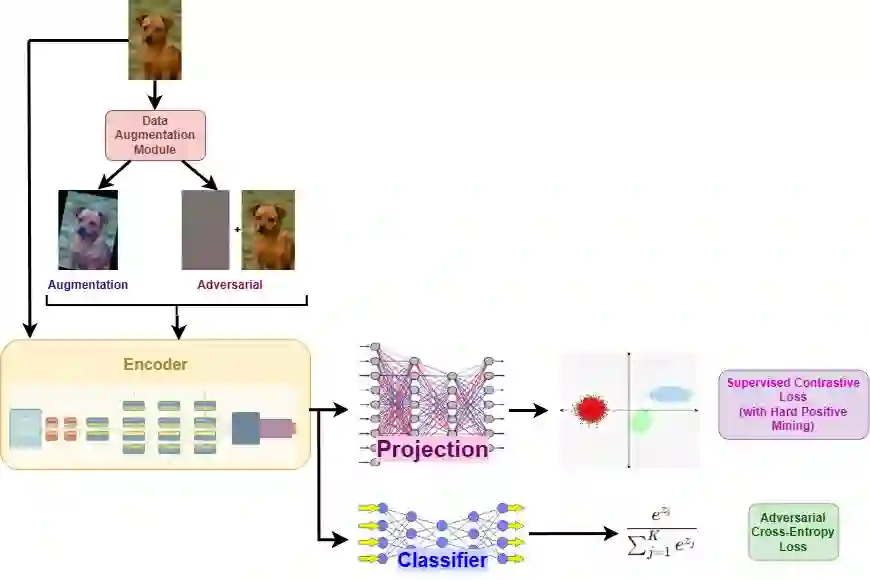
Neural networks have changed the way machines interpret the world. At their core, they learn by following gradients, adjusting their parameters step by step until they identify the most discriminant patterns in the data. This process gives them their strength, yet it also opens the door to a hidden flaw. The very gradients that help a model learn can also be used to produce small, imperceptible tweaks that cause the model to completely alter its decision. Such tweaks are called adversarial attacks. These attacks exploit this vulnerability by adding tiny, imperceptible changes to images that, while leaving them identical to the human eye, cause the model to make wrong predictions. In this work, we propose Adversarially-trained Contrastive Hard-mining for Optimized Robustness (ANCHOR), a framework that leverages the power of supervised contrastive learning with explicit hard positive mining to enable the model to learn representations for images such that the embeddings for the images, their augmentations, and their perturbed versions cluster together in the embedding space along with those for other images of the same class while being separated from images of other classes. This alignment helps the model focus on stable, meaningful patterns rather than fragile gradient cues. On CIFAR-10, our approach achieves impressive results for both clean and robust accuracy under PGD-20 (epsilon = 0.031), outperforming standard adversarial training methods. Our results indicate that combining adversarial guidance with hard-mined contrastive supervision helps models learn more structured and robust representations, narrowing the gap between accuracy and robustness.
翻译:神经网络改变了机器理解世界的方式。其核心在于通过梯度进行学习,逐步调整参数直至识别数据中最具判别性的模式。这一过程赋予了它们强大的能力,但也暴露了一个潜在的缺陷。帮助模型学习的梯度同样可用于生成微小且难以察觉的扰动,导致模型完全改变其决策。此类扰动被称为对抗攻击。这些攻击通过向图像添加微小、人眼无法察觉的变化来利用此漏洞,尽管图像对人类而言保持不变,却会导致模型做出错误预测。本文提出对抗训练对比硬挖掘优化鲁棒性框架(ANCHOR),该框架利用监督对比学习的力量,结合显式的硬正样本挖掘,使模型能够学习图像的表示,使得图像、其增强版本及其扰动版本在嵌入空间中与同类其他图像的嵌入聚集在一起,同时与其他类别的图像分离。这种对齐有助于模型关注稳定、有意义的模式,而非脆弱的梯度线索。在CIFAR-10数据集上,我们的方法在PGD-20(epsilon = 0.031)攻击下,无论是干净准确率还是鲁棒准确率均取得了显著成果,超越了标准的对抗训练方法。结果表明,将对抗引导与硬挖掘对比监督相结合有助于模型学习更具结构性和鲁棒性的表示,从而缩小准确率与鲁棒性之间的差距。