

摘要—三维场景生成旨在合成具备空间结构、语义意义和照片级真实感的环境,广泛应用于沉浸式媒体、机器人、自动驾驶和具身智能等领域。早期基于程序规则的方法具有良好的可扩展性,但在多样性方面受到限制。近年来,深度生成模型(如生成对抗网络、扩散模型)和三维表示方法(如NeRF、三维高斯表示)的进展,使得模型能够学习真实世界的场景分布,从而在逼真度、多样性和视角一致性方面取得显著提升。扩散模型等新兴方法通过将三维场景合成重新表述为图像或视频生成问题,进一步拉近了三维合成与照片级真实感之间的距离。 本综述系统地回顾了当前主流的三维场景生成方法,将其划分为四大范式:程序生成、基于神经三维表示的生成、基于图像的生成和基于视频的生成。我们分析了各类方法的技术基础、权衡因素及代表性成果,并回顾了常用数据集、评估协议以及下游应用场景。最后,我们讨论了当前在生成能力、三维表示、数据与标注、评估机制等方面所面临的关键挑战,并展望了若干前沿方向,包括更高的生成保真度、具备物理意识和交互能力的生成方法,以及感知与生成一体化的统一模型。 本综述梳理了三维场景生成领域的最新研究进展,强调了生成式人工智能、三维视觉与具身智能交叉融合中的潜力方向。我们同时维护了一个持续更新的项目页面以跟踪最新进展:https://github.com/hzxie/Awesome-3D-Scene-Generation。 关键词—三维场景生成,生成模型,人工智能生成内容,三维视觉
引言
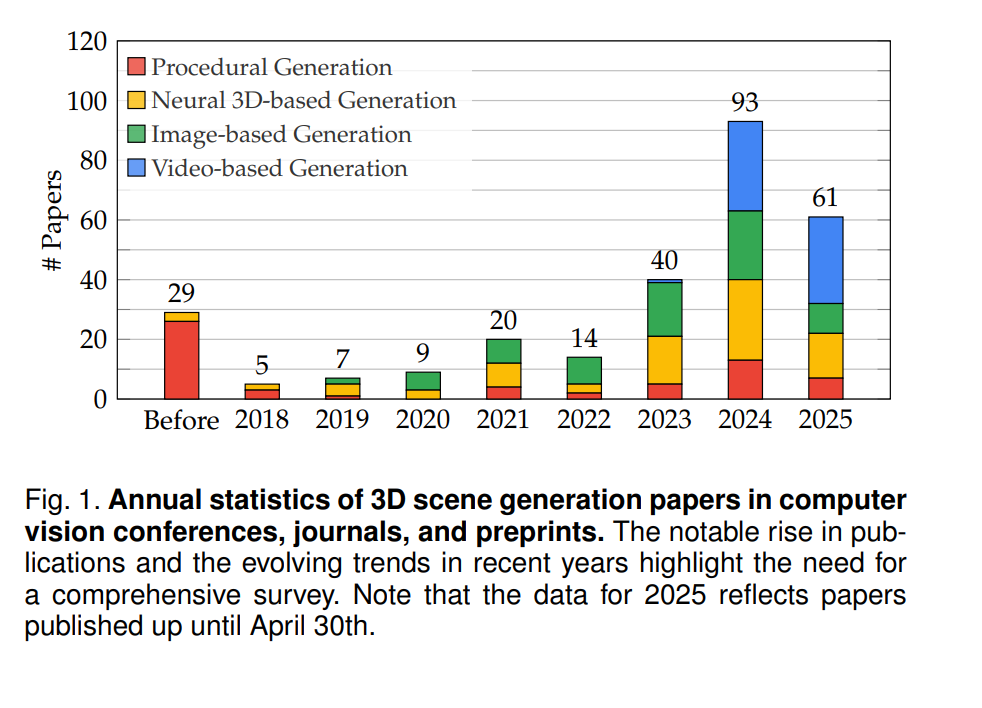
三维场景生成的目标是构建具备空间结构、语义信息和视觉真实感的三维环境。作为计算机视觉领域的重要基石,该技术支撑着众多应用场景,包括沉浸式影视制作 [1], [2]、开放世界游戏设计 [3], [4], [5]、建筑可视化 [6], [7],以及增强/虚拟现实(AR/VR)[8], [9], [10]、机器人仿真 [11], [12] 和自动驾驶 [13], [14] 等。在更深层次上,三维场景生成对于推动具身人工智能(Embodied AI)[15], [16], [17] 和世界模型(World Models)[18], [19], [20] 的发展至关重要,这些模型依赖于多样、高质量的场景进行学习与评估。逼真的场景合成能力有助于提升智能体的导航、交互与适应能力,从而推动自主系统和虚拟仿真技术的发展。 如图1所示,三维场景生成近年来获得了显著关注。早期方法依赖于基于规则的程序生成与人工设计的素材资源 [21], [22],在游戏设计 [23]、城市规划 [24], [25] 和建筑建模 [26], [27] 中具备良好的可控性与可扩展性。然而,这些方法依赖预定义规则与确定性算法,导致生成结果缺乏多样性,且在创建真实或复杂场景时需大量人工干预 [28]。 深度生成模型的兴起(如生成对抗网络 [29] 与扩散模型 [30])使神经网络能够学习真实世界的空间分布,从而合成多样且逼真的空间结构。结合NeRF [31] 和三维高斯表示 [32] 等三维表达技术的突破,基于神经网络的三维生成方法在几何精度、渲染效率与视角一致性等方面均取得显著提升,特别适用于构建具备照片真实感的虚拟环境。 从单张图像出发,基于图像的场景生成方法借助相机姿态变换与图像扩展技术,逐步生成连续视角 [33], [34] 或局部全景场景 [35], [36]。