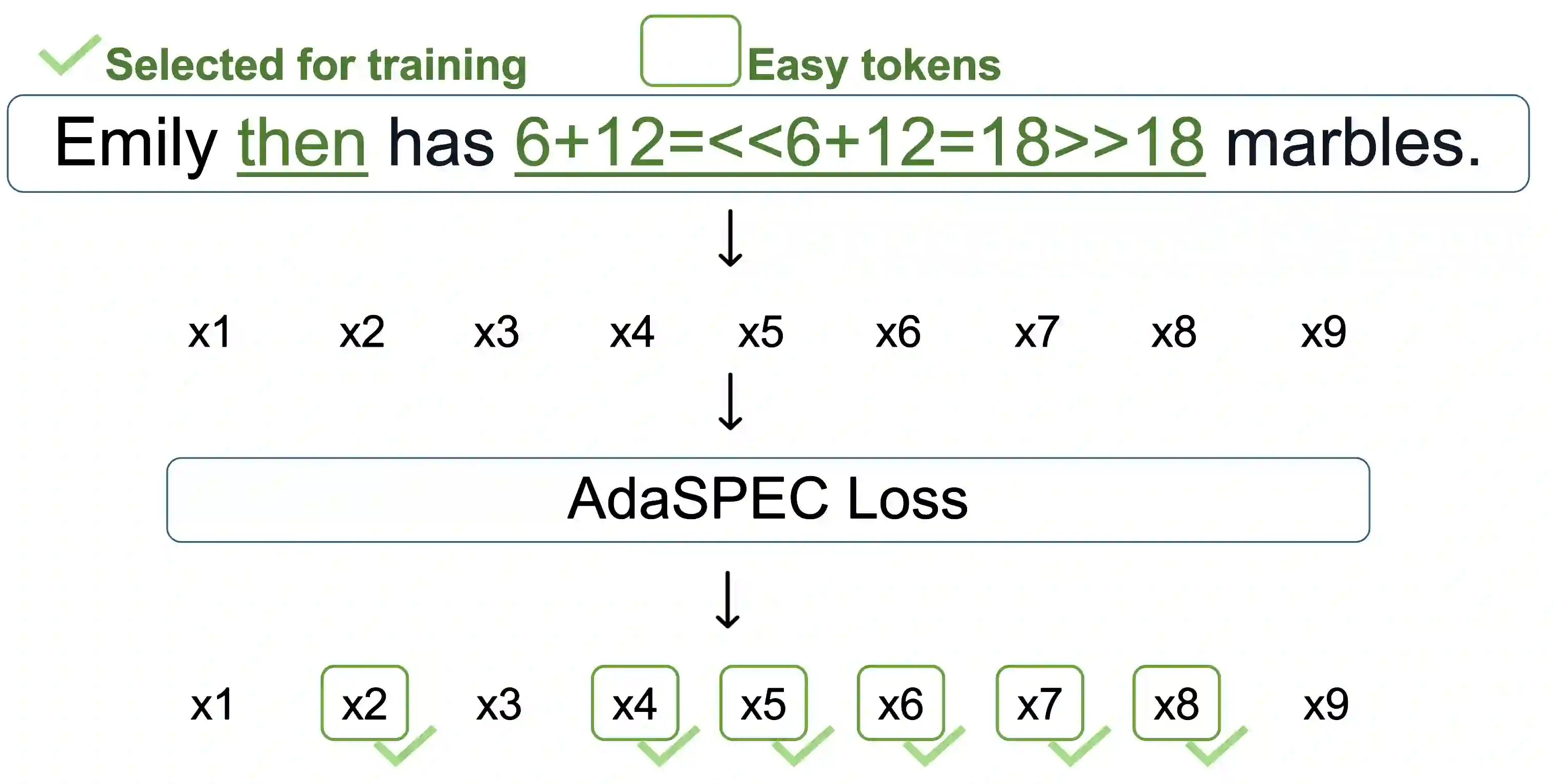
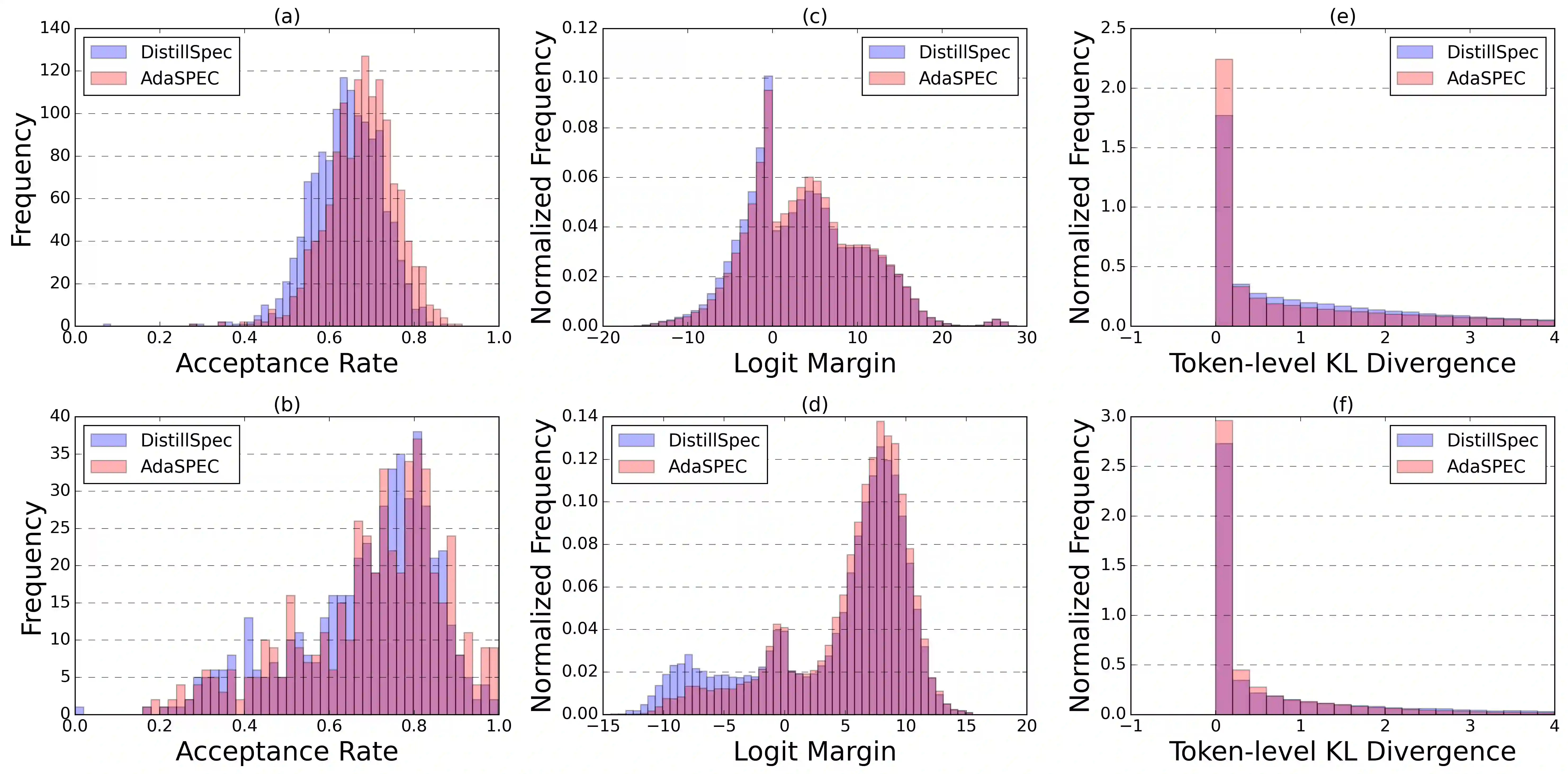
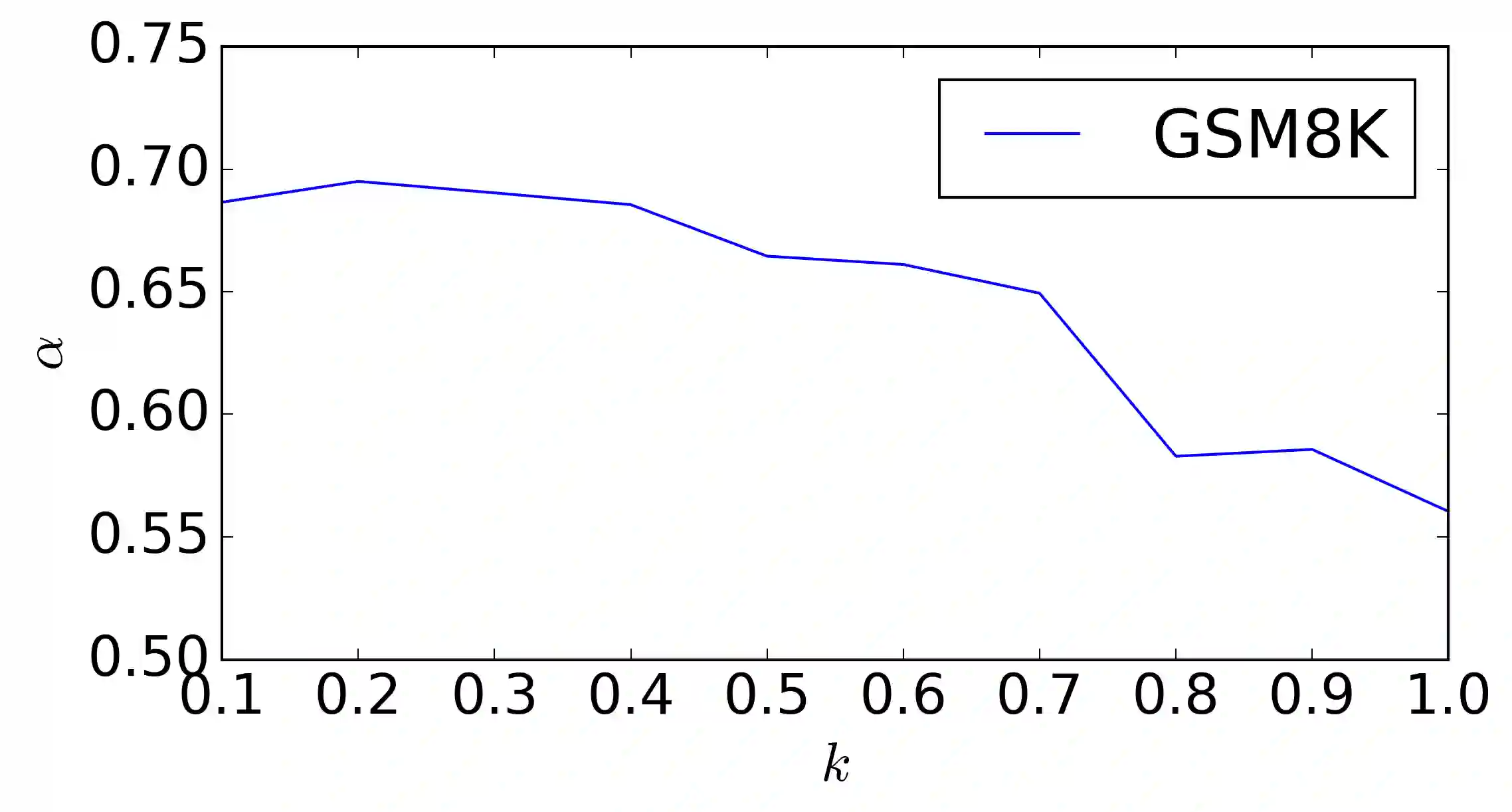
Speculative Decoding (SD) accelerates large language model inference by employing a small draft model to generate predictions, which are then verified by a larger target model. The effectiveness of SD hinges on the alignment between these models, which is typically enhanced by Knowledge Distillation (KD). However, conventional KD methods aim to minimize the KL divergence between the draft and target models across all tokens, a goal that is misaligned with the true objective of SD, which is to maximize token acceptance rate. Therefore, draft models often struggle to fully assimilate the target model's