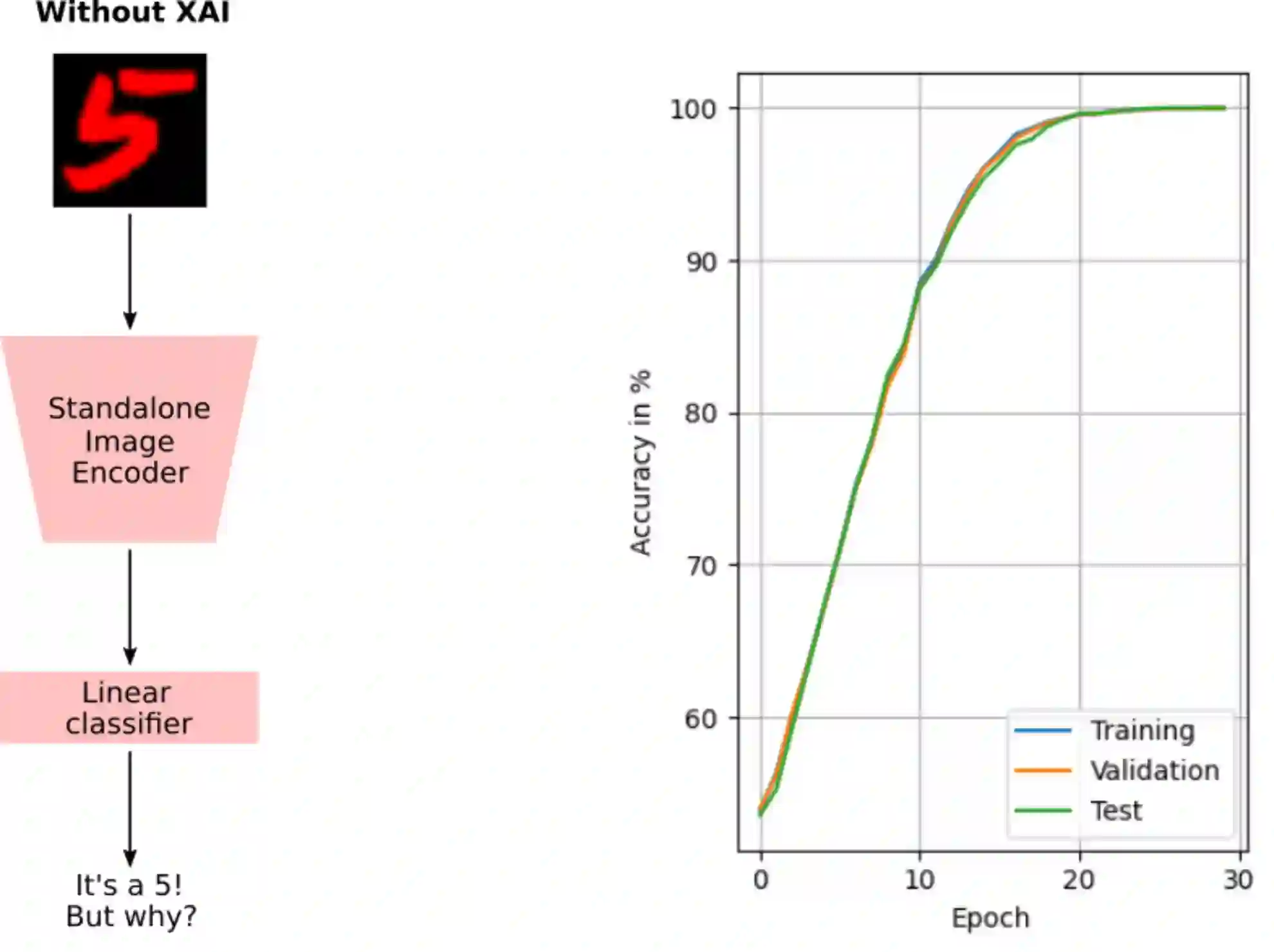
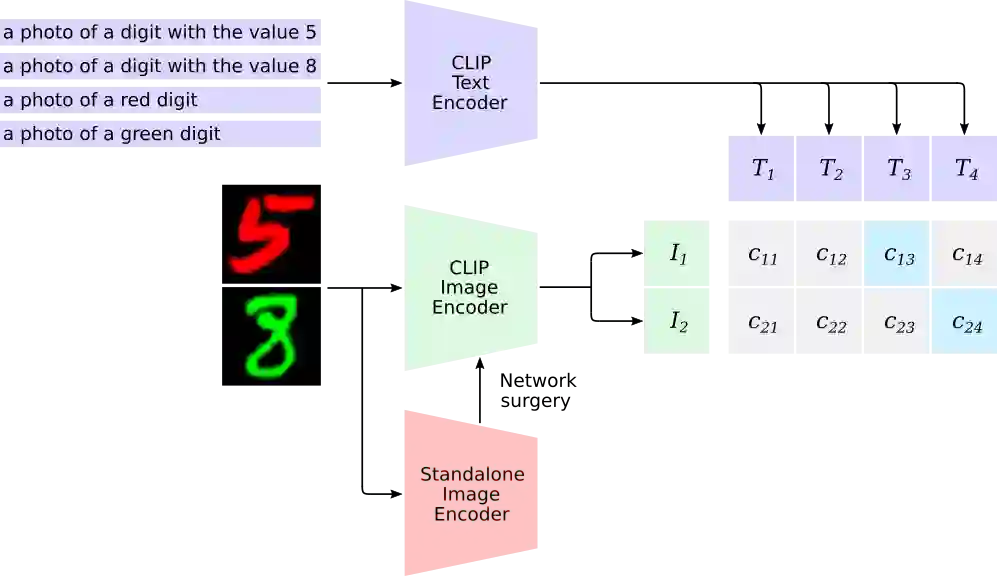
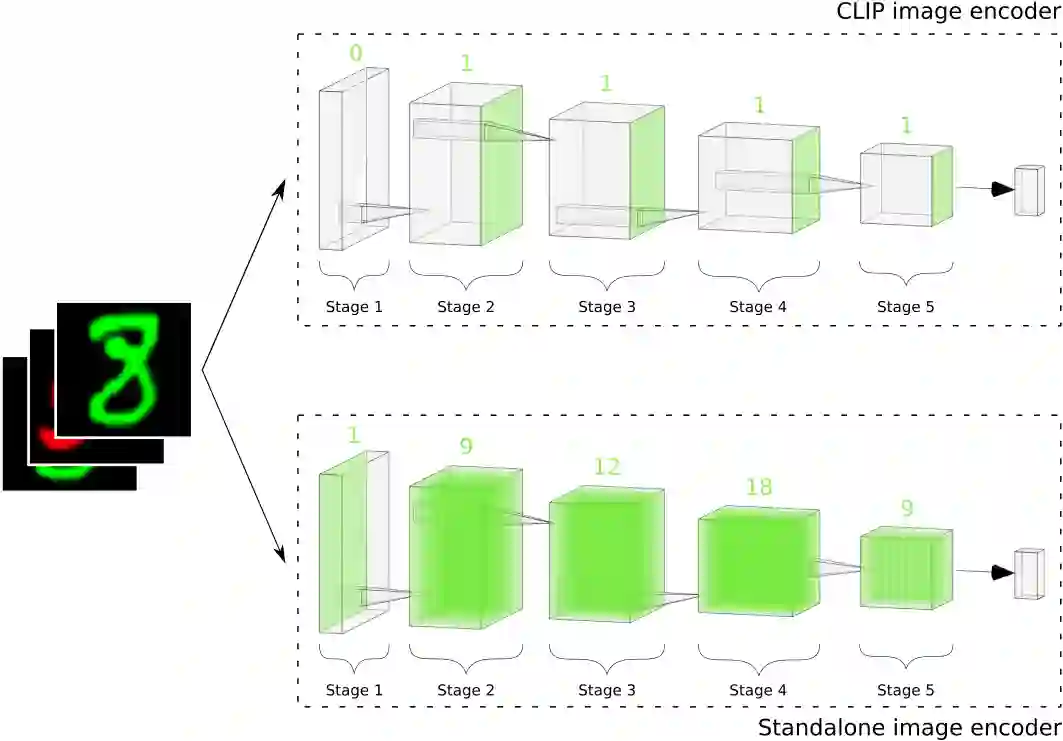
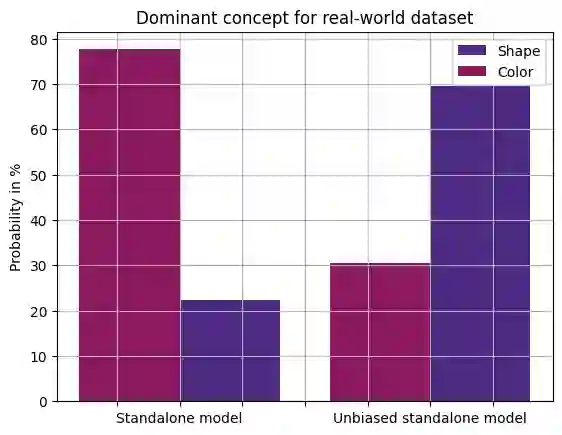
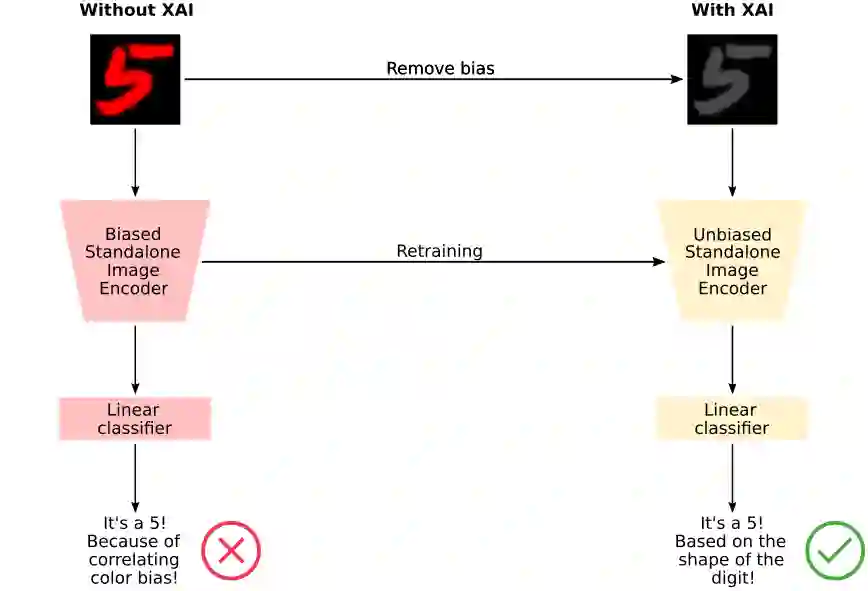
Robustness has become one of the most critical problems in machine learning (ML). The science of interpreting ML models to understand their behavior and improve their robustness is referred to as explainable artificial intelligence (XAI). One of the state-of-the-art XAI methods for computer vision problems is to generate saliency maps. A saliency