
原创作者:张津旭 指导老师:张宇 转载须标注出处:哈工大SCIR
1. 简介
现实世界中存在各式各样的文档,如票据、网页、论文等,文档视觉问答任务旨在理解文档中的文本、图像以及排版布局等多模态信息,以准确回答用户问题。在大数据时代,通过文档图像可以对各种类型的数据进行统一建模并构建多模态智能问答系统,具有极高的应用价值。因此,如何对文档进行统一建模并能高效从中抽取或推理出相关信息是尤为重要的。 文档视觉问答以LayoutLM为开端,主要经历了基于OCR工具的方法,以及当下端到端的文档理解方法这两个阶段。而最近大语言模型的出现同时带动了多模态大模型(Multimodal Large Language Model,MLLM)的研究,在各个多模态评测任务上取得了不俗的效果,但由于文档数据丰富多样,MLLM在复杂布局或者内容丰富的文档图像上面临较大的挑战。本文旨在对过去的方法进行总结并指明未来多模态大模型在未来的发展方向。
2. 背景
2.1 任务定义 在文档视觉问答(DocVQA)任务中,模型的输入是用户对相关文档图像提出的问题,输出是针对用户问题从文档图像中抽取或推理出的相关文本片段。与图像领域中的视觉问答(VQA)的不同之处在于,DocVQA中文档图像中的内容包括文本、图像以及丰富的排版格式等信息,而VQA中的图像均来自现实世界中的场景。
2.2 相关数据集
我们针对文档视觉问答不同的答案类型和规模,分别介绍以下主流数据集: * 抽取式单页文档:DocVQA[1]数据集作为第一个文档图像问答数据集,其既包含了信件、表格、手写文字等各式各样的扫描文档,大部分答案为抽取式的短语或实体,能有效验证模型对于基础文档图像的问答能力。InfographicVQA[2]数据集则是来源于各式各样的海报,布局丰富多样,含有多种图表信息,对模型提出了进一步挑战,能充分验证模型对复杂布局文档的理解能力。 * 摘要式单页文档:VisualMRC[3]数据集来源于各种网站上的网页,往往包含较长的文本以及不同模态的格式化信息,同时考验了模型对文档内容的全面理解能力以及人性化答案的生成能力。TATDQA[4]是来自金融领域中文本与表格结合的文档图像,其对模型在文档内容推理和数值计算上提出了较高的要求。 * 抽取式多页文档:MPDocVQA[5]数据集是第一个面向多页文档问答的数据集,文档类型与 DocVQA 类似,答案来自于某一页,挑战在于模型能够从给定的大规模文档图像中准确定位到相关文档页。 * 混合多页文档:DUDE[6]数据集是集各种答案类型于一体的多页文档问答数据集,包括摘要式、抽取式、列表式以及不可回答四种类型的答案,充分考验模型对多页文档的理解能力和不同类型答案的提取能力。
3. 前沿进展
