成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
人工智能
关注
49289
人工智能(Artificial Intelligence, AI )
是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。 人工智能是计算机科学的一个分支。
综合
百科
VIP
热门
动态
论文
精华
呼吁暂停 GPT-5 研发的马斯克,转身抢购 1 万个 GPU,为 Twitter 大模型做准备!
CSDN
23+阅读 · 2023年4月12日
马斯克离开OpenAI内幕:大权独揽想法被拒,说好的10亿美元也打了水漂
机器之心
14+阅读 · 2023年4月10日
【2023新书】医学影像人工智能前沿,300页pdf
专知
32+阅读 · 2023年4月9日
博士申请 | 香港科技大学陈浩老师招收AI医疗方向全奖博士/博后/RA/实习生
PaperWeekly
4+阅读 · 2023年4月6日
【2023新书】AI4Science,人工智能促进科学发现,134页pdf
专知
60+阅读 · 2023年4月5日
《利用边缘高性能计算 (HPC) 加速战术决策过程》美国陆军,43页报告
专知
109+阅读 · 2023年4月5日
重磅!斯坦福HAI《2023人工智能指数报告》出炉,386页pdf了解AI十大态势进展(附中文版报告下载)
专知
24+阅读 · 2023年4月4日
OpenAI超级对话模型ChatGPT发布!智能回答堪比雅思口语满分案例
新智元
29+阅读 · 2022年12月1日
博士申请 | 香港科技大学郭毅可教招收创造性人工智能方向博士/博后/RA
PaperWeekly
3+阅读 · 2022年12月1日
当 AI 踢进世界杯......
CSDN
3+阅读 · 2022年12月1日
这场版权官司,可能影响人工智能的未来!
新智元
1+阅读 · 2022年11月28日
博士申请 | 香港科技大学陈浩老师招收人工智能医疗方向全奖博士/博后
PaperWeekly
4+阅读 · 2022年11月27日
文末送书 | 从0到1全面探讨分布式人工智能:理论、算法与实践
PaperWeekly
10+阅读 · 2022年11月27日
AI的未来不是大模型,也不是端到端:Meta向我们证明了这一点
机器之心
15+阅读 · 2022年11月26日
北京/杭州内推 | 阿里巴巴AAIG团队招聘计算机视觉算法实习生
PaperWeekly
2+阅读 · 2022年11月25日
参考链接
父主题
微软亚洲研究院上海人工智能组
深圳瑞德林生物技术有限公司
计算机科学
子主题
Theodore Summe
CoNLL
JETAI
Machine Vision and Applications
AI与农业
人工智能安全
NeurIPS
PRICAI
汤普森抽样
PAA
机器学习
IROS
ICPR
人工智能从事者
AI与金融
IJUFKS
因果推理
Computational Intelligence
IVC
IJAR
IJCNN
IET-CVI
EMNLP
IJCV
ICCBR
Computational Linguistics
博弈论
JAIR
KR
Natural Computing
KC Tung
TAP
AI与公安
TASLP
ILP
计算机视觉
Evolutionary Computation
IET Signal Processing
Applied Intelligence
模式识别
TG
IJPRAI
TFS
ACCV
NCA
FG
AI与城市
Computer Speech and Language
JSLHR
ICDAR
Neural Computation
AIM
ACML
Connection Science
IJCIA
CVPR
TEC
ICONIP
JMLR
语音技术
ICB
AI
NPL
自然语言处理
TAC
ICTAI
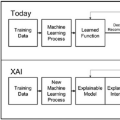
可解释人工智能
Zeqi Gu
ESWA
IEEE Transactions on Cybernetics
CVIU
Neural Networks
Sarah Bird
数据挖掘
Robot
TSLP
AISTATS
AI与交通
AI + X
DSS
ECAI
TALLIP
NLE
人工智能指数
Responsible AI
EAAI
BMVC
Machine Translation
机器人
Fuzzy Sets and Systems
IJNS
TPAMI
PPSN
人工智能产品以及公司
WI
Machine Learning
Expert Systems
AI与军事
ICAPS
IJDAR
IJIS
KSEM
机器狗
Soft Computing
人工智能领域相关会议
Journal of Automated Reasoning
ALT
Pattern Recognition
智慧城市
Artificial Life
TNNLS
COLT
NLPCC
AAMAS
AI与医学
Gemini
ChatGPT
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top