map highlights the pixel space of an image that excites the ML model the most. However, this property could be misleading if spurious and salient features are present in overlapping pixel spaces. In this paper, we propose a caption-based XAI method, which integrates a standalone model to be explained into the contrastive language-image pre-training (CLIP) model using a novel network surgery approach. The resulting caption-based XAI model identifies the dominant concept that contributes the most to the models prediction. This explanation minimizes the risk of the standalone model falling for a covariate shift and contributes significantly towards developing robust ML models. Our code is available at https://github.com/patch0816/caption-driven-xai
翻译:鲁棒性已成为机器学习(ML)中最关键的问题之一。解释机器学习模型以理解其行为并提升其鲁棒性的科学领域被称为可解释人工智能(XAI)。针对计算机视觉问题,当前最先进的XAI方法之一是生成显著性图。显著性图突出显示图像中激发机器学习模型最强烈的像素区域。然而,若虚假特征与显著特征在像素空间重叠,这一特性可能产生误导。本文提出一种基于字幕的XAI方法,通过新颖的网络嫁接技术将待解释的独立模型整合至对比语言-图像预训练(CLIP)模型中。由此构建的字幕驱动XAI模型可识别对模型预测贡献最大的主导概念。这种解释方法能有效降低独立模型陷入协变量偏移的风险,对开发鲁棒机器学习模型具有重要贡献。我们的代码发布于https://github.com/patch0816/caption-driven-xai。