上是一个 K=patch size,s=patch size 的 nn.Conv2d 操作,注意卷积 FLOPs 的计算公式即可。
SwinMLP 整体模型架构
class SwinMLP(nn.Module):
r""" Swin MLP
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin MLP layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
drop_rate (float): Dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
drop=drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, (nn.Linear, nn.Conv1d)):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def flops(self):
flops = 0
flops += self.patch_embed.flops()
for i, layer in enumerate(self.layers):
flops += layer.flops()
# adaptive average pool
flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)
# head
flops += self.num_features * self.num_classes
return flops
由4个 Stage 组成,每个 Stage 由 BasicLayer 实现。
传入的 depths 代表每个 Stage 的层数,比如 Swin-T 就是:[2, 2, 6, 2]。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~


# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选





