主题: Graph-based Methods in Pattern Recognition and Document Image Analysis
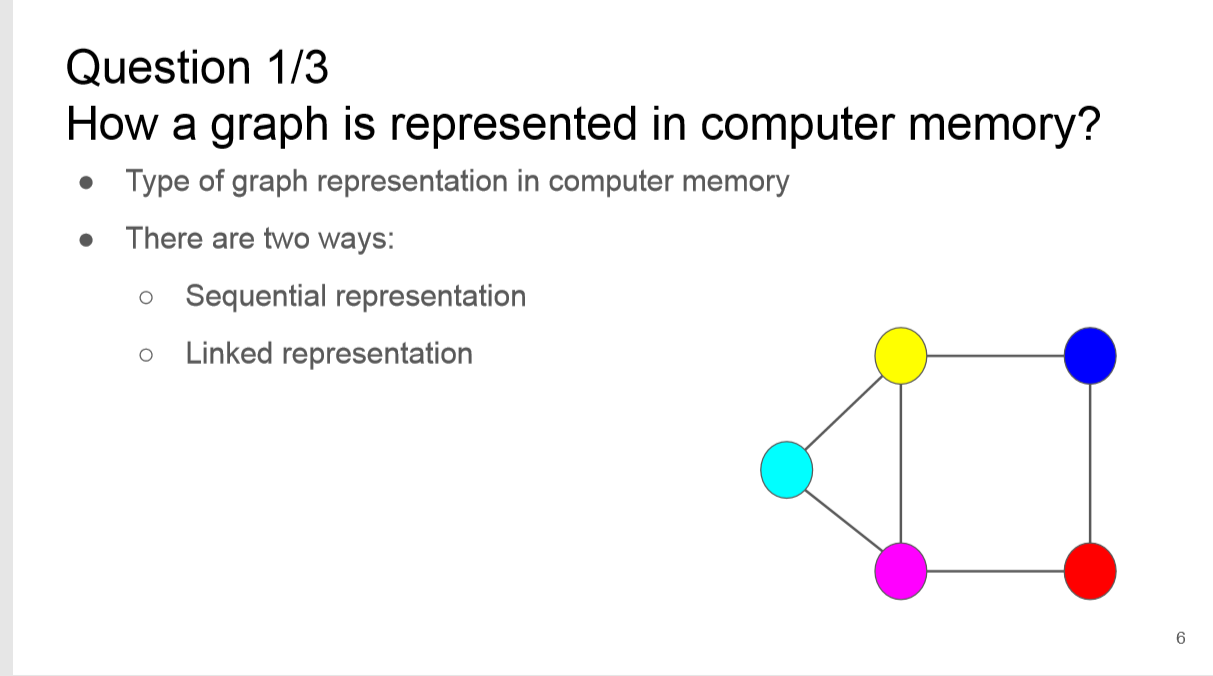
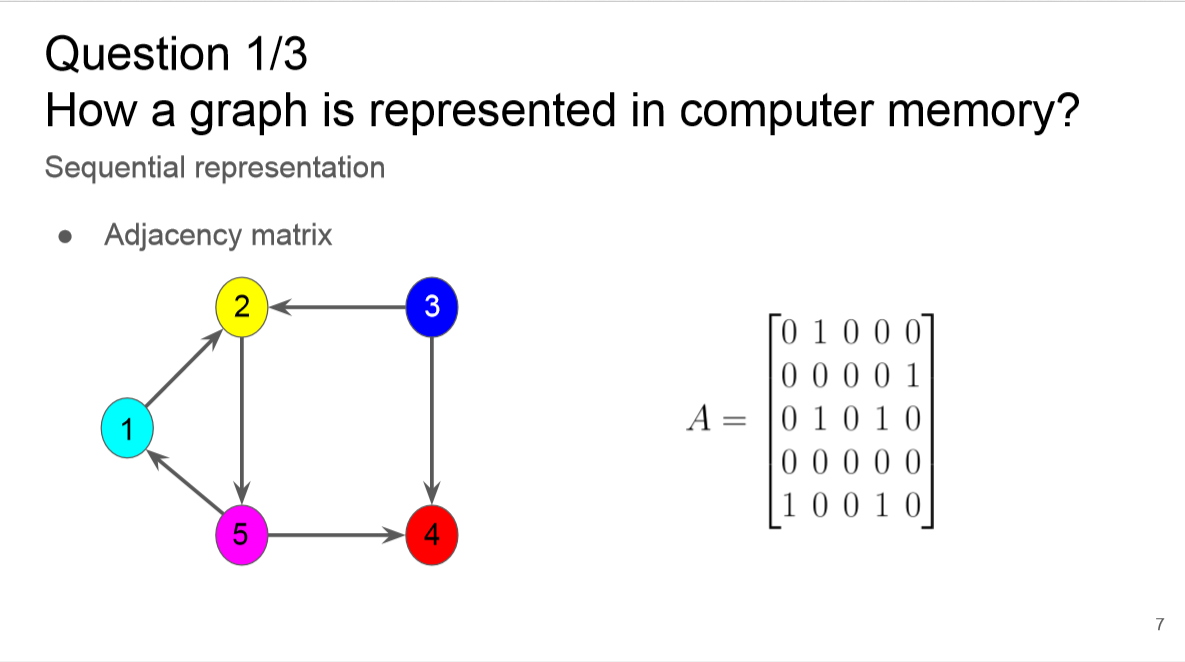
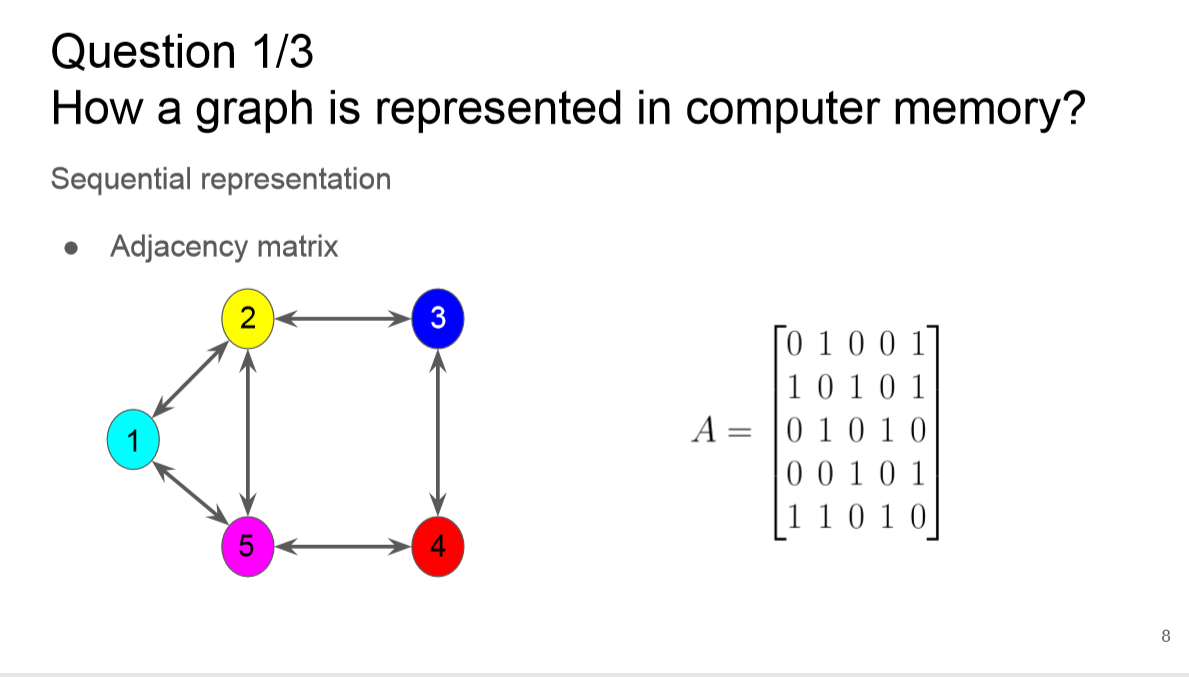
简介: 模式识别和文档图像分析中的许多任务被公式化为图形匹配问题。尽管问题具有NP难性,但快速准确的收敛已在模式识别的广泛应用中取得了重大进展。因此,学习基于图的表示形式和相关技术是真正兴趣。在本教程中,我们将介绍用于获得不同应用程序的图形表示的许多方法。之后,我们将解释用于在图域中识别,分类,检测和许多其他任务的基于图的不同算法,方法和技术。我们将介绍最近的趋势,包括图卷积网络和图中的消息传递,重点介绍在各种模式识别问题中的应用,例如化学分子分类和网络图形表示中的检测。此外,除了这些算法在文档图像分析和识别(尤其是模式识别)领域的不同应用之外,还将提供相关经验。
