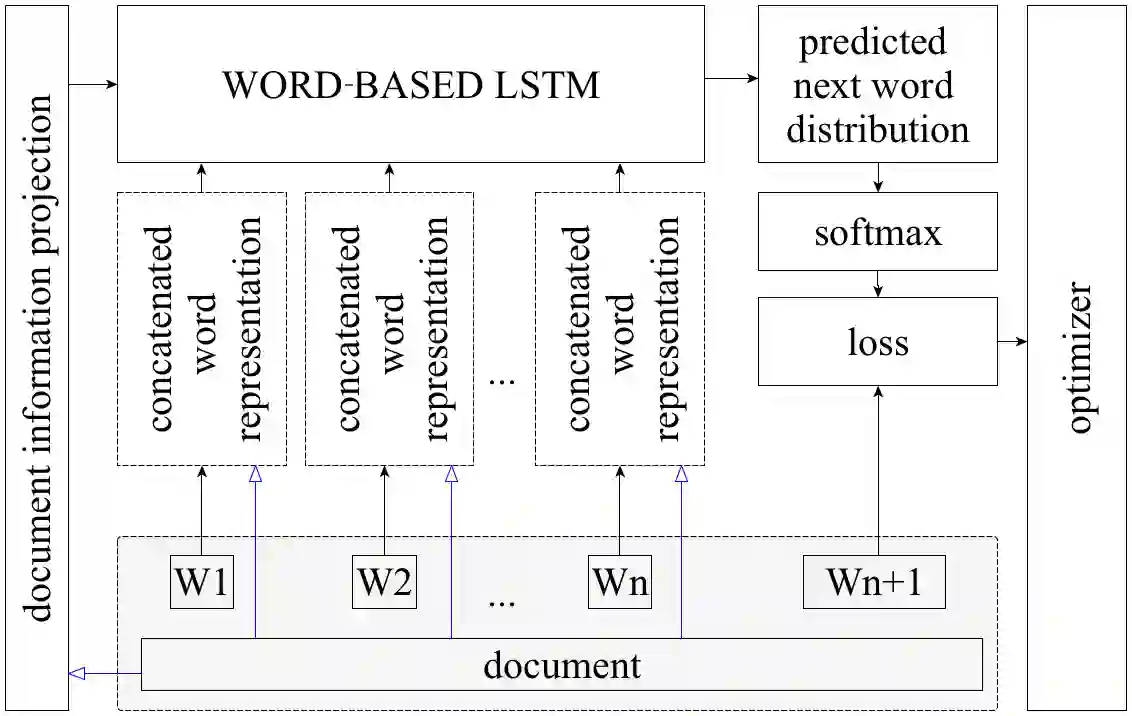
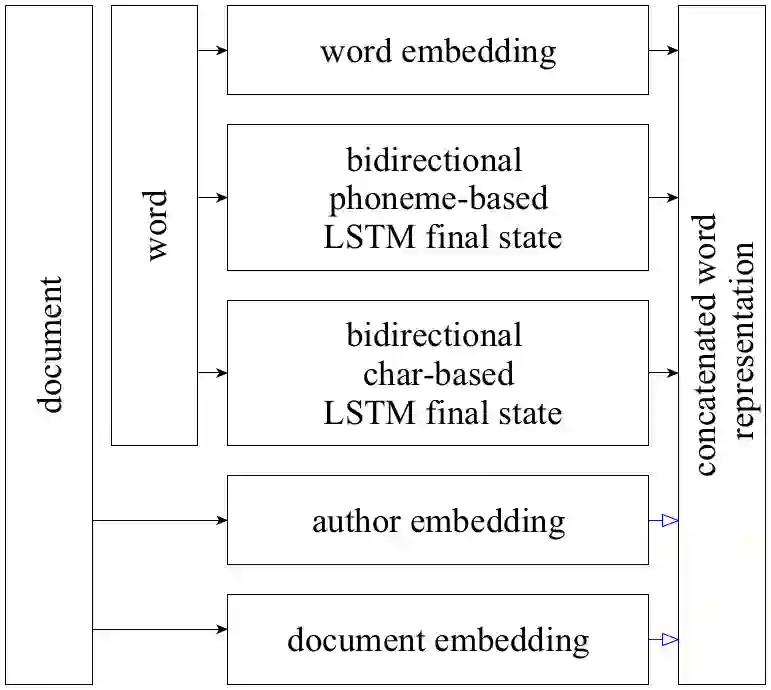
This paper addresses the problem of stylized text generation in a multilingual setup. A version of a language model based on a long short-term memory (LSTM) artificial neural network with extended phonetic and semantic embeddings is used for stylized poetry generation. The quality of the resulting poems generated by the network is estimated through bilingual evaluation understudy (BLEU), a survey and a new cross-entropy based metric that is suggested for the problems of such type. The experiments show that the proposed model consistently outperforms random sample and vanilla-LSTM baselines, humans also tend to associate machine generated texts with the target author.
翻译:本文论述多语种结构中以立体化文字生成问题,以长期短期内存(LSTM)人工神经网络为基础的语言模型的版本,以及长长的音频和语义嵌入器,用于发型化诗集,通过双语评估基础研究、一项调查以及针对这类类型的问题建议的一种基于跨元素的新的衡量标准,估计了网络所产生的诗的质量。实验表明,拟议的模型始终优于随机抽样和香草-LSTM基线,人类还倾向于将机器生成的文字与目标作者联系起来。