课程名称: CS276: Information Retrieval and Web Search(Spring quarter 2019
课程简介: 信息检索(Information Retrieval)是用户进行信息查询和获取的主要方式,是查找信息的方法和手段。 IR是自然语言处理(NLP)领域中的第一个,并且仍然是最重要的问题之一。 网络搜索是将信息检索技术应用于世界上最大的文本语料库-网络-这是大多数人最频繁地与IR系统交互的区域。
在本课程中,我们将介绍构建基于文本的信息系统的基本和高级技术,包括以下主题:
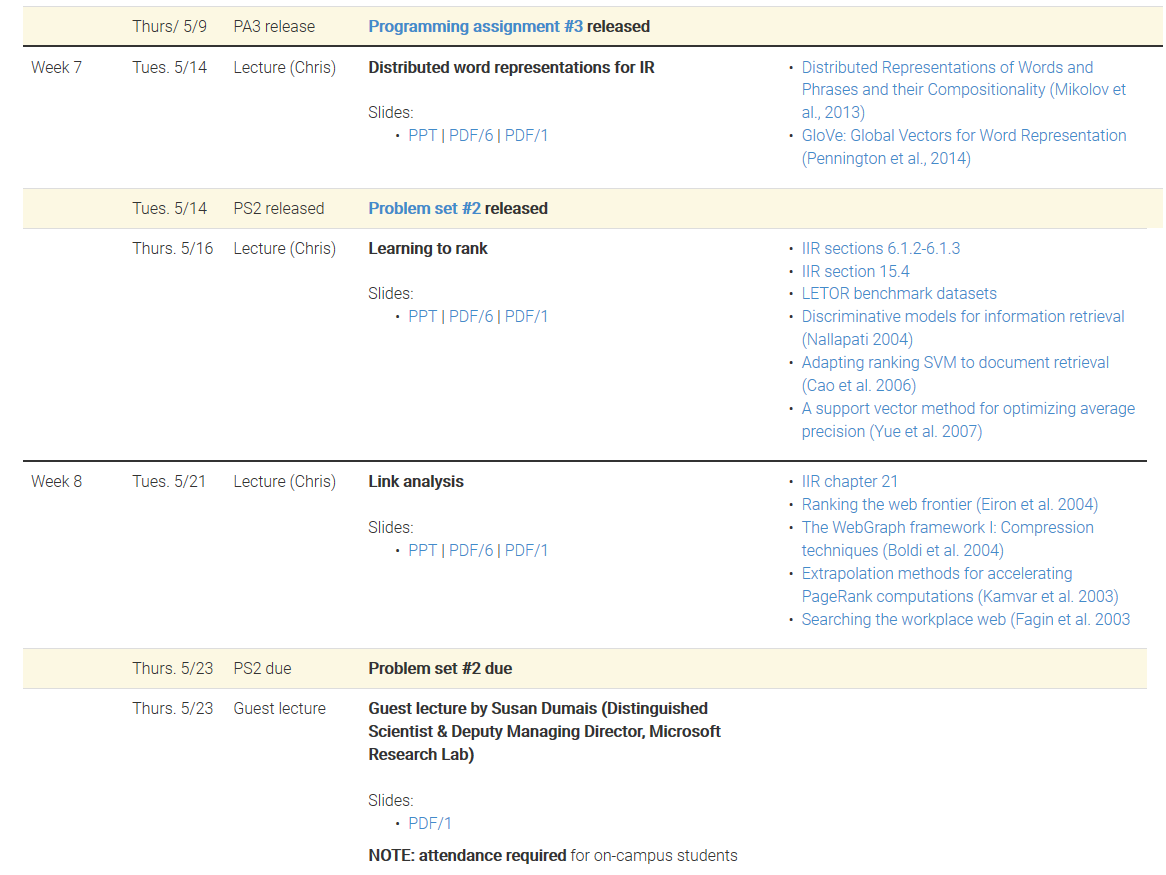
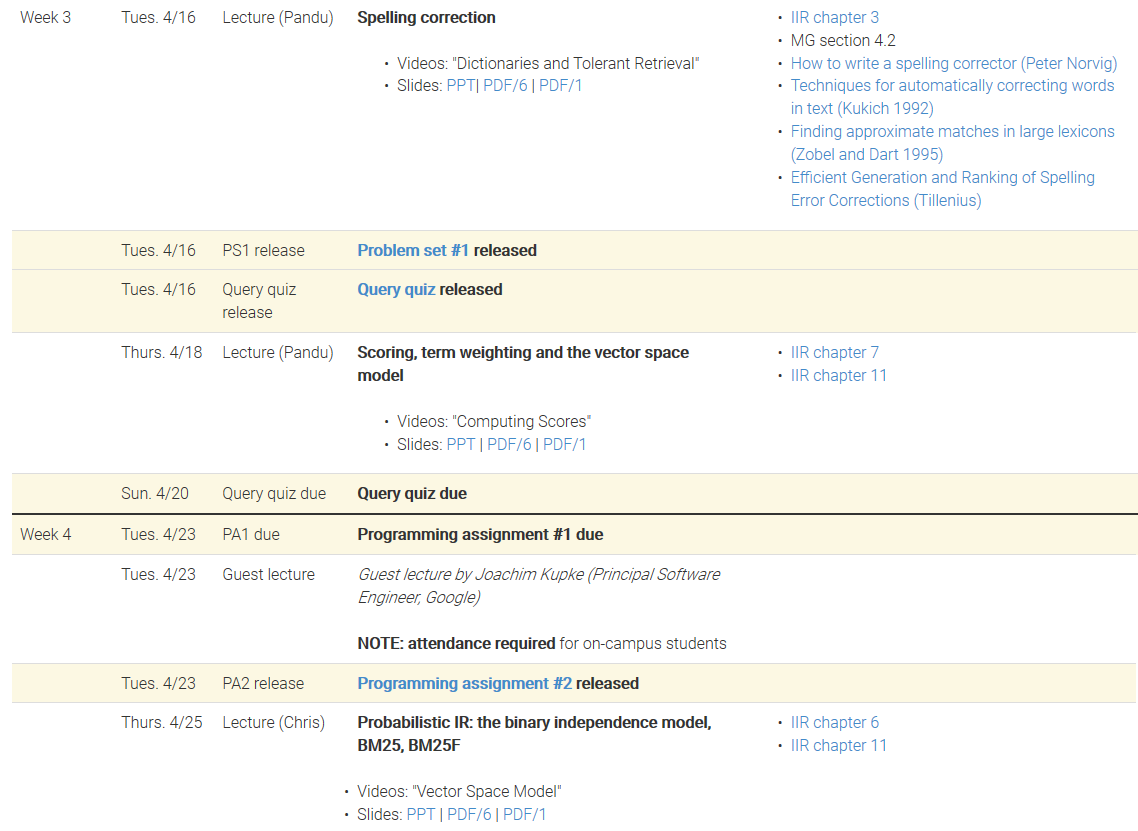
