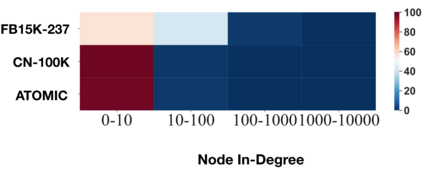
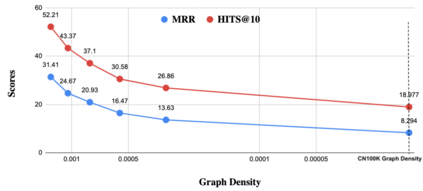
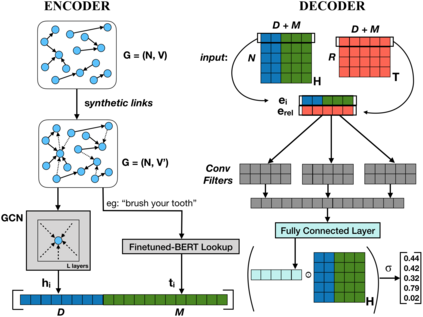
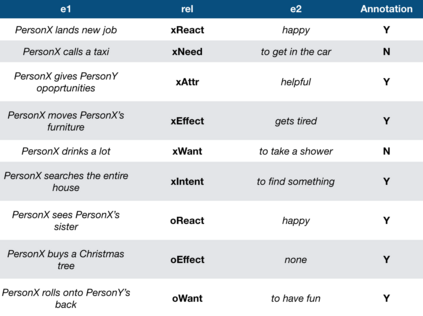
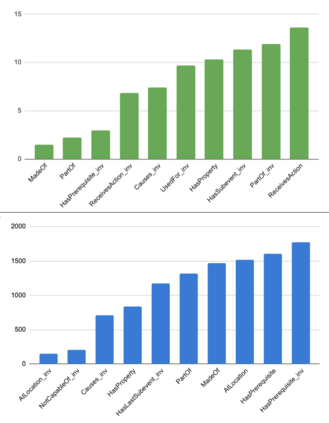
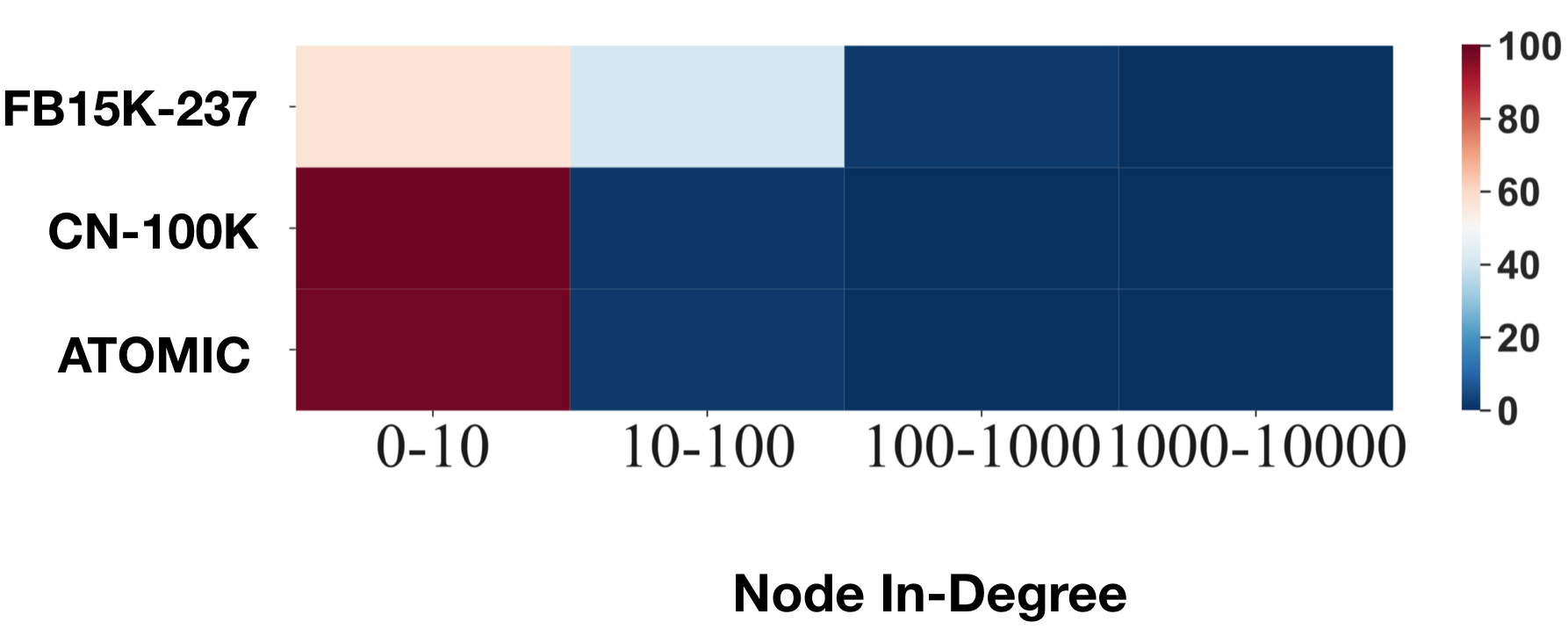
Automatic KB completion for commonsense knowledge graphs (e.g., ATOMIC and ConceptNet) poses unique challenges compared to the much studied conventional knowledge bases (e.g., Freebase). Commonsense knowledge graphs use free-form text to represent nodes, resulting in orders of magnitude more nodes compared to conventional KBs (18x more nodes in ATOMIC compared to Freebase (FB15K-237)). Importantly, this implies significantly sparser graph structures - a major challenge for existing KB completion methods that assume densely connected graphs over a relatively smaller set of nodes. In this paper, we present novel KB completion models that can address these challenges by exploiting the structural and semantic context of nodes. Specifically, we investigate two key ideas: (1) learning from local graph structure, using graph convolutional networks and automatic graph densification and (2) transfer learning from