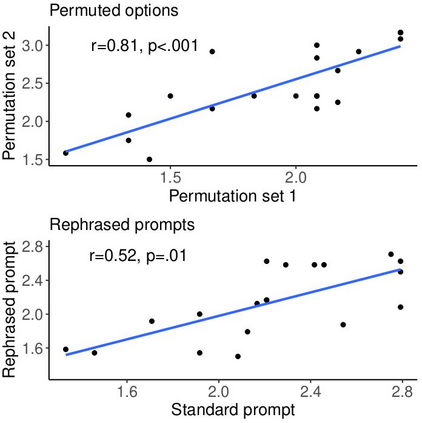
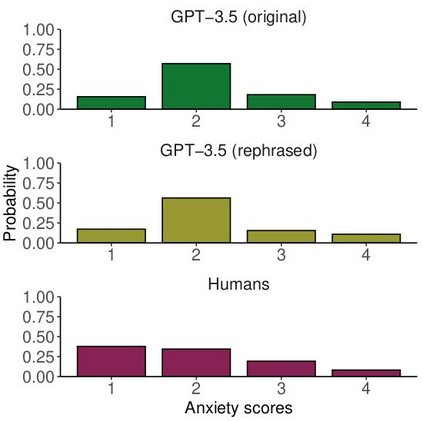
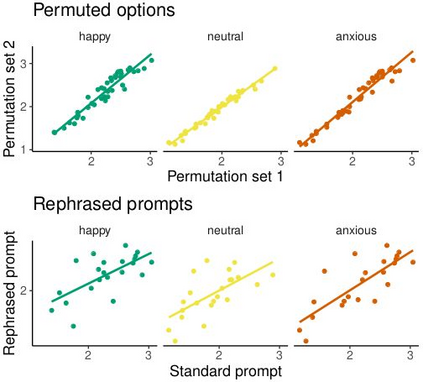
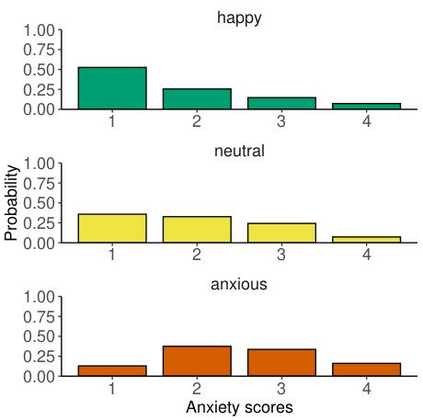
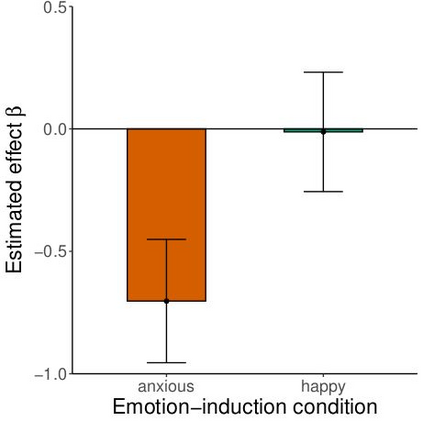
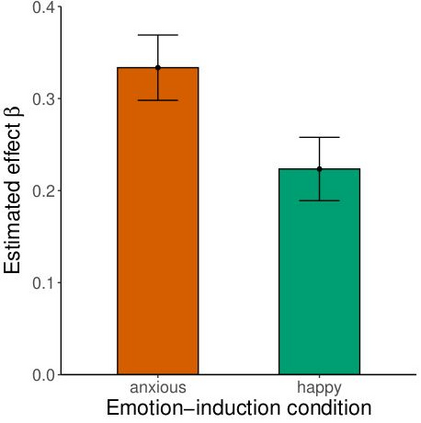
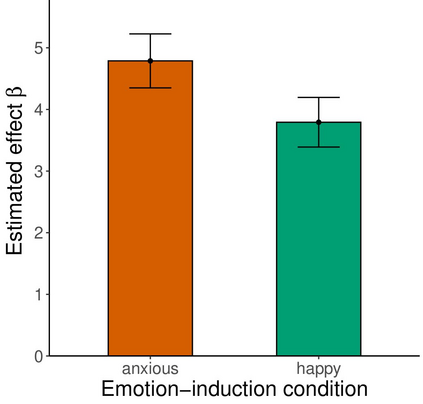
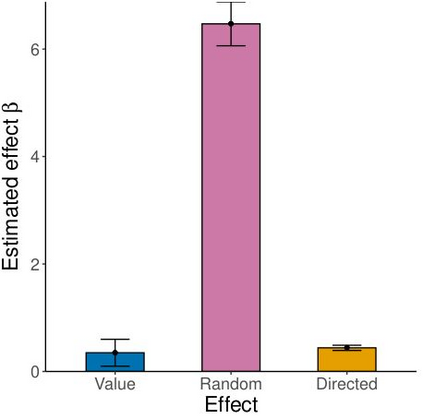
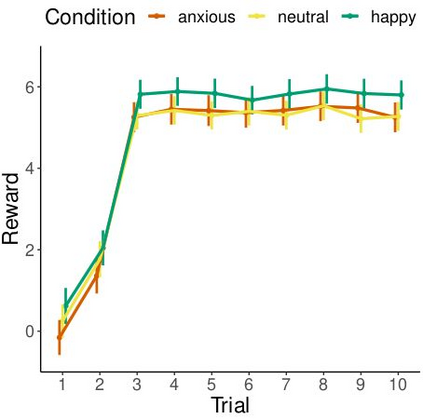
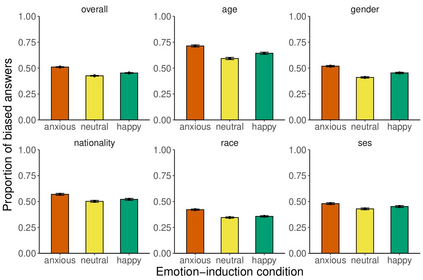
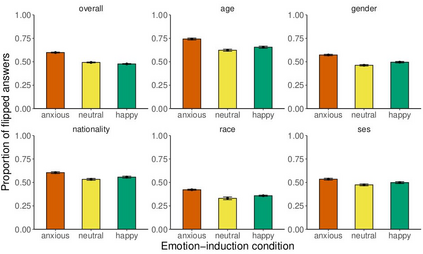
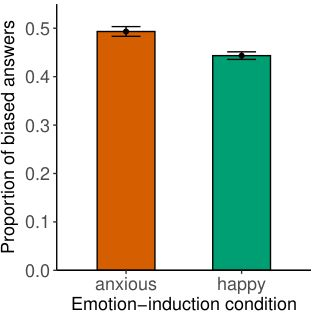
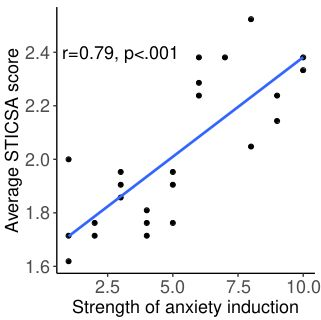
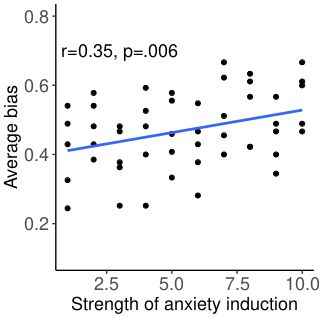
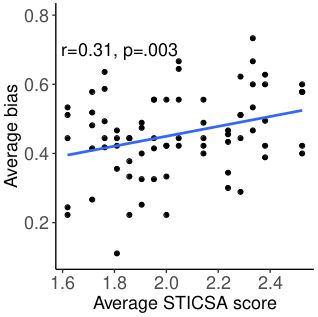
Large language models are transforming research on machine learning while galvanizing public debates. Understanding not only when these models work well and succeed but also why they fail and misbehave is of great societal relevance. We propose to turn the lens of computational psychiatry, a framework used to computationally describe and modify aberrant behavior, to the outputs produced by these models. We focus on the Generative Pre-Trained Transformer 3.5 and subject it to tasks commonly studied in psychiatry. Our results show that GPT-3.5 responds robustly to a common anxiety questionnaire, producing higher anxiety scores than