图1:文档视觉问答框架 文档视觉问答的能力是基于模型对文档视觉理解的能力上的,如图1所示,模型对文档的理解能力体现在多模态信息的对齐和融合,以及图文的相互转换。现有方法都是利用大规模文档数据设计一系列预训练任务,实现文档图像中多模态信息的对齐,这里主要包括图像和文本两个模态,然后将文档视觉问答作为一个下游任务,来评测模型对文档的理解能力。然而,当前文档视觉问答依然面临如下问题:图表推理、多跳问答、多页文档问答以及跨模态联合推理等。为了帮助研究者们更深入地了解从哪些角度提升模型对文档图像的理解能力,我们将现有文档视觉问答的研究分成三类,分别为:两阶段预训练-微调、端到端预训练-微调以及基于中间结果的微调。如图2所示,我们将详细介绍这三类方法中研究者们解决文档视觉问答任务的具体措施。
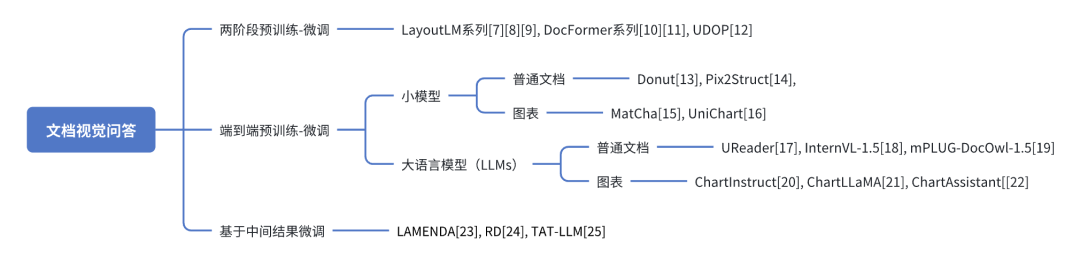
图2:文档视觉问答前沿进展总结
3.1 两阶段预训练-微调 两阶段预训练-微调是指首先使用OCR工具提取出文档图像中的文本及对应的坐标信息,通过设计文本、坐标布局、图像三者之间的预训练对齐任务,来提升模型对文档图像的理解能力。现有研究结果表明,图像、文本和坐标均属于不同模态的信息,其语义空间差异较大,因此,通过利用大规模数据进行不同模态间的语义对齐能有效提升模型对文档图像的理解能力。 LayoutLM系列的工作首先进行了探索,并取得了良好进展,以LayoutLMv3[7]为例,类似于BERT,利用大量的无标注文档图像数据,通过设计掩码语言建模(MLM),掩码图像建模(MIM),词块对齐(WPA)这三个预训练任务,从实现文档图像的通用表示,在文档信息抽取、文档视觉问答等多个下游任务中取得了良好结果。DocFormer系列工作认为将文本与视觉空间中更加细粒度的任意像素长度对齐是至关重要的,如DocFormer[8]中设计了图像重建任务(LTR)和文本描述图像的任务(TDI)来增强图文之间的深度对齐。UDOP[9]同DocFormer一样采取编码器-解码器架构,并进一步增强预训练任务,即文本-布局重建任务、布局预测任务、视觉-文本识别任务以及图像重建任务,实现了文档中视觉、文本和布局不同模态信息的统一。
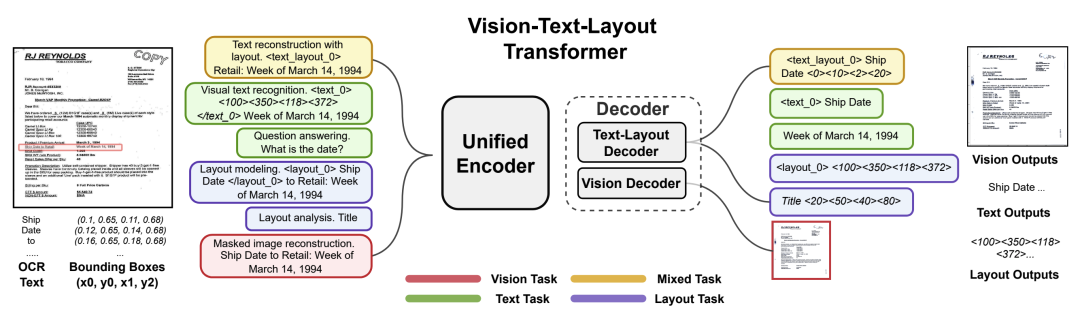
图3:UDOP方法示意图 3.2 端到端预训练-微调 端到端预训练-微调方法是指不使用OCR等外部工具对图像进行预处理,而是在模型输入中只处理文档图像和问题,输出为答案。模型架构统一为视觉编码器和文本解码器,在经过图像-文本任务进行语义空间对齐后,视觉编码器便在一定程度上对文档在多模态信息上有语义上的理解。 Donut[10]首先提出了文档视觉问答基于端到端预训练-微调的网络架构,预训练任务通过简单的伪OCR任务实现图像和文本的对齐,而下游任务则通过不同的任务前缀进行区分,实现了简单高效的文档理解模型。
