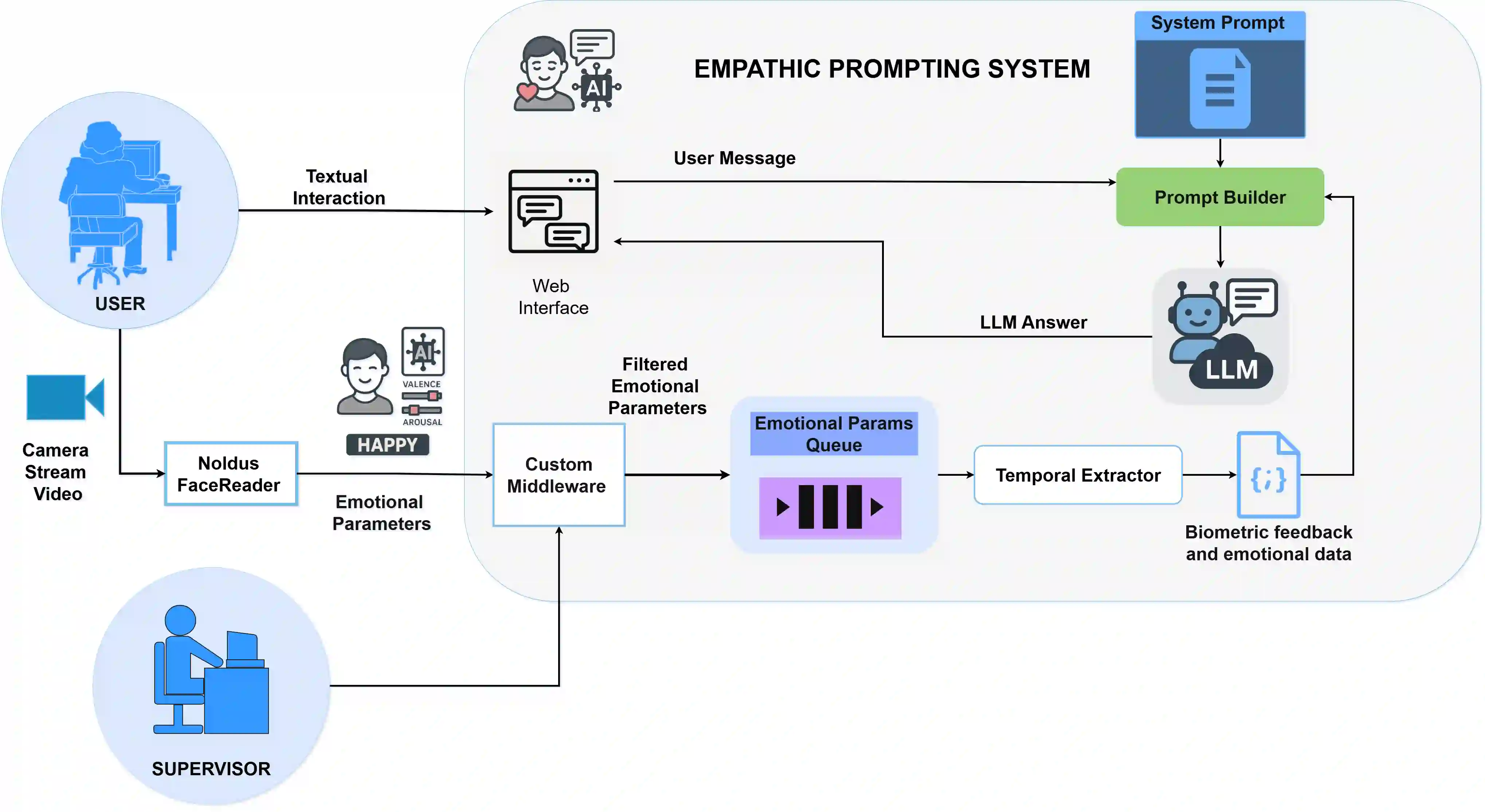
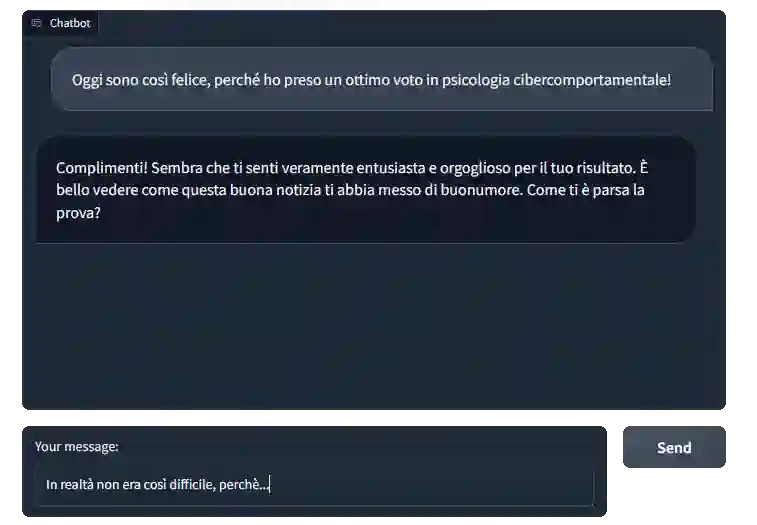
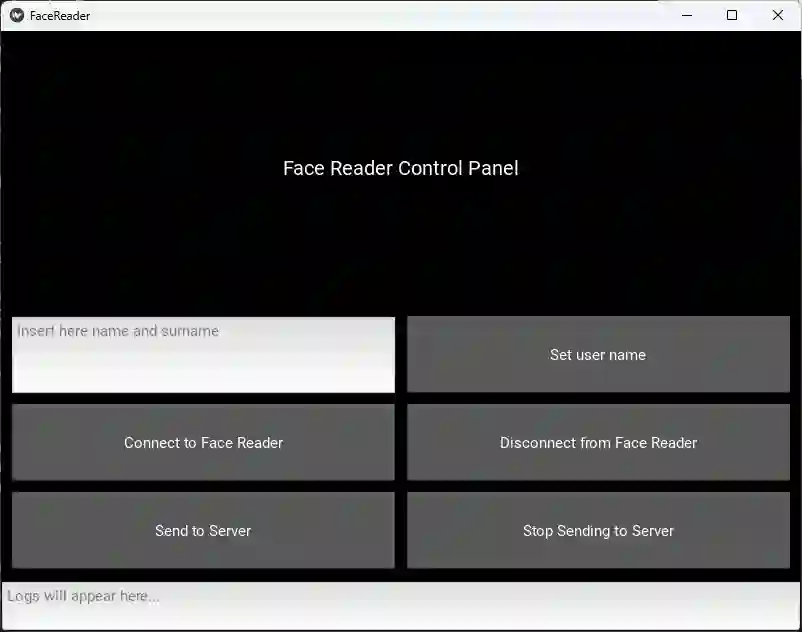
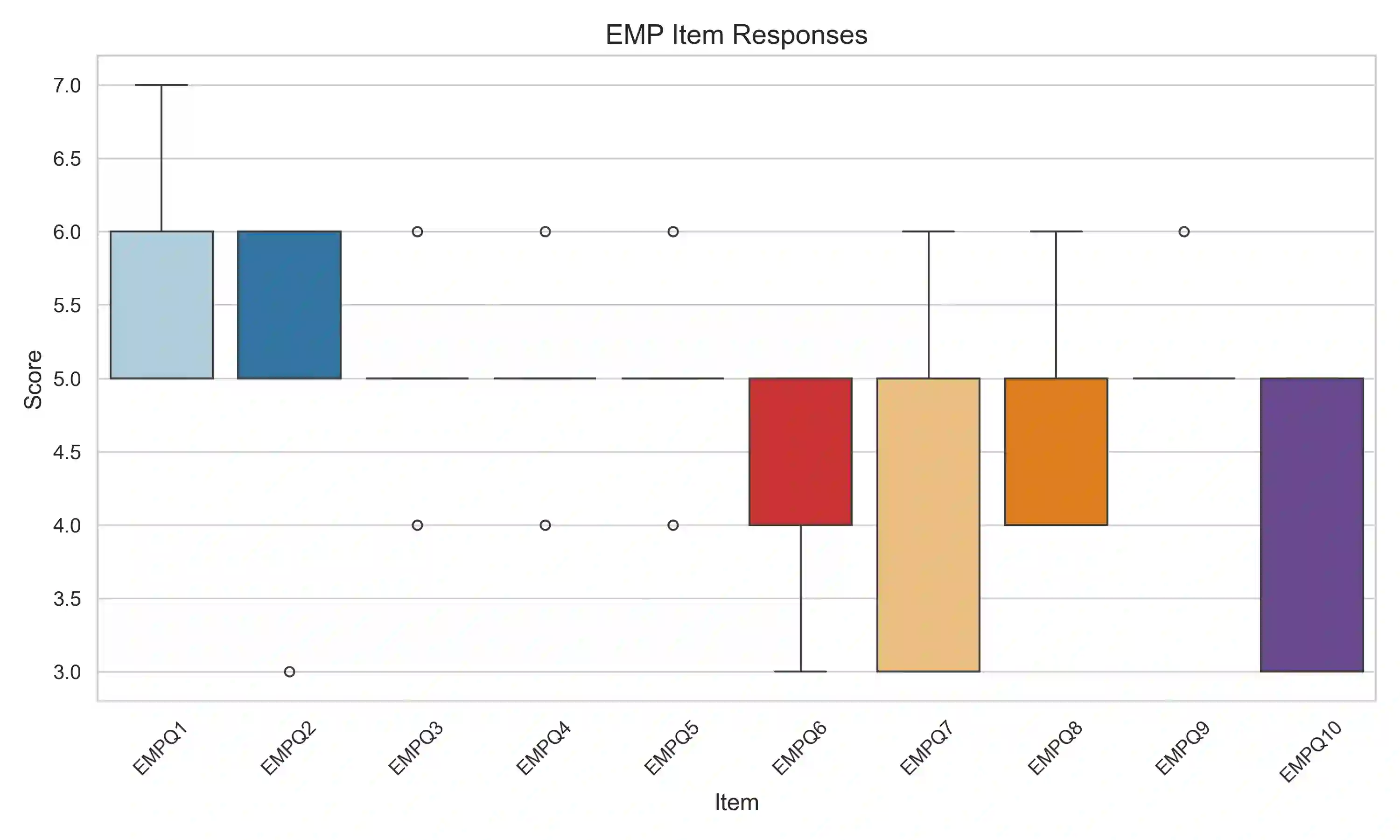
We present Empathic Prompting, a novel framework for multimodal human-AI interaction that enriches Large Language Model (LLM) conversations with implicit non-verbal context. The system integrates a commercial facial expression recognition service to capture users' emotional cues and embeds them as contextual signals during prompting. Unlike traditional multimodal interfaces, empathic prompting