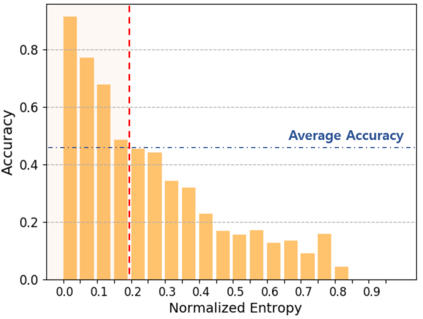
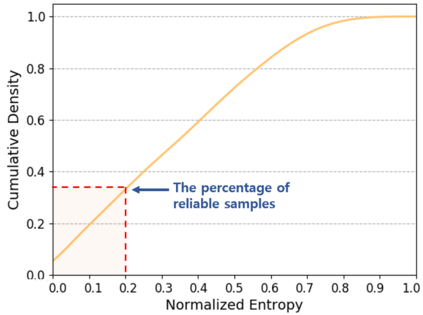
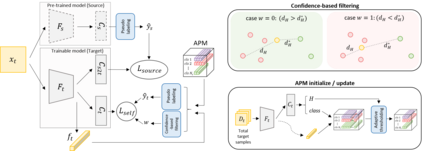
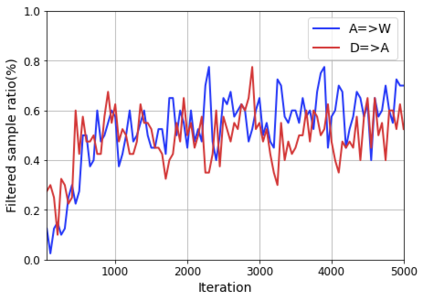
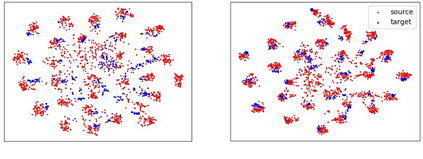
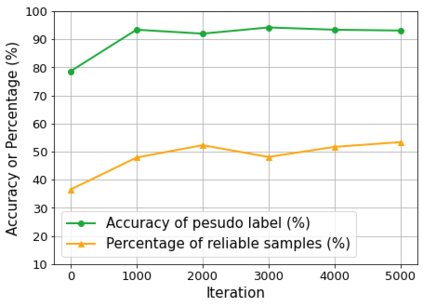
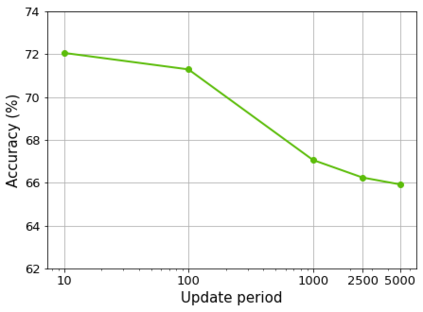
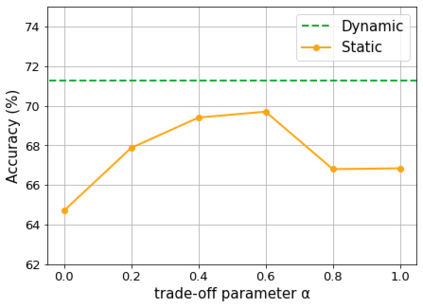
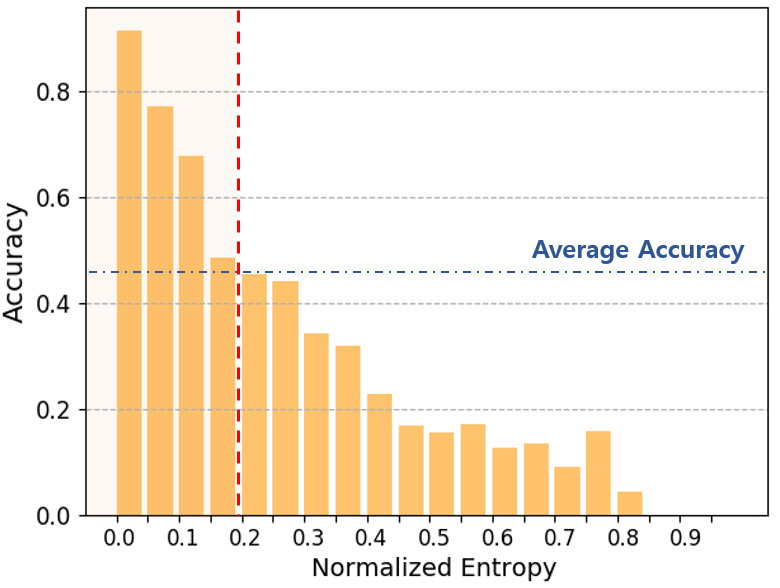
Domain adaptation assumes that samples from source and target domains are freely accessible during a training phase. However, such an assumption is rarely plausible in the real-world and possibly causes data-privacy issues, especially when the label of the source domain can be a sensitive attribute as an identifier. To avoid accessing source data that may contain sensitive information, we introduce progressive domain adaptation (PrDA). Our key idea is to leverage a pre-trained model from the source domain and progressively update the target model in a self-learning manner. We observe that target samples with lower self-entropy measured by the pre-trained source model are more likely to be classified correctly. From this, we select the reliable samples with the self-entropy criterion and define these as class prototypes. We then assign pseudo labels for every target sample based on the similarity score with class prototypes. Furthermore, to reduce the uncertainty from the pseudo labeling process, we propose set-to-set distance-based filtering which does not require any tunable hyperparameters. Finally, we train the target model with the filtered pseudo labels with regularization from the pre-trained source model. Surprisingly, without direct usage of labeled source samples, our PrDA outperforms conventional domain adaptation methods on benchmark datasets. Our code is publicly available at https://github.com/youngryan1993/PrDA-Progressive-Domain-Adaptation-from-a-Source-Pre-trained-Model.
翻译:校内调适假设源域和目标域的样本在培训阶段可以自由获取。然而,在现实世界中,这种假设很少可信,并可能造成数据隐私问题,特别是当源域的标签可能是一个敏感属性作为识别符号时。为避免获取可能包含敏感信息的源数据,我们引入了渐进域适应(PrDA) 。我们的关键想法是利用源域预先培训的模型,并逐步以自学的方式更新目标模型。我们观察到,通过经过培训的源模型测量的自湿度较低的目标样本更有可能被正确分类。我们从中选择了具有自湿度标准的可靠样本,并将这些样本定义为类原型。我们随后根据与类原型相似的评分为每个目标样本指定假标签。此外,为了减少来自源域的假标签过程的不确定性,我们建议采用固定到定的远程过滤器,而不需要任何金枪鱼可量的超度。最后,我们用经培训的过滤的假标签模型来进行分类。我们从经过培训的自湿度标准的源模型中选择了可靠的样本,然后将这些样本定义为类原型。我们用常规的校内校内制数据直接用于。我们在数据库的校内校内校内校内校内校内校内校外的校内校内校内数据。