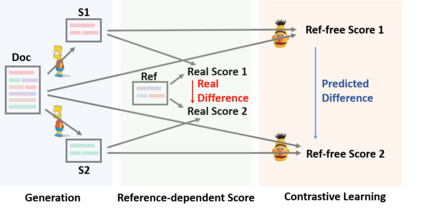
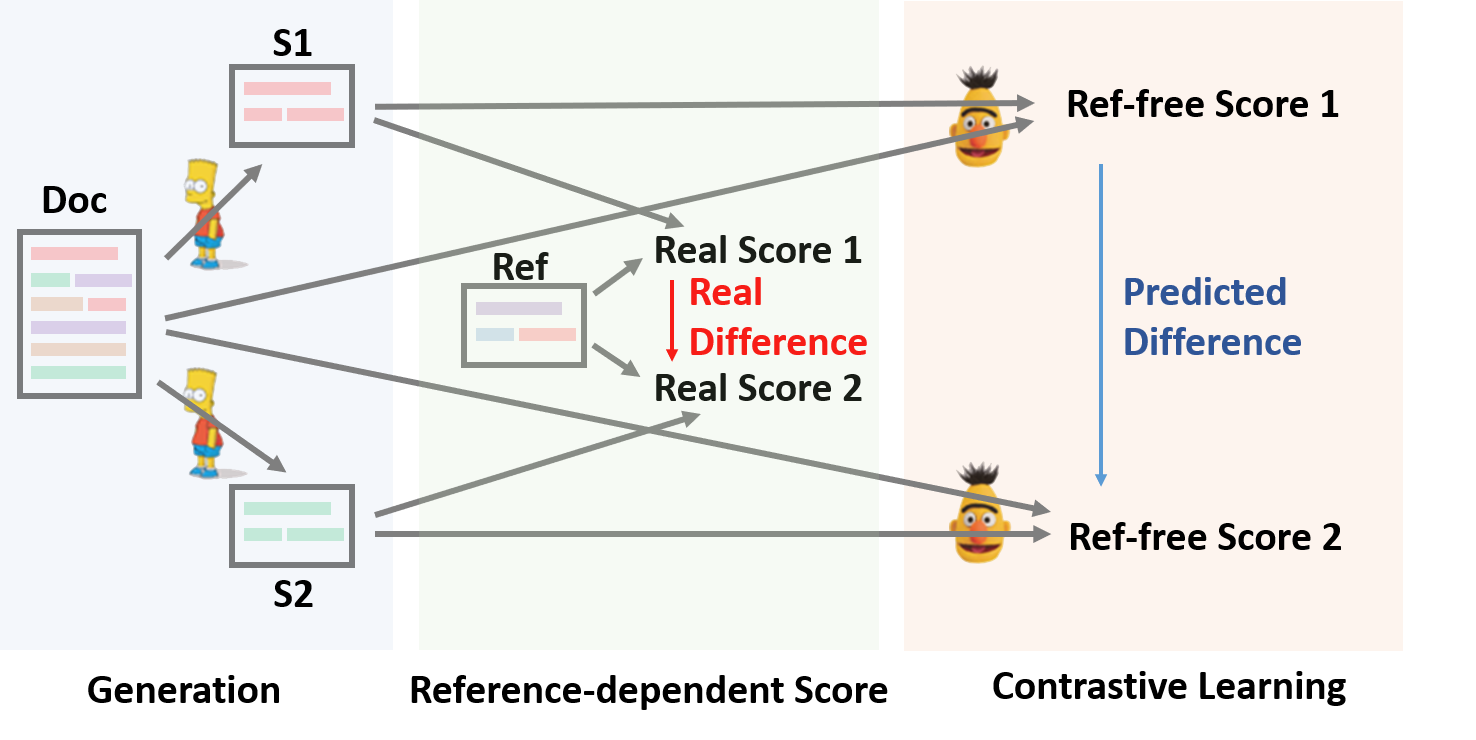
In this paper, we present a conceptually simple while empirically powerful framework for abstractive summarization, SimCLS, which can bridge the gap between the learning objective and evaluation metrics resulting from the currently dominated sequence-to-sequence learning framework by formulating text generation as a reference-free evaluation problem (i.e., quality estimation) assisted by contrastive learning. Experimental results show that, with minor modification over existing top-scoring systems, SimCLS can improve the performance of existing top-performing models by a large margin. Particularly, 2.51 absolute improvement against BART and 2.50 over PEGASUS w.r.t ROUGE-1 on the CNN/DailyMail dataset, driving the state-of-the-art performance to a new level. We have open-sourced our codes and results: https://github.com/yixinL7/SimCLS. Results of our proposed models have been deployed into ExplainaBoard platform, which allows researchers to understand our systems in a more fine-grained way.
翻译:在本文中,我们提出了一个概念简单、经验上强大的抽象总结框架,即SimCLS。 SimCLS通过将文本生成作为无参考评价问题(即质量估计),并辅之以对比性学习,可以弥合目前占主导地位的顺序至顺序学习框架所产生的学习目标和评价指标之间的差距。实验结果表明,由于对现有顶层分层系统稍作修改,SimCLS能够大大改善现有顶级模型的性能。特别是,在CNN/DailyMail数据集中,与BART和PEGASUS w.r.t ROUGE-1相比,SimCLS可以绝对改进2.51和2.50,将最新业绩提高到新的水平。我们公开提供了我们的代码和结果:https://github.com/yixinL7/SimCLS。我们提出的模型的结果被应用到ExleaBoard平台,使研究人员能够更精确地理解我们的系统。