
《DeepGCNs: Making GCNs Go as Deep as CNNs》G Li, M Müller, G Qian, I C. Delgadillo, A Abualshour, A Thabet, B Ghanem [KAUST] (2019)
成为VIP会员查看完整内容



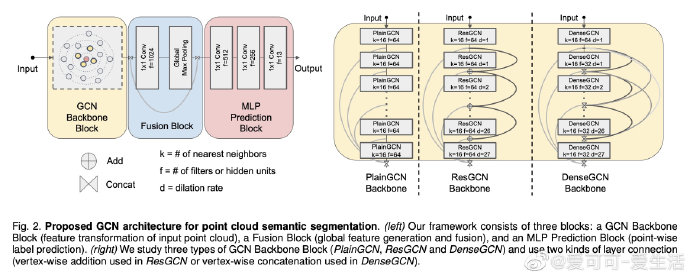
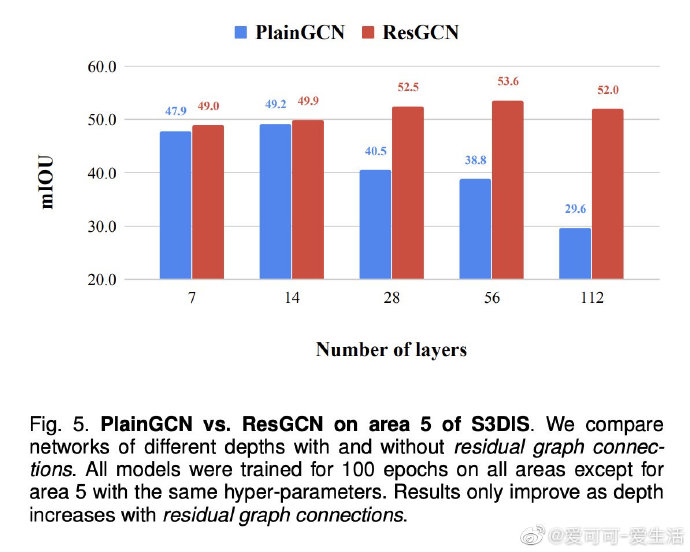
相关内容

专知会员服务
136+阅读 · 2020年3月8日
Arxiv
13+阅读 · 2019年5月22日

相关VIP内容
专知会员服务
136+阅读 · 2020年3月8日
相关资讯
相关论文
Arxiv
13+阅读 · 2019年5月22日