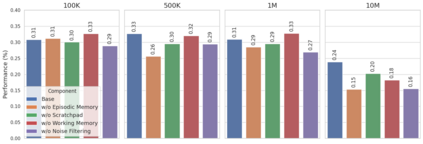
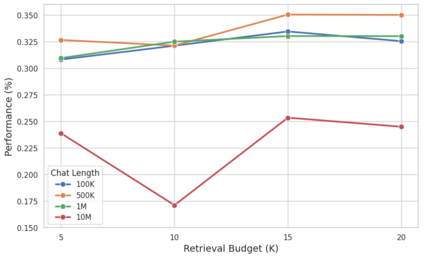
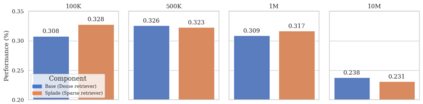
Evaluating the abilities of large language models (LLMs) for tasks that require long-term memory and thus long-context reasoning, for example in conversational settings, is hampered by the existing benchmarks, which often lack narrative coherence, cover narrow domains, and only test simple recall-oriented tasks. This paper introduces a comprehensive solution to these challenges. First, we present a novel framework for automatically generating long (up to 10M tokens), coherent, and topically diverse conversations, accompanied by probing questions targeting a wide range of memory abilities. From this, we construct BEAM, a new benchmark comprising 100 conversations and 2,000 validated questions. Second, to enhance model performance, we propose LIGHT-a framework inspired by human cognition that equips LLMs with three complementary memory systems: a long-term episodic memory, a short-term working memory, and a scratchpad for accumulating salient facts. Our experiments on BEAM reveal that even LLMs with 1M token context windows (with and without retrieval-augmentation) struggle as dialogues lengthen. In contrast, LIGHT consistently improves performance across various models, achieving an average improvement of 3.5%-12.69% over the strongest baselines, depending on the backbone LLM. An ablation study further confirms the contribution of each memory component.
翻译:评估大语言模型(LLMs)在需要长期记忆及长上下文推理的任务(例如对话场景)中的能力,受到现有基准测试的制约,这些基准往往缺乏叙事连贯性、覆盖领域狭窄,且仅测试简单的回忆型任务。本文针对这些挑战提出了一套综合性解决方案。首先,我们提出了一种新颖的框架,用于自动生成长度可达1000万标记、连贯且主题多样的对话,并附带针对广泛记忆能力的探测性问题。基于此,我们构建了BEAM——一个包含100段对话和2000个已验证问题的新基准。其次,为提升模型性能,我们提出了LIGHT框架,该框架受人类认知启发,为LLMs配备了三种互补的记忆系统:长期情景记忆、短期工作记忆以及用于积累关键事实的暂存器。我们在BEAM上的实验表明,即使具备100万标记上下文窗口的LLMs(无论是否采用检索增强技术),随着对话长度的增加,其表现也会显著下降。相比之下,LIGHT在不同模型中均能持续提升性能,相较于最强基线模型,平均提升幅度在3.5%至12.69%之间,具体取决于所采用的骨干LLM。消融研究进一步证实了每个记忆组件的贡献。