
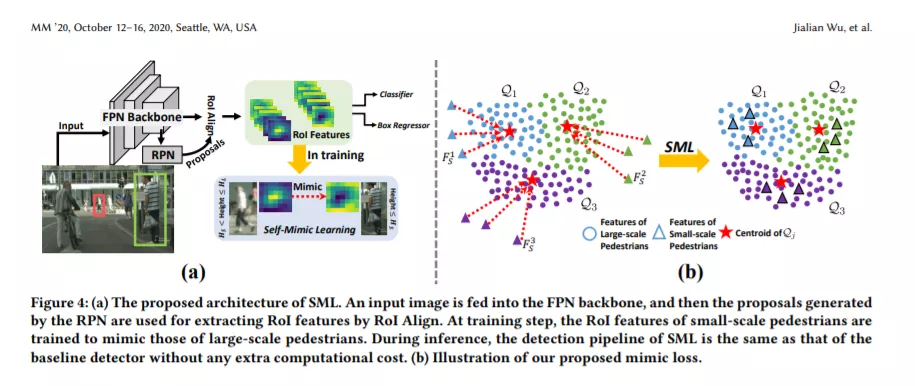
小规模行人的检测是行人检测中最具挑战性的问题之一。由于缺乏视觉细节,小规模行人的表征往往难以从杂乱的背景中分辨出来。在本文中,我们对小规模行人检测问题进行了深入的分析,发现小规模行人的弱表征是导致分类器漏检的主要原因。为了解决这一问题,我们提出了一种新的自模拟学习(SML)方法来提高对小规模行人的检测性能。我们通过模仿大规模行人的丰富表现来增强小规模行人的表现。具体来说,我们设计了一个模拟损失,迫使小规模行人的特征表征接近大规模行人的特征表征。所提议的SML是一个通用组件,可以很容易地合并到单级和两级检测器中,不需要额外的网络层,在推理期间不需要额外的计算成本。在cityperson和Caltech数据集上进行的广泛实验表明,经过模拟损失训练的检测器对小规模行人检测非常有效,并分别在cityperson和Caltech上取得了最好的结果。
https://cse.buffalo.edu/~jsyuan/papers/2020/SML.pdf
成为VIP会员查看完整内容
相关内容
Arxiv
3+阅读 · 2019年3月20日
Arxiv
4+阅读 · 2018年4月2日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年3月20日
Arxiv
4+阅读 · 2018年4月2日