【推荐】深度学习目标检测全面综述
转自:爱可可-爱生活
With the rise of autonomous vehicles, smart video surveillance, facial detection and various people counting applications, fast and accurate object detection systems are rising in demand. These systems involve not only recognizing and classifying every object in an image, but localizing each one by drawing the appropriate bounding box around it. This makes object detection a significantly harder task than its traditional computer vision predecessor, image classification.
Fortunately, however, the most successful approaches to object detection are currently extensions of image classification models. A few months ago, Google released a new object detection API for Tensorflow. With this release came the pre-built architectures and weights for a few specific models:
Single Shot Multibox Detector (SSD) with MobileNets
SSD with Inception V2
Region-Based Fully Convolutional Networks (R-FCN) with Resnet 101
Faster RCNN with Resnet 101
Faster RCNN with Inception Resnet v2
In my last blog post, I covered the intuition behind the three base network architectures listed above: MobileNets, Inception, and ResNet. This time around, I want to do the same for Tensorflow’s object detection models: Faster R-CNN, R-FCN, and SSD. By the end of this post, we will hopefully have gained an understanding of how deep learning is applied to object detection, and how these object detection models both inspire and diverge from one another.
Faster R-CNN
Faster R-CNN is now a canonical model for deep learning-based object detection. It helped inspire many detection and segmentation models that came after it, including the two others we’re going to examine today. Unfortunately, we can’t really begin to understand Faster R-CNN without understanding its own predecessors, R-CNN and Fast R-CNN, so let’s take a quick dive into its ancestry.
R-CNN
R-CNN is the grand-daddy of Faster R-CNN. In other words, R-CNN reallykicked things off.
R-CNN, or Region-based Convolutional Neural Network, consisted of 3 simple steps:
Scan the input image for possible objects using an algorithm called Selective Search, generating ~2000 region proposals
Run a convolutional neural net (CNN) on top of each of these region proposals
Take the output of each CNN and feed it into a) an SVM to classify the region and b) a linear regressor to tighten the bounding box of the object, if such an object exists.
These 3 steps are illustrated in the image below:
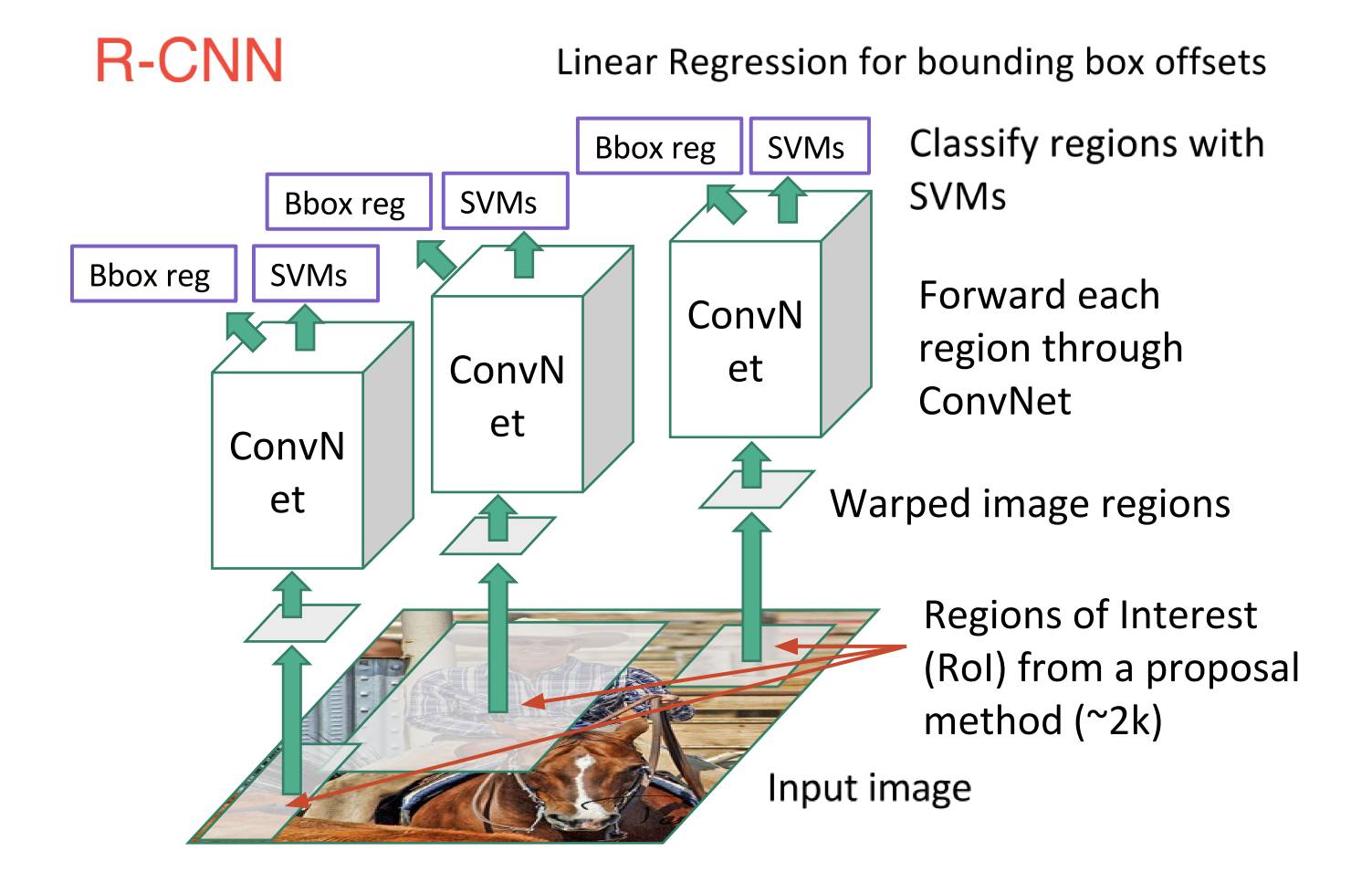
In other words, we first propose regions, then extract features, and then classify those regions based on their features. In essence, we have turned object detection into an image classification problem. R-CNN was very intuitive, but very slow.
Fast R-CNN
R-CNN’s immediate descendant was Fast-R-CNN. Fast R-CNN resembled the original in many ways, but improved on its detection speed through two main augmentations:
Performing feature extraction over the image before proposing regions, thus only running one CNN over the entire image instead of 2000 CNN’s over 2000 overlapping regions
Replacing the SVM with a softmax layer, thus extending the neural network for predictions instead of creating a new model
The new model looked something like this:
链接(需翻墙):
https://medium.com/towards-data-science/deep-learning-for-object-detection-a-comprehensive-review-73930816d8d9
原文链接:
https://m.weibo.cn/1402400261/4151522189164931



