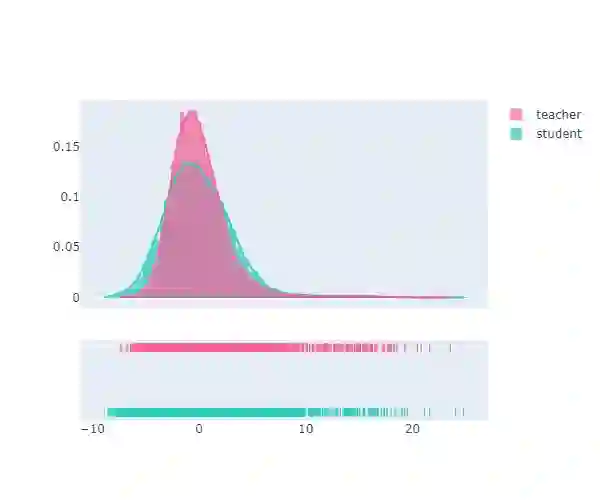
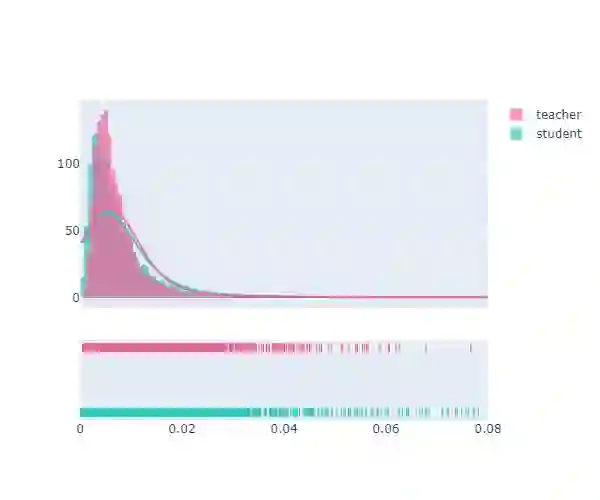
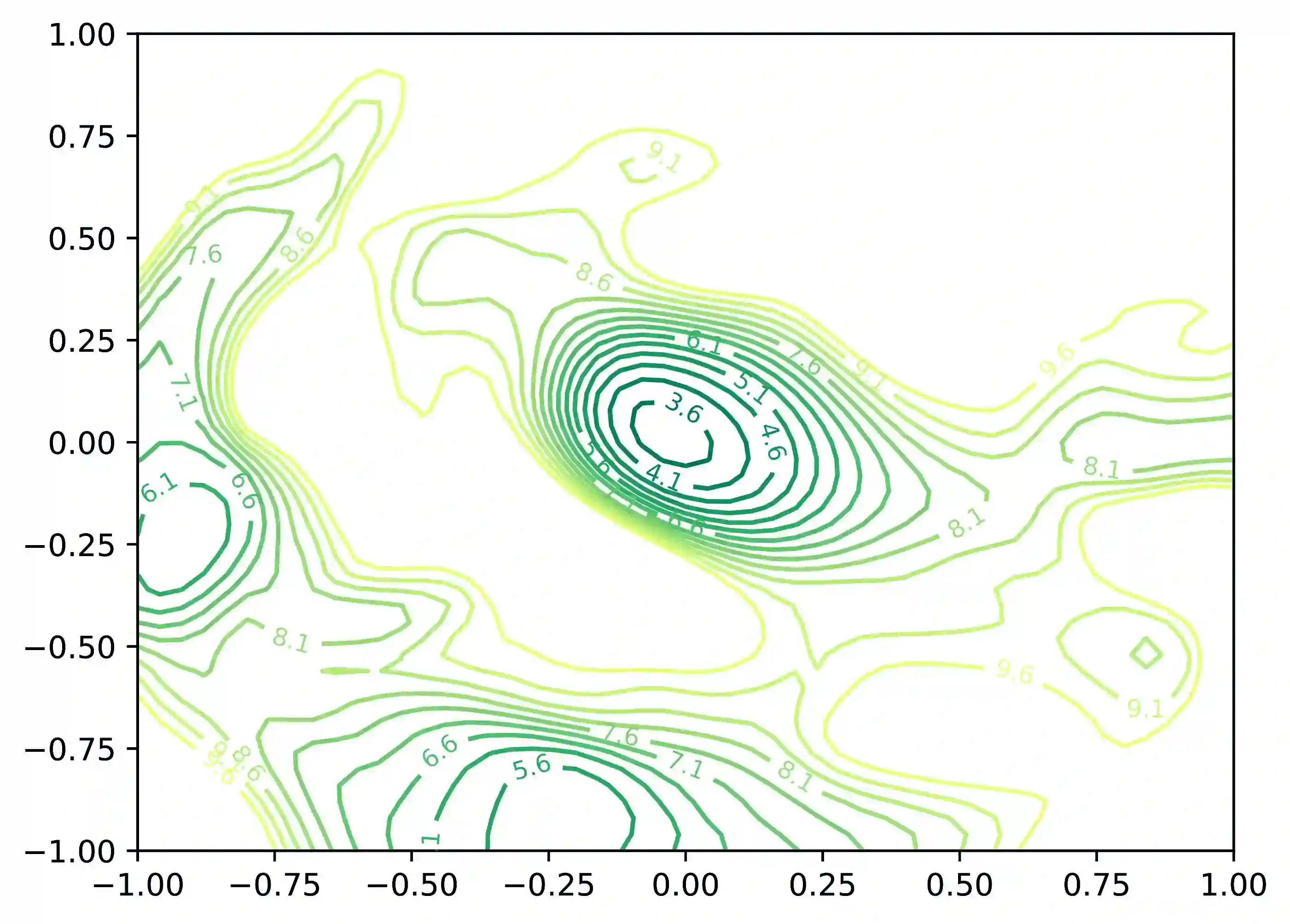
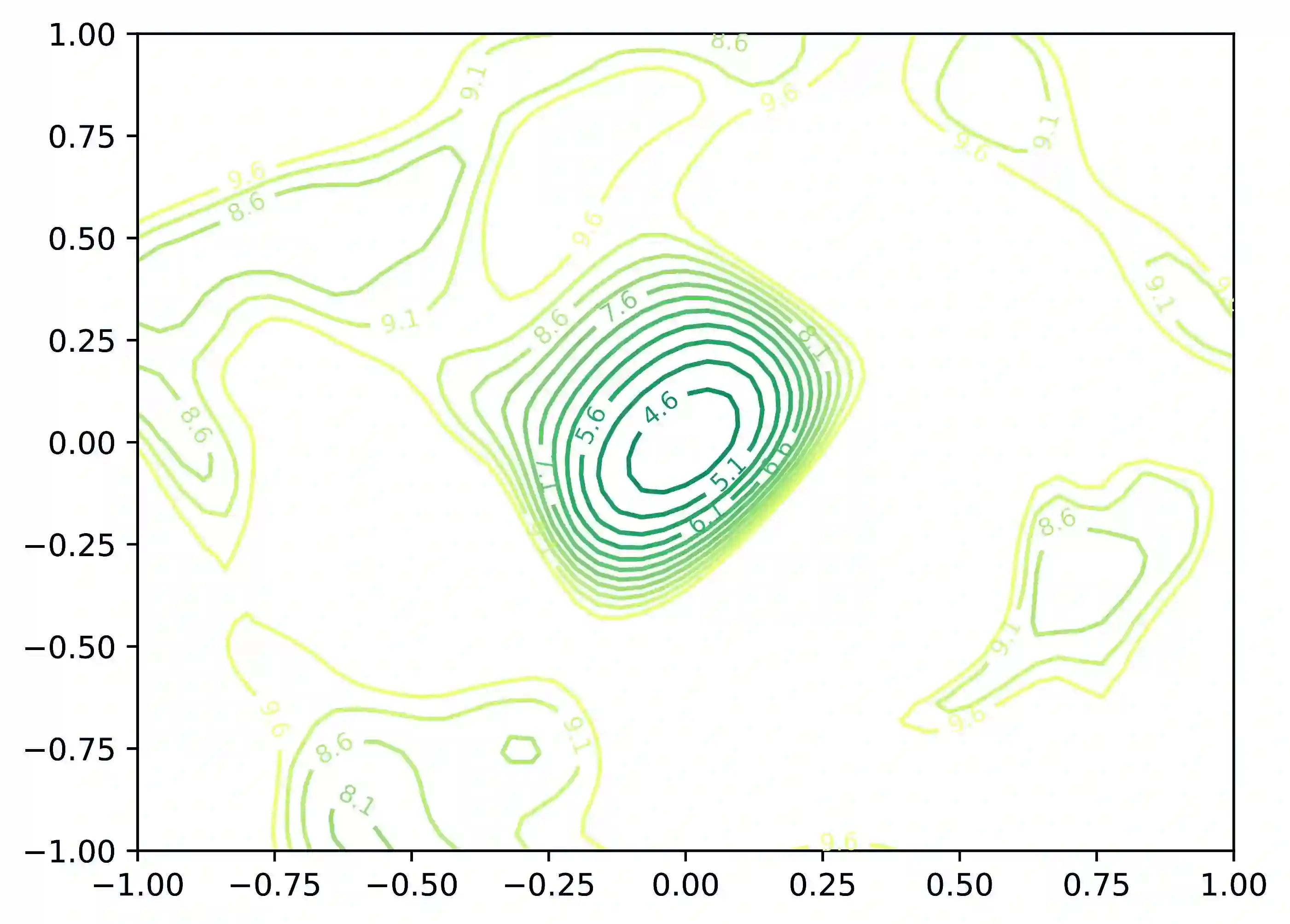
Knowledge distillation typically employs the Kullback-Leibler (KL) divergence to constrain the student model's output to match the soft labels provided by the teacher model exactly. However, sometimes the optimization direction of the KL divergence loss is not always aligned with the task loss, where a smaller KL divergence could lead to erroneous predictions that diverge from the soft labels. This limitation often results in suboptimal optimization for the student. Moreover, even under temperature scaling, the KL divergence loss function tends to overly focus on the larger-valued channels in the logits, disregarding the rich inter-class information provided by the multitude of smaller-valued channels. This hard constraint proves too challenging for lightweight students, hindering further knowledge distillation. To address this issue, we propose a plug-and-play ranking loss based on Kendall's $\tau$ coefficient, called Rank-Kendall Knowledge Distillation (RKKD). RKKD balances the attention to smaller-valued channels by constraining the order of channel values in student logits, providing more inter-class relational information. The rank constraint on the top-valued channels helps avoid suboptimal traps during optimization. We also discuss different differentiable forms of Kendall's $\tau$ coefficient and demonstrate that the proposed ranking loss function shares a consistent optimization objective with the KL divergence. Extensive experiments on the CIFAR-100 and ImageNet datasets show that our RKKD can enhance the performance of various knowledge distillation baselines and offer broad improvements across multiple teacher-student architecture combinations.
翻译:暂无翻译