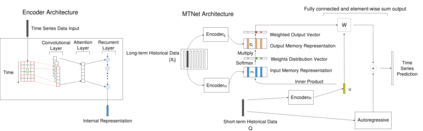
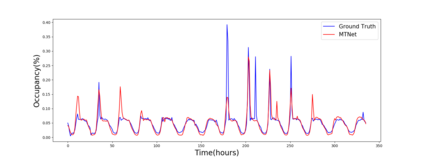
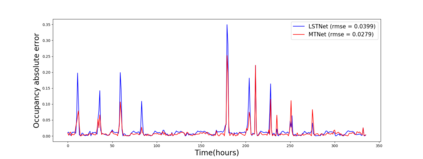
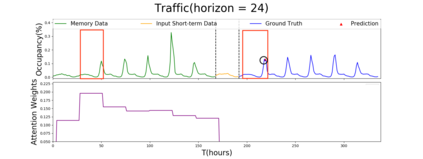
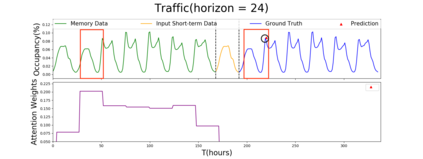
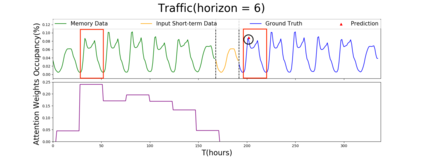
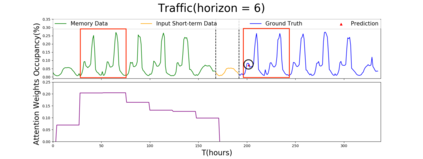
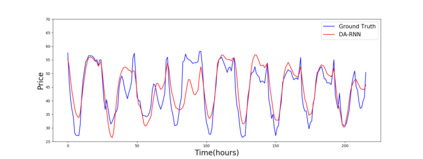
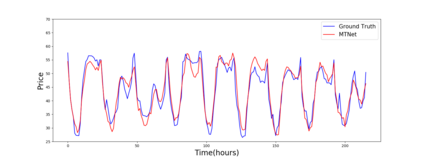
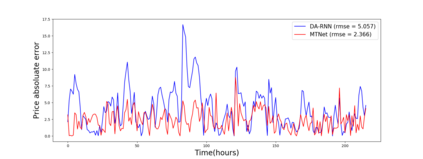
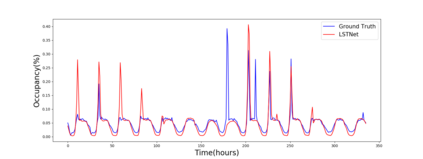
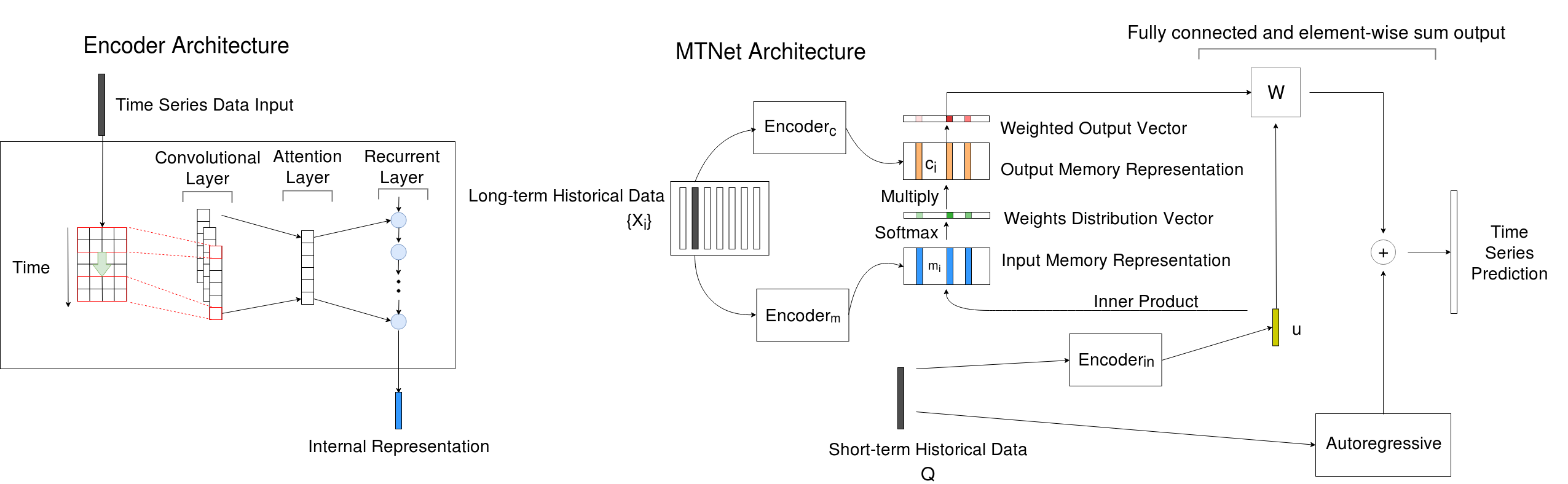
Multivariate time series forecasting is extensively studied throughout the years with ubiquitous applications in areas such as finance, traffic, environment, etc. Still, concerns have been raised on traditional methods for incapable of modeling complex patterns or dependencies lying in real word data. To address such concerns, various deep learning models, mainly Recurrent Neural Network (RNN) based methods, are proposed. Nevertheless, capturing extremely long-term patterns while effectively incorporating information from other variables remains a challenge for time-series forecasting. Furthermore, lack-of-explainability remains one serious drawback for deep neural network models. Inspired by Memory Network proposed for solving the question-answering task, we propose a deep learning based model named Memory Time-series network (MTNet) for time series forecasting. MTNet consists of a large memory component, three separate encoders, and an autoregressive component to train jointly. Additionally, the attention mechanism designed enable MTNet to be highly interpretable. We can easily tell which part of the historic data is referenced the most.
翻译:多年来,对多种时间序列的预测进行了广泛研究,在金融、交通、环境等领域的应用无处不在。 尽管如此,人们仍对无法模拟复杂模式的传统方法表示关切,或无法在真字数据中建模复杂模式或依赖性的传统方法。为解决这些关切,提出了各种深层次的学习模式,主要是经常性神经网络(RNN)方法;然而,捕捉极为长期的模式,同时有效地纳入其他变量的信息,仍然是时间序列预测的一个挑战。此外,缺乏解释性仍然是深神经网络模型的一个严重缺陷。根据记忆网络为解决问题而提出的解决方案,我们提议为时间序列预测采用一个名叫记忆时间序列网络(MTNet)的深层次学习模型。MTNet包括一个大型的记忆组成部分、三个独立的编码器和一个联合培训的自反部分。此外,设计使MTNet能够高度可解释的注意机制。我们可以很容易地知道历史数据中哪些部分被引用最多。