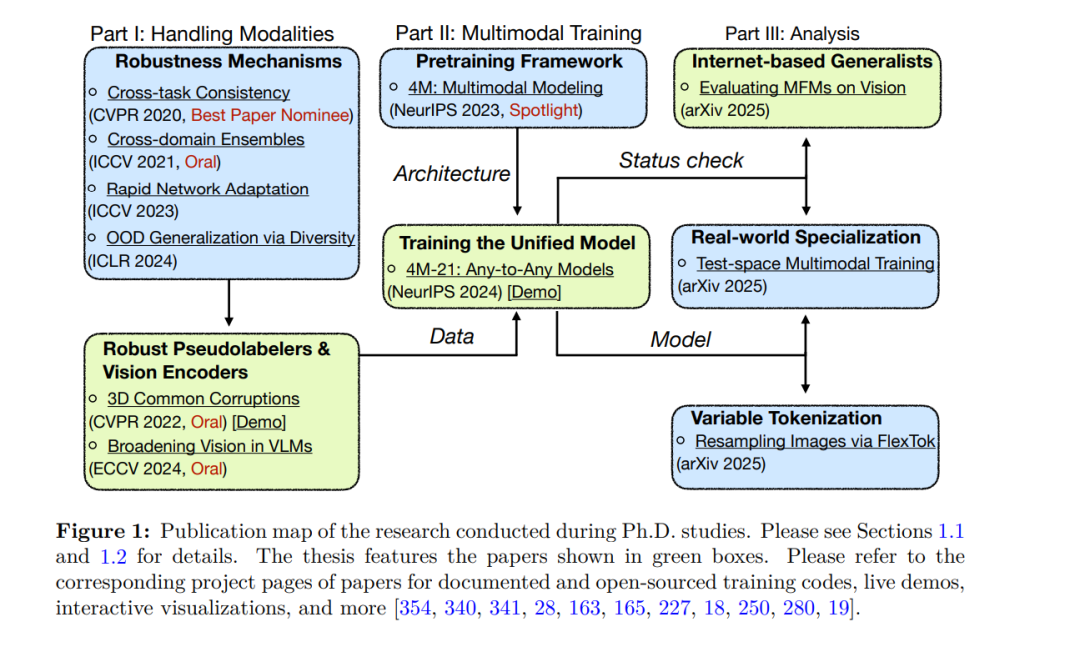
拥有一个能够处理广泛且多样任务和模态的神经网络一直是长期以来的目标。这样的模型带来了诸多显著优势,如测试时的计算效率、模态融合以及模型规模的缩减。本论文的目标是推动统一的多模态基础模型的构建,使其能够处理多种输入(如图像、文本、三维、语义以及其他感知数据),以解决包括场景理解、生成和检索在内的各种现实任务。 我们的方法应对了三大核心挑战:(1)获取多样且高质量的训练数据;(2)构建可扩展的训练框架;(3)评估与基准测试。 第一个挑战是多模态训练中标注数据的稀缺性。作为补救方法,可以利用现有神经网络生成的伪标签来为不同模态生成数据,从而实现可扩展的数据构造。然而,这种方法在现实世界中难以奏效,原因在于这些模型在实际环境中的脆弱性。为应对这一问题,论文的第一部分我们构建了鲁棒性机制,以开发强大的伪标注网络,并充分利用现成的预训练模型。这些机制旨在应对现实世界中的分布偏移问题,具体包括:
现实数据增强(3D 通用扰动), 强制一致性约束(跨任务一致性), 利用自监督领域(跨领域集成)和预训练视觉骨干(BRAVE)进行多样化集成, 通过误差反馈进行测试时自适应(快速网络适配)。
在此基础上,论文第二部分将上述伪标签器和强大的视觉编码器生成的数据整合进一个统一的训练框架(4M)。通过基于掩码建模的多模态训练目标以及“任意对任意(any-to-any)”的模型架构,我们将训练扩展到数十个任务和模态,及数十亿模型参数的规模。这一方法被命名为 4M-21,实现了多样的能力,包括强大的即用型视觉性能、任意条件生成与可控生成、跨模态检索以及多感知融合,全部集成于一个模型中。 最后,我们对所构建模型的能力进行了定性与定量分析,覆盖广泛的任务、数据集和基准测试。同时,我们还对当前主流的闭源多模态基础模型(如 GPT-4o、Gemini 1.5 Pro、Claude 3.5 Sonnet)在若干经典计算机视觉任务(如语义分割、目标检测、深度估计)上的表现进行了“状态检验”,通过开发提示链技术,使其能与专业视觉模型进行直接对比。我们发现,这些模型虽具备可观的通用能力,但在所有任务中均未达到最先进水平,表明模型发展仍有广阔的提升空间。