嘉宾介绍: DUTTA Anjan是位于巴塞罗那计算机视觉中心的P-SPHERE项目下的Marie-Curie博士后。他于2014年获得巴塞罗那自治大学(UAB)的计算机科学博士学位。他是IJCV,IEEE TCYB,IEEE TNNLS,PR,PRL等期刊的定期审稿人,并经常担任BMVC,ICPR,ACPR和ICFHR等各种科学会议的程序委员会委员。他最近的研究兴趣围绕视觉对象的基于图形的表示和解决计算机视觉,模式识别和机器学习中各种任务的基于图形的算法。
Luqman Muhammad Muzzamil博士是文档图像分析,模式识别和计算机视觉的研究科学家。自2015年11月以来,卢克曼目前在拉罗谢尔大学(法国)的L3i实验室担任研究工程师。Luqman曾在波尔多生物信息学中心(波尔多生物信息中心)担任研究工程师,并在拉罗谢尔大学(法国)的L3i实验室担任Jean-Marc Ogier教授的博士后研究员。 Luqman拥有FrançoisRabelais的图尔大学(法国)和巴塞罗那的Autonoma大学(西班牙)的计算机科学博士学位。他的博士学位论文由Jean-Yves Ramel教授和Josep Llados教授共同指导。他的研究兴趣包括结构模式识别,文档图像分析,基于相机的文档分析和识别,图形识别,机器学习,计算机视觉,增强现实和仿生学。