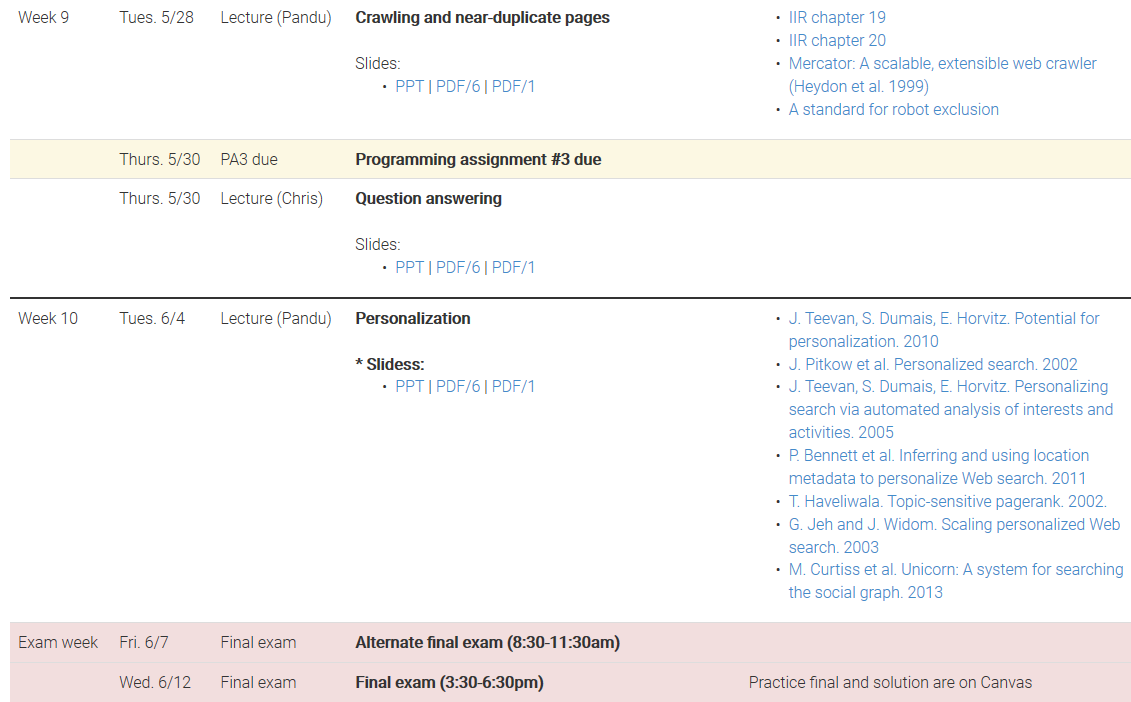
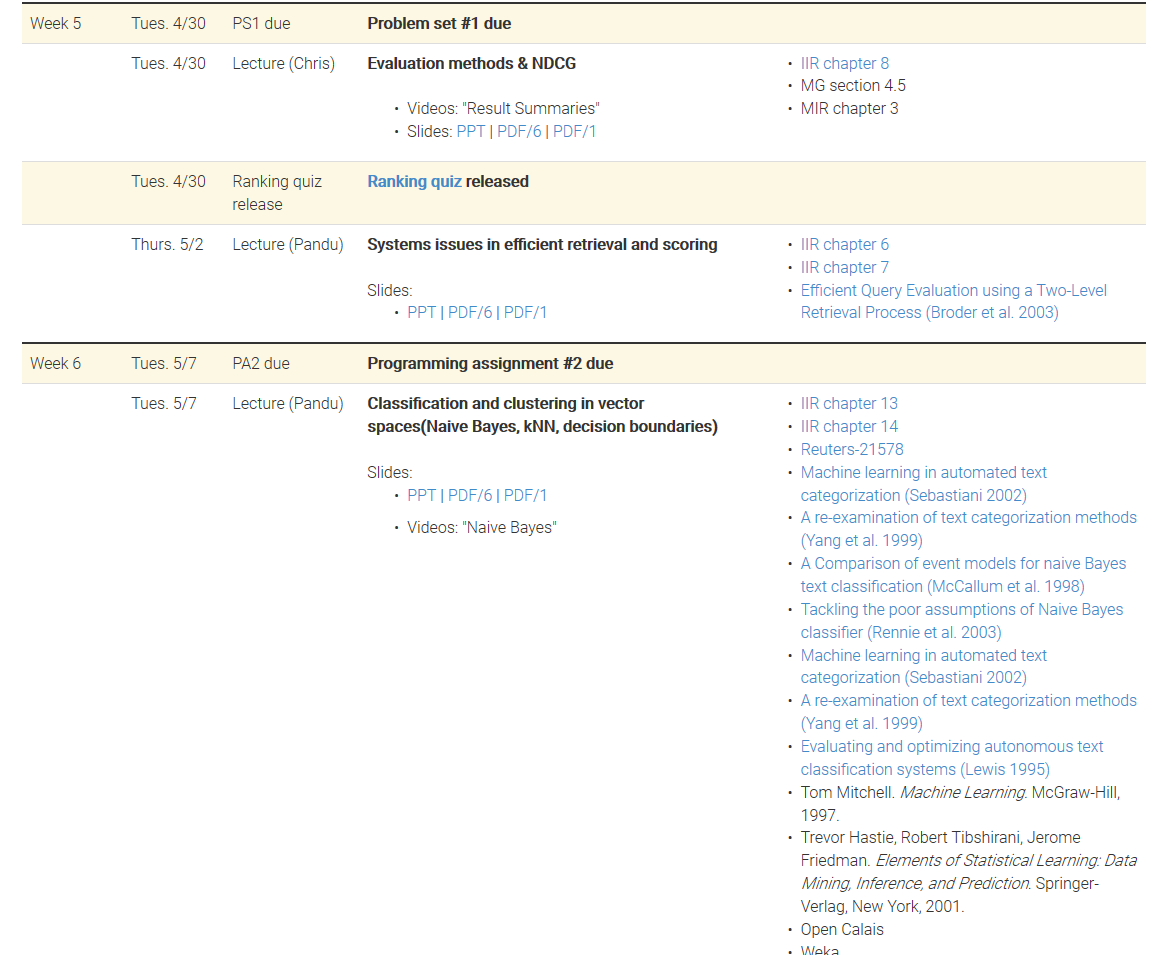
- 高效的文本索引
- 布尔和向量空间检索模型
- 评估和界面问题
- Web的IR技术,包括爬网,基于链接的算法和元数据使用
- 文档聚类和分类
- 传统和基于机器学习的排名方法
讲师介绍: Christopher Manning,SAIL 新任负责人,Christopher Manning于1989年在澳大利亚国立大学取得三个学士学位(数学、计算机和语言学),并于 1994 年获得斯坦福大学语言学博士学位。 他曾先后在卡内基梅隆大学、悉尼大学等任教,1999 年回到母校斯坦福,就职于计算机科学和语言学系,是斯坦福自然语言处理组(Stanford NLP Group)的创始成员及负责人。重返斯坦福之后,他一待就是 19 年。 Manning 的研究目标是以智能的方式实现人类语言的处理、理解及生成,研究领域包括树形 RNN 、情感分析、基于神经网络的依存句法分析、神经机器翻译和深度语言理解等,是一位 NLP 领域的深度学习开拓者。他是国际计算机学会 (ACM)、国际人工智协会(AAAI)、国际计算语言学会(ACL)等国际权威学术组织的 Fellow,曾获 ACL、EMNLP、COLING、CHI 等国际顶会最佳论文奖,著有《统计自然语言处理基础》、《信息检索导论》等自然语言处理著名教材。
Pandu Nayak,谷歌工程师,负责信息检索方面的研究。 在加入Google之前,我曾是Stratify,Inc.的首席架构师和首席技术官。在那里,帮助开发了成功的Stratify Legal Discovery服务。