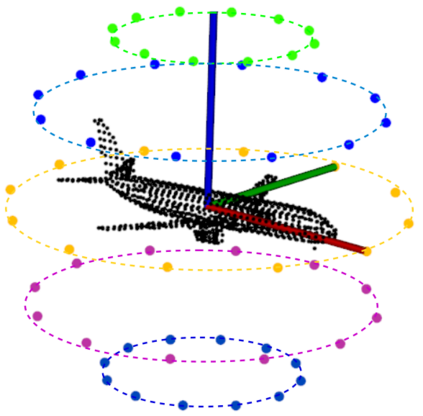
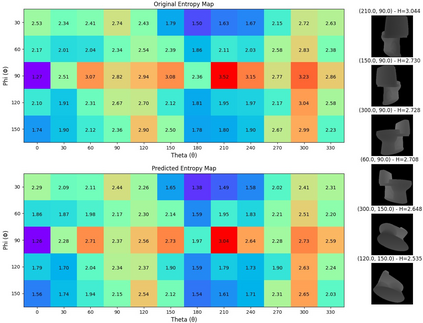
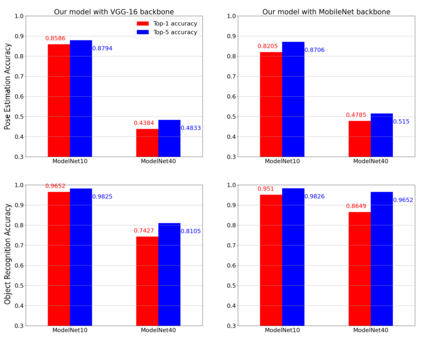
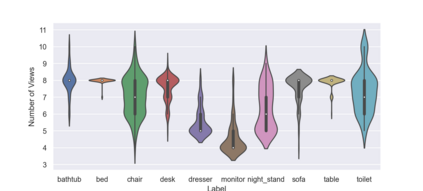
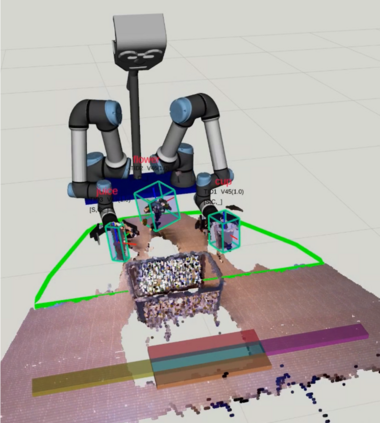
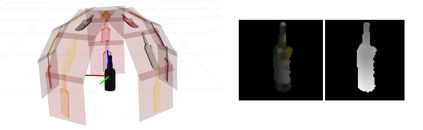
Simultaneous object recognition and pose estimation are two key functionalities for robots to safely interact with humans as well as environments. Although both object recognition and pose estimation use visual input, most state-of-the-art tackles them as two separate problems since the former needs a view-invariant representation while object pose estimation necessitates a view-dependent description. Nowadays, multi-view Convolutional Neural Network (MVCNN) approaches show state-of-the-art classification performance. Although MVCNN object recognition has been widely explored, there has been very little research on multi-view object pose estimation methods, and even less on addressing these two problems simultaneously. The pose of virtual cameras in MVCNN methods is often predefined in advance, leading to bound the application of such approaches. In this paper, we propose an approach capable of handling object recognition and pose estimation simultaneously. In particular, we develop a deep object-agnostic entropy estimation model, capable of predicting the best viewpoints of a given 3D object. The obtained views of the object are then fed to the network to simultaneously predict the pose and category label of the target object. Experimental results showed that the views obtained from such positions are descriptive enough to achieve a good accuracy score. Furthermore, we designed a real-life serve drink scenario to demonstrate how well the proposed approach worked in real robot tasks. Code is available online at: github.com/SubhadityaMukherjee/more_mvcnn
翻译:同时进行物体识别和姿态估计是机器人安全地与人类及环境进行交互所必须具备的两个重要功能。虽然物体识别和姿态估计都使用视觉输入,但大多数最先进的方法将它们视为两个不同的问题,因为前者需要一个视角不变的表示,而物体姿态估计需要一个视角相关的描述。当今,多视图卷积神经网络(MVCNN)中的方法展现出最先进的分类性能。尽管 MVCNN 物体识别已被广泛研究,但几乎没有关于多视图物体姿态估计方法的研究,甚至更少关注同时解决这两个问题。MVCNN 方法中的虚拟相机位置常常是预先定义好的,这限制了这种方法的应用范围。在本文中,我们提出了一种能够同时处理物体识别和姿态估计的方法。具体来说,我们开发了一种用于估计给定 3D 物体最佳视点的深度无关熵估计模型。然后将得到的物体视图输入到网络中,以同时预测目标物体的姿态和类别标签。实验结果表明,从这些位置获得的视图已足够描述性,能够获得良好的精度得分。此外,我们设计了一个模拟实际环境的服务饮料场景,以展示所提出的方法在实际机器人任务中的良好效果。代码可在以下网址上找到:github.com/SubhadityaMukherjee/more_mvcnn