成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
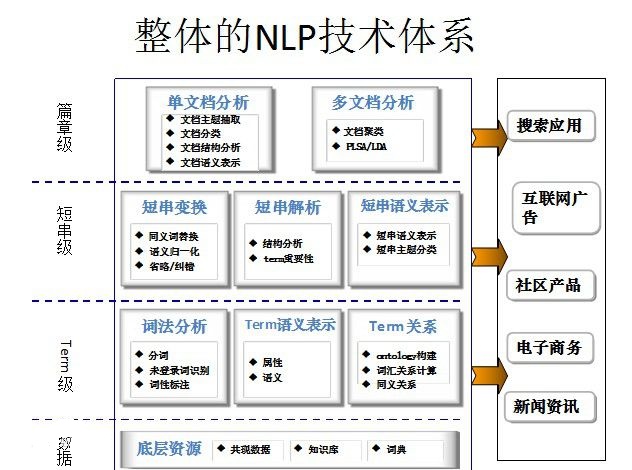
自然语言处理应用研究
关注
981
综合
百科
VIP
热门
动态
论文
精华
高效利用多级用户意图,港科大、北大等提出会话推荐新模型Atten-Mixer
机器之心
3+阅读 · 2023年4月13日
GlobalWoZ: 面向全球通用的人机对话系统——快速构建多语对话能力初探
PaperWeekly
1+阅读 · 2022年11月17日
EMNLP 2022 | SentiWSP: 基于多层级的情感感知预训练模型
PaperWeekly
4+阅读 · 2022年10月28日
大厂都在“卷”的推荐系统还有进步空间吗?看青橙奖得主怎么说
CSDN
1+阅读 · 2022年10月25日
推荐算法为什么越来越懂你?来听青橙奖得主给你唠背后的技术
量子位
0+阅读 · 2022年10月25日
小扎亲自演示首个「闽南语」翻译系统!主攻3000种无文字的语言
新智元
0+阅读 · 2022年10月24日
CIKM 2022最佳论文:快手提出移动端实时短视频推荐系统
PaperWeekly
2+阅读 · 2022年10月23日
2022年,大厂都在“卷”的推荐系统还有进步空间吗?
PaperWeekly
0+阅读 · 2022年10月21日
移动端部署推荐系统:快手获数据挖掘顶会CIKM 2022最佳论文
机器之心
0+阅读 · 2022年10月21日
推荐系统多任务学习上分技巧
机器学习与推荐算法
0+阅读 · 2022年10月19日
深度学习推荐系统入门教程(附开源项目)
机器学习与推荐算法
3+阅读 · 2022年10月18日
【2022新书】个性化机器学习: 推荐系统,341页pdf,附201页slides
专知
9+阅读 · 2022年10月14日
RecSys2022 | 多阶段推荐系统的神经重排序教程
机器学习与推荐算法
0+阅读 · 2022年10月12日
如何向大模型注入知识?达摩院通义对话模型SPACE系列探索
机器之心
0+阅读 · 2022年10月11日
悉尼科技大学最新可信推荐综述,提出可信推荐生态系统并概括9个方面的发展
机器学习与推荐算法
0+阅读 · 2022年10月11日
参考链接
父主题
自然语言处理
子主题
文本聚类
推荐系统
信息抽取
Fattane Zarrinkalam
情感分析
简繁转换
信息检索
机器翻译
社会媒体处理
文本分类
人机对话
机器阅读理解
自动文摘
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top