requires no explicit user control; instead, it unobtrusively augments textual input with affective information for conversational and smoothness alignment. The architecture is modular and scalable, allowing integration of additional non-verbal modules. We describe the system design, implemented through a locally deployed DeepSeek instance, and report a preliminary service and usability evaluation (N=5). Results show consistent integration of non-verbal input into coherent LLM outputs, with participants highlighting conversational fluidity. Beyond this proof of concept, empathic prompting points to applications in chatbot-mediated communication, particularly in domains like healthcare or education, where users' emotional signals are critical yet often opaque in verbal exchanges.
翻译:本文提出共情提示,一种用于多模态人机交互的新型框架,该框架通过隐式非语言上下文增强大语言模型对话。系统集成商用面部表情识别服务以捕捉用户情绪线索,并将其作为上下文信号嵌入提示过程。与传统多模态界面不同,共情提示无需用户显式控制,而是将情感信息无感知地融入文本输入,以实现对话连贯性与流畅性对齐。该架构采用模块化可扩展设计,支持集成额外非语言模块。我们描述了通过本地部署DeepSeek实例实现的系统设计,并报告了初步服务与可用性评估(N=5)。结果表明非语言输入能持续整合为连贯的大语言模型输出,参与者特别强调了对话流畅性。除概念验证外,共情提示在聊天机器人中介的通信中具有应用潜力,尤其在医疗或教育等领域,这些领域中用户情绪信号至关重要却在言语交流中常难以显化。