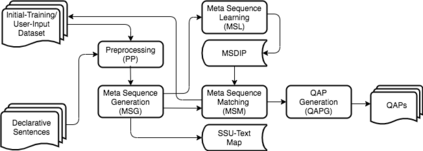
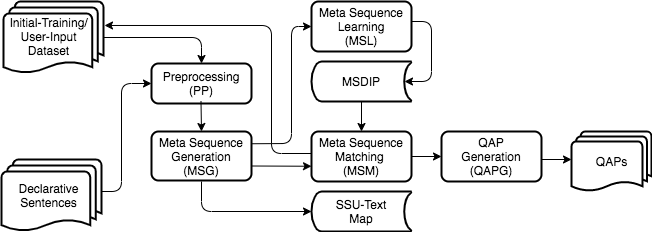
Creating multiple-choice questions to assess reading comprehension of a given article involves generating question-answer pairs (QAPs) on the main points of the document. We present a learning scheme to generate adequate QAPs via meta-sequence representations of sentences. A meta sequence is a sequence of vectors comprising semantic and syntactic tags. In particular, we devise a scheme called MetaQA to learn meta sequences from training data to form pairs of a meta sequence for a declarative sentence (MD) and a corresponding interrogative sentence (MIs). On a given declarative sentence, a trained MetaQA model converts it to a meta sequence, finds a matched MD, and uses the corresponding MIs and the input sentence to generate QAPs. We implement MetaQA for the English language using semantic-role labeling, part-of-speech tagging, and named-entity recognition, and show that trained on a small dataset, MetaQA generates efficiently over the official SAT practice reading tests a large number of syntactically and semantically correct QAPs with over 97\% accuracy.
翻译:创建多种选择问题以评估对特定文章的理解理解,涉及在文件的要点上生成问答对等(QAPs),我们提出了一个学习计划,通过句子的元顺序表示生成适当的QAPs。元序列是一个矢量序列,由语义标签和合成标签组成。特别是,我们设计了一个名为MetaQA的计划,从培训数据中学习元序列,形成声明性句子和相应审讯性句子的元序列。在给定的宣告性句子上,训练有素的MetaQA模型将其转换为元序列,找到匹配的MD,并使用相应的MIS和输入句生成QAPs。我们用语语标注、部分语音标签和名称实体识别,并显示在小型数据集上受过培训的MetQA在官方SAT练习中产生了大量精度和语义正确的QAPs,且精确度超过97。