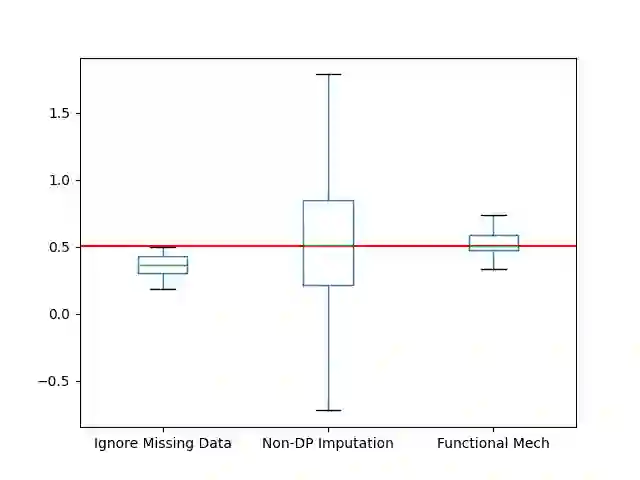
The literature on differential privacy almost invariably assumes that the data to be analyzed are fully observed. In most practical applications this is an unrealistic assumption. A popular strategy to address this problem is imputation, in which missing values are replaced by estimated values given the observed data. In this paper we evaluate various approaches to answering queries on an imputed dataset in a differentially private manner, as well as discuss trade-offs as to where along the pipeline privacy is considered. We show that if imputation is done without consideration to privacy, the sensitivity of certain queries can increase linearly with the number of incomplete records. On the other hand, for a general class of imputation strategies, these worst case scenarios can be greatly reduced by ensuring privacy already during the imputation stage. We use a simulated dataset to demonstrate these results across a number of imputation schemes (both private and non-private) and examine their impact on the utility of a private query on the data.
翻译:关于不同隐私的文献几乎无一例外地假定要分析的数据得到充分遵守。在大多数实际应用中,这是一个不现实的假设。解决这一问题的流行战略是估算,其中缺失的数值被根据观察到的数据的估计值所取代。在本文件中,我们评估了以不同私人方式回答关于估算数据集的询问的各种方法,并讨论了考虑管道隐私的取舍问题。我们表明,如果不考虑隐私进行估算,某些查询的敏感性可能会随着不完整记录的数量而线性地增加。另一方面,对于一般类别的估算战略而言,这些最坏的假设情况可以通过确保估算阶段的隐私而大大降低。我们使用模拟数据集来表明这些结果跨越若干估算计划(私人和非私人),并研究其对私人数据查询的效用的影响。