pre-trained language models to knowledge graphs for enhanced contextual representation of knowledge. We describe our method to incorporate information from both these sources in a joint model and provide the first empirical results for KB completion on ATOMIC and evaluation with ranking metrics on ConceptNet. Our results demonstrate the effectiveness of language model representations in boosting link prediction performance and the advantages of learning from local graph structure (+1.5 points in MRR for ConceptNet) when training on subgraphs for computational efficiency. Further analysis on model predictions shines light on the types of commonsense knowledge that language models capture well.
翻译:普通知识图(如ATOMIC和概念网)的自动 KB 完成普通知识图(如ATOMIC和概念网)与经过大量研究的常规知识基础(如Freebase)相比,提出了独特的挑战。普通知识图使用自由格式文本代表节点,结果与常规KBs(与Freebase(FB15K-237)相比,在ATOMIC中增加了18个节点)相比,产生了数量级更高的节点。重要的是,这意味着目前的KB完成方法非常稀少,在相对较小的节点上假定了密集连接的图形。在本文件中,我们提出了新的KB完成模型,通过利用节点的结构和语义背景来应对这些挑战。具体地说,我们研究了两个关键想法:(1) 从本地图形结构中学习,使用图形变动网络和自动图形密度,(2) 从经过预先训练的语言模型向知识图表转换到加强知识背景代表性的知识图。我们用这两种来源的信息纳入联合模型的方法,并为KB完成ATOMIIC模型和对精度语言模型的评估提供了第一个经验结果,在概念网中,在概念网中,在比较的预测模型上,在概念图性模型上,在比较精细地分析模型中,用基准模型中,在提高模型上,我们的结果将成果模型分析中,在比较地分析。