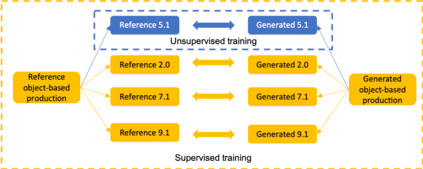
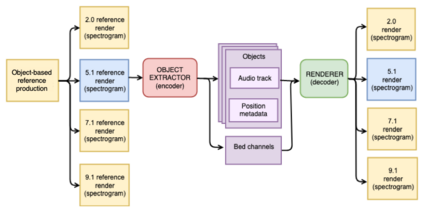
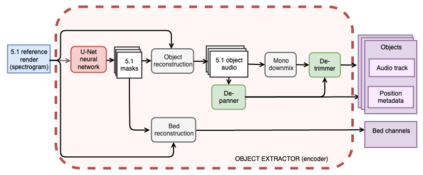
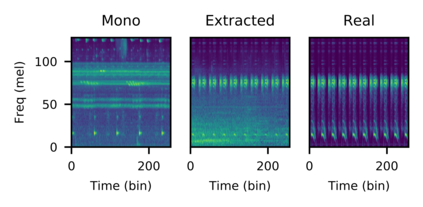
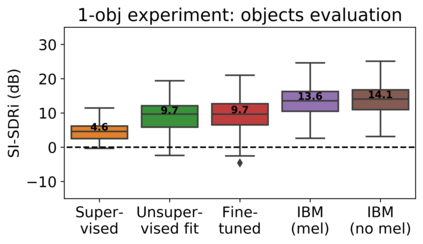
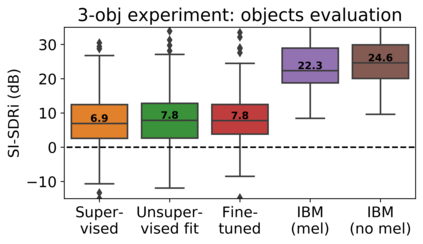
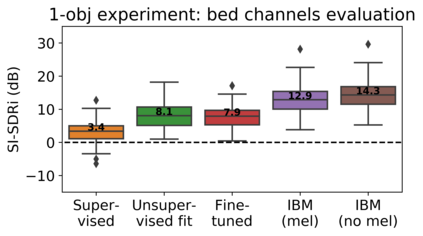
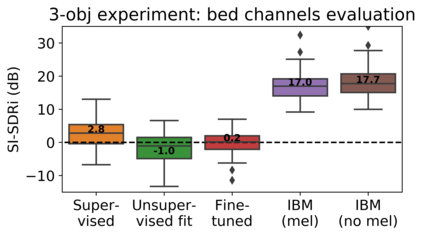
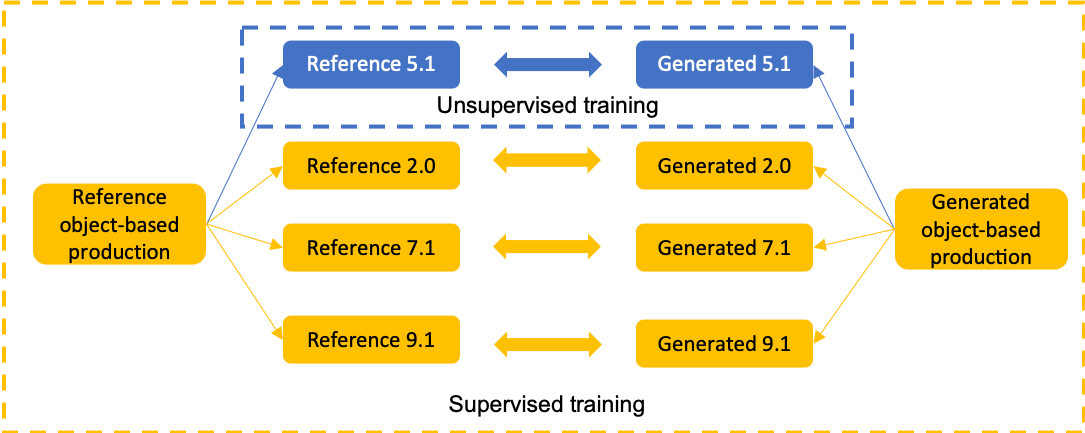
The current paradigm for creating and deploying immersive audio content is based on audio objects, which are composed of an audio track and position metadata. While rendering an object-based production into a multichannel mix is straightforward, the reverse process involves sound source separation and estimating the spatial trajectories of the extracted sources. Besides, cinematic object-based productions are often composed by dozens of simultaneous audio objects, which poses a scalability challenge for audio object extraction. Here, we propose a novel deep learning approach to object extraction that learns from the multichannel renders of object-based productions, instead of directly learning from the audio objects themselves. This approach allows tackling the object scalability challenge and also offers the possibility to formulate the problem in a supervised or an unsupervised fashion. Since, to our knowledge, no other works have previously addressed this topic, we first define the task and propose an evaluation methodology, and then discuss under what circumstances our methods outperform the proposed baselines.
翻译:目前创建和部署隐性音频内容的范式是以音频物体为基础,由音频音轨和位置元数据组成。将基于物体的制作变成多通道组合是直截了当的,反向过程则涉及声源分离和估计提取源的空间轨迹。此外,电影基于物体的制作往往由数十个同步音频物体组成,这给音频物体的提取带来了可缩放性挑战。在这里,我们建议对从多通道中学习的来自基于物体的制作,而不是直接从音频物体本身中学习的物体提取采用新的深层次学习方法。这一方法可以解决对物体可缩放性的挑战,也提供了以受监督或不受监督的方式制定问题的可能性。据我们所知,以前没有其它作品处理过这个问题,我们首先界定任务,提出评估方法,然后讨论在何种情况下我们的方法比拟议基线更符合。