随着视频扩散模型的快速发展 [37], [38],视频生成的质量显著提升,从而激发了过去两年中三维场景生成的研究热潮。这类方法将三维场景生成建模为视频生成问题,通过时序建模提高视角一致性 [39]。动态三维表达 [40], [41] 的引入进一步推动了沉浸式动态场景的合成 [42], [43]。 与三维对象或虚拟角色的生成相比,三维场景生成在多个维度上面临更大挑战: 1. 规模:对象和角色通常位于固定、有限的空间范围内,而场景需容纳多个实体并适应更大且变化多样的空间尺度; 1. 结构复杂性:场景涉及多样对象间复杂的空间与语义关系,模型必须确保结构上的功能一致性与整体的合理性; 1. 数据稀缺性:尽管面向对象或角色的生成已有大量标注数据集,但高质量的三维场景数据集仍稀缺且成本高昂; 1. 精细控制:场景生成往往要求用户对对象布局、功能分区和风格等属性进行控制,而当前方法在灵活性与可解释性方面仍有限。
尽管三维场景生成取得了迅速进展,目前尚缺乏一篇系统性综述文献来对现有方法进行分类、挑战总结与未来展望。已有综述多聚焦于狭窄领域,例如程序生成 [44], [45]、室内场景 [46], [47]、自动驾驶 [48] 以及文本驱动生成 [49], [50],视角较为局限。更广泛的综述聚焦于通用三维或四维内容生成 [51]–[56],通常仅将场景生成作为附属内容,导致覆盖面零散。例如,一些研究专注于扩散模型 [55]、文本驱动场景生成 [52] 或四维生成 [56],而忽视了如三维高斯表示 [51]、图像序列 [53], [54]、以及程序与视频生成范式 [51], [53], [54] 等关键组成。世界模型相关综述 [18], [57], [58] 主要聚焦于驾驶场景下的视频预测,提供的视角较为片面。因此,迫切需要一份全面、系统、紧跟进展的综述,对三维场景生成进行整理与分析。
主要贡献
本综述系统梳理了三维场景生成领域的最新研究进展。我们将现有方法归类为四大类型:程序生成、基于神经三维表达的生成、基于图像的生成与基于视频的生成,并分析了各类方法的核心范式与技术权衡。此外,我们回顾了在场景编辑、人-场交互、具身智能、机器人与自动驾驶等下游任务中的应用。我们还梳理了常见的三维场景表达方式、数据集与评估协议,并指出当前在生成能力、可控性与真实感方面的限制。最后,我们探讨了未来的发展方向,包括更高保真度、具物理意识与交互性的生成方法,以及感知-生成一体化的模型。
研究范围
本综述主要关注基于三维表达的三维场景生成方法。这些生成方法的目标是合成多样的三维场景,而传统的三维重建方法仅能从给定输入重建单一场景。关于三维重建的综述可参考 [59], [60]。此外,本综述不涵盖通用的视频生成方法 [38], [61] 与三维对象生成方法 [62]–[64],尽管它们在某些场景中具备一定的三维生成能力。本文旨在补充现有关于三维生成模型的综述 [51]–[55],填补对三维场景生成系统性总结的空白。
结构安排
本综述的结构如图2所示。第2节介绍基本概念,包括任务定义、三维场景表达方式与生成模型基础。第3节根据方法类别进行划分,详述各类方法的范式、优劣势与技术路线。第4节介绍常用数据集与评估指标。第5节回顾各类三维场景生成的下游任务。第6节则讨论当前面临的挑战、未来的发展方向,并总结全文。
