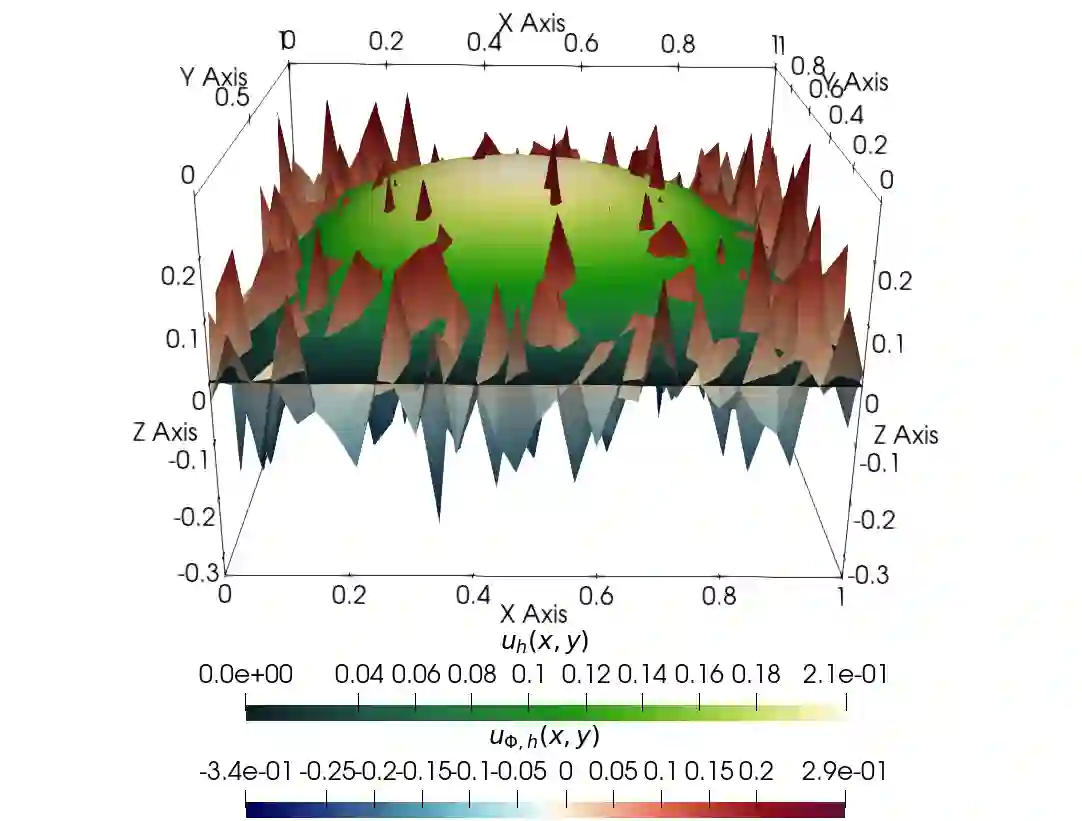
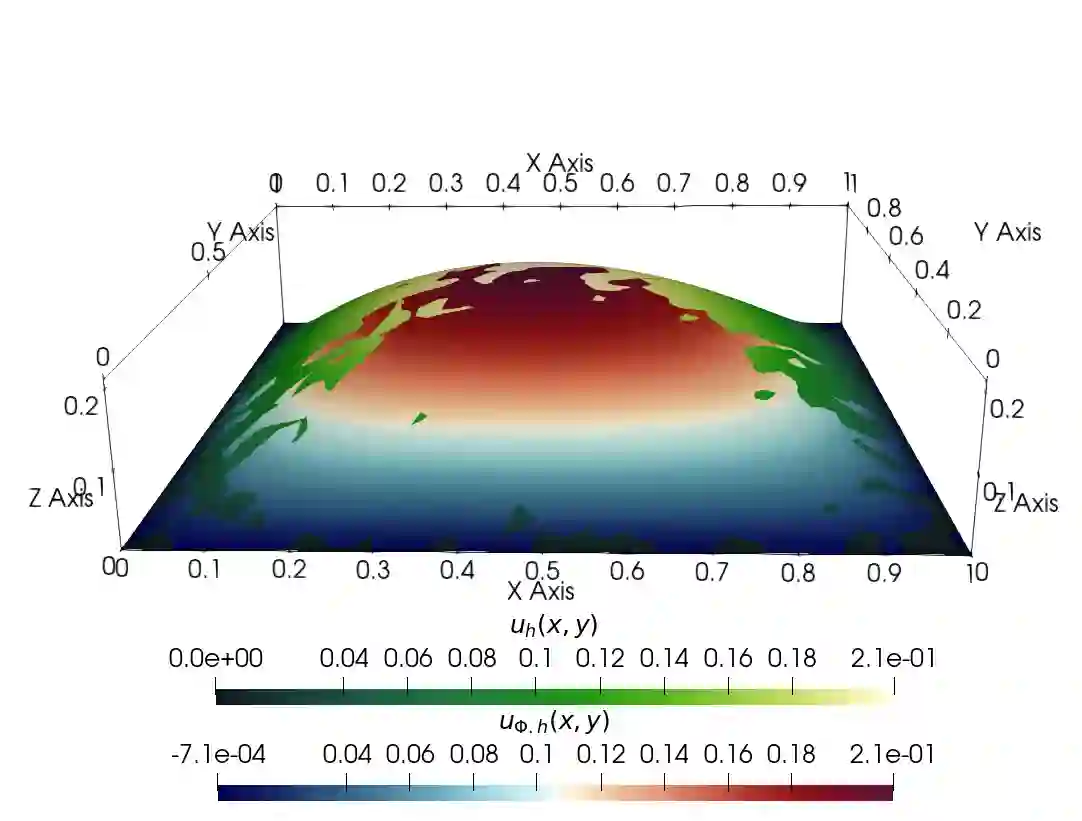
The accurate approximation of scalar-valued functions from sample points is a key task in mathematical modeling and computational science. Recently, machine learning techniques based on Deep Neural Networks (DNNs) have begun to emerge as promising tools for function approximation in scientific computing problems, with impressive results achieved on problems where the dimension of the underlying data or problem domain is large. In this work, we broaden this perspective by focusing on approximation of functions that are Hilbert-valued, i.e. they take values in a separable, but typically infinite-dimensional, Hilbert space. This problem arises in many science and engineering problems, in particular those involving the solution of parametric Partial Differential Equations (PDEs). Such problems are challenging for three reasons. First, pointwise samples are expensive to acquire. Second, the domain of the function is usually high dimensional, and third, the range lies in a Hilbert space. Our contributions are twofold. First, we present a novel result on DNN training for holomorphic functions with