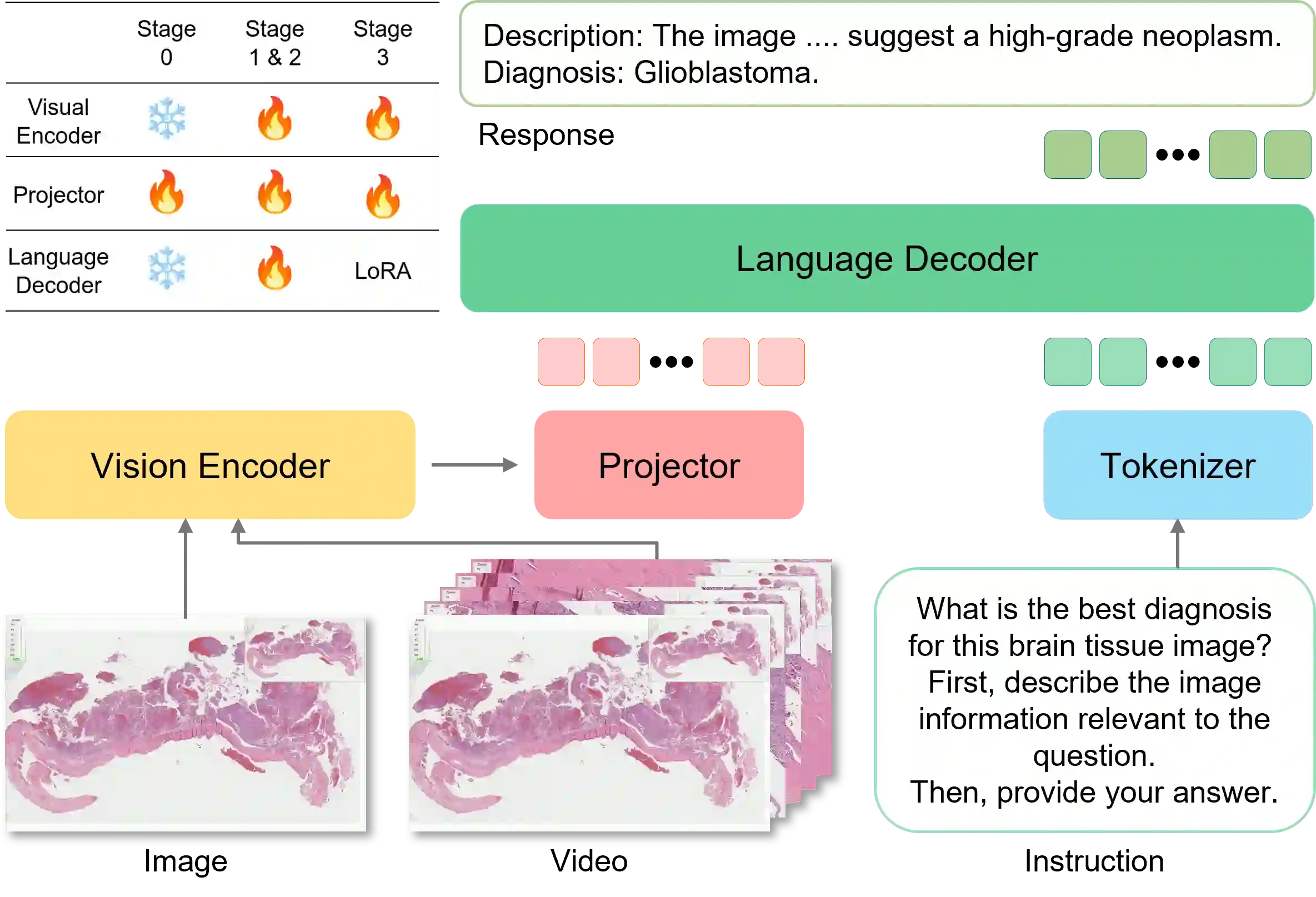
We present ViDRiP-LLaVA, the first large multimodal model (LMM) in computational pathology that integrates three distinct image scenarios, including single patch images, automatically segmented pathology video clips, and manually segmented pathology videos. This integration closely mirrors the natural diagnostic process of pathologists. By generating detailed histological descriptions and culminating in a definitive sign-out diagnosis, ViDRiP-LLaVA bridges visual narratives with diagnostic reasoning. Central to our approach is the ViDRiP-Instruct dataset, comprising 4278 video and diagnosis-specific chain-of-thought instructional pairs sourced from educational histopathology videos on YouTube. Although high-quality data is critical for enhancing diagnostic reasoning, its creation is time-intensive and limited in volume. To overcome this challenge, we transfer knowledge from existing single-image instruction datasets to train on weakly annotated, keyframe-extracted clips, followed by fine-tuning on manually segmented videos. ViDRiP-LLaVA establishes a new benchmark in pathology video analysis and offers a promising foundation for future AI systems that support clinical decision-making through integrated visual and diagnostic reasoning. Our code, data, and model are publicly available at: https://github.com/QuIIL/ViDRiP-LLaVA.
翻译:我们提出了ViDRiP-LLaVA,这是计算病理学领域首个集成三种不同图像场景的大型多模态模型(LMM),包括单张病理切片图像、自动分割的病理视频片段以及手动分割的病理视频。这种集成方式紧密模拟了病理学家的自然诊断过程。通过生成详细的组织学描述并最终形成明确的签出诊断,ViDRiP-LLaVA将视觉叙事与诊断推理联系起来。我们方法的核心是ViDRiP-Instruct数据集,该数据集包含4278个视频及诊断特定的思维链指令对,源自YouTube上的教育性组织病理学视频。尽管高质量数据对于提升诊断推理能力至关重要,但其创建过程耗时且数量有限。为克服这一挑战,我们从现有的单图像指令数据集中迁移知识,首先在弱标注、关键帧提取的视频片段上进行训练,随后在手动分割的视频上进行微调。ViDRiP-LLaVA为病理视频分析设立了新的基准,并为未来通过集成视觉与诊断推理来支持临床决策的人工智能系统奠定了有前景的基础。我们的代码、数据及模型已公开于:https://github.com/QuIIL/ViDRiP-LLaVA。