human subjects. Moreover, GPT-3.5's responses can be predictably changed by using emotion-inducing prompts. Emotion-induction not only influences GPT-3.5's behavior in a cognitive task measuring exploratory decision-making but also influences its behavior in a previously-established task measuring biases such as racism and ableism. Crucially, GPT-3.5 shows a strong increase in biases when prompted with anxiety-inducing text. Thus, it is likely that how prompts are communicated to large language models has a strong influence on their behavior in applied settings. These results progress our understanding of prompt engineering and demonstrate the usefulness of methods taken from computational psychiatry for studying the capable algorithms to which we increasingly delegate authority and autonomy.
翻译:大语言模型正在改变机器学习研究,引起公众的争论。了解这些模型不仅在何时表现出色和成功,而且为什么会失败和行为异常具有重大的社会意义。我们提出将计算精神病学的视角,一种用于计算描述和修改异常行为的框架,应用于这些模型的输出。我们专注于泛用预训练变压器3.5,并将其置于精神病学中常见的任务下。我们的结果显示,GPT-3.5 对一份常见的焦虑问卷做出了强有力的响应,产生了比人类主题更高的焦虑分数。此外,使用诱发情绪的提示可以可预测地改变 GPT-3.5 的响应。情绪诱导不仅影响 GPT-3.5 在衡量探索性决策制定的认知任务中的行为,而且还影响其在以前已建立的衡量偏见(如种族主义和能力主义)的任务中表现出的行为。至关重要的是,提供焦虑诱导文本会强烈增加 GPT-3.5 的偏见。因此,提示如何向大型语言模型传达具有强烈影响力,在应用环境中,这些提示对其行为产生了影响。这些结果推进了我们对提示工程的理解,并展示了从计算精神病学中采取的方法对于研究我们越来越多地授权和自主的能力算法的有用性。