so-called hidden anisotropy. This result introduces a DNN training procedure and a full theoretical analysis with explicit guarantees on the error and sample complexity. This error bound is explicit in the three key errors occurred in the approximation procedure: best approximation error, measurement error and physical discretization error. Our result shows that there is a procedure for learning Hilbert-valued functions via DNNs that performs as well as current best-in-class schemes. Second, we provide preliminary numerical results illustrating the practical performance of DNNs on Hilbert-valued functions arising as solutions to parametric PDEs. We consider different parameters, modify the DNN architecture to achieve better and competitive results and compare these to current best-in-class schemes.
翻译:抽样点的标值函数准确近似是数学模型和计算科学的关键任务。 最近,基于深神经网络(DNN)的机器学习技术开始成为科学计算问题中功能近似的有希望的工具,在基础数据或问题域范围大的问题上取得了令人印象深刻的成果。 在这项工作中,我们通过侧重于希尔伯特所估值的函数近近似,即:它们取值为分解,但通常为无限的Hilbert空间。这个问题出现在许多科学和工程问题中,特别是涉及偏差部分偏差参数参数(PDE)的解决方案。由于三个原因,这些问题具有挑战性:第一,点抽样是昂贵的。第二,功能的领域通常高维度,第三,范围在希尔伯特所估的域。我们的贡献是双重的。首先,我们提出了DNNE培训的隐性功能的新结果,而内含所谓的内置值(OW)隐性软性)空间。这导致DNNE培训程序和完全的理论分析过程, 也就是在精确的当前误差中实现最佳的精确度, 也就是我们最精确的测算和最精确的精确的测算过程。