knowledge due to capacity constraints, leading to suboptimal performance. To address this challenge, we propose AdaSPEC, a novel method that incorporates selective token filtering into the KD process. AdaSPEC utilizes a reference model to identify and filter out difficult-to-fit tokens, enabling the distillation of a draft model that better aligns with the target model on simpler tokens. This approach improves the overall token acceptance rate without compromising generation quality. We evaluate AdaSPEC across diverse tasks, including arithmetic reasoning, instruction-following, coding, and summarization, using model configurations of 31M/1.4B and 350M/2.7B parameters. Our results demonstrate that AdaSPEC consistently outperforms the state-of-the-art DistillSpec method, achieving higher acceptance rates across all tasks (up to 15\%). The code is publicly available at https://github.com/yuezhouhu/adaspec.
翻译:推测解码(Speculative Decoding,SD)通过采用一个小型草稿模型生成预测,再由一个更大的目标模型进行验证,从而加速大语言模型的推理过程。SD的有效性取决于这两个模型之间的对齐程度,通常通过知识蒸馏(Knowledge Distillation,KD)来增强。然而,传统的KD方法旨在最小化草稿模型与目标模型在所有词元上的KL散度,这一目标与SD的真实目标——最大化词元接受率——并不一致。因此,由于容量限制,草稿模型往往难以完全吸收目标模型的知识,导致性能欠佳。为解决这一挑战,我们提出了AdaSPEC,一种在KD过程中引入选择性词元过滤的新方法。AdaSPEC利用一个参考模型来识别并过滤难以拟合的词元,从而能够在更简单的词元上蒸馏出与目标模型对齐更好的草稿模型。该方法在不损害生成质量的前提下,提高了整体词元接受率。我们在包括算术推理、指令遵循、代码生成和文本摘要在内的多样化任务上评估了AdaSPEC,使用的模型参数配置为31M/1.4B和350M/2.7B。实验结果表明,AdaSPEC在所有任务上均持续优于当前最先进的DistillSpec方法,实现了更高的接受率(最高提升15%)。代码已在 https://github.com/yuezhouhu/adaspec 公开。