图4:Donut模型示意图 Pix2Struct[11]则通过增加HTML网页数据的预训练任务,进一步增强了该架构在文档理解上的效果。此外,MatCha[12]和UniChart[13]是分别基于Pix2Struct和Donut模型在图表数据上进行了预训练,实现了图表类文档数据的有效理解。 随着大语言模型的出现,多模态大语言模型如雨后春笋般出现,然而,鲜有专门在文档图像上进行预训练的多模态大语言模型,因此,大部分模型在文档视觉问答任务中的效果不如小模型。UReader[14]是首次针对文档图像提出的一个端到端多模态大模型。由于文档图像中包含大量文字信息,一方面需要图像具有较高的分辨率,另一方面需要视觉编码器具备较高的识别能力,UReader通过设计一个自适应形状切割模块,如图5所示,使低分辨率的视觉编码器也能处理高分辨率的图像,在多个文档图像数据集上的效果有明显提升。此后的工作,如InternVL-1.5[15]和mPLUG-DocOwl-1.5[16]都是通过提升图像分辨率以及增强视觉编码器的方式进一步提升对文档图像的理解能力。
图5:UReader模型 ChartInstruct[17],ChartLLaMA[18],ChartAssistant[19]都是在图表类文档上进行的研究工作,他们的共同点在于基于多模态大语言模型使用了大规模的图表-表格数据进行了图表文档的图文对齐任务,而后在各种图表相关下游任务中进行了实验。以ChartAssistant为例,如图6所示,首先经过Chart-to-Table Translation任务实现模型对图表的理解,然后利用多任务指令学习实现各个下游任务。
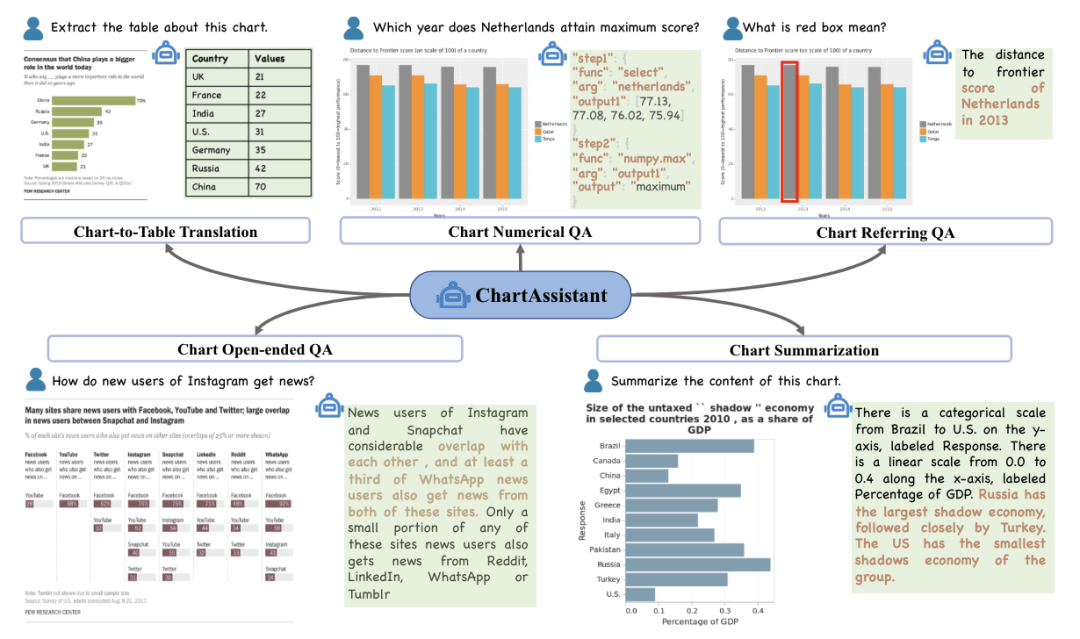
图6:ChartAssistant的各种图表下游任务 3.2 基于中间结果的微调 大语言模型中拥有上下文学习、思维链推导等独特的能力,这些方法能促进大语言模型像人一样思考,通过将复杂问题分解为多个简单步骤处理,可以提升模型在回答复杂问题上的准确度。那么,如果将这种能力迁移到小模型中能否进一步突破小模型在文档图像理解上的瓶颈呢?最近的研究者对此进行了实验,对于以往的文档视觉问答,模型都是根据输入的文档图片和问题,直接输出最终答案,而现在首先让模型生成与问题相关的上下文这一中间结果,再进一步生成最终答案。如图7所示[20],为了让小模型具备上下文学习能力,首先需要大量的训练数据,图中使用了大语言模型的少样本方法作为指令,依据图片内容、问题和答案来提取相关证据信息。
图7:Rationales的提取 在获得了大量中间结果标注数据后,便可以用来训练小模型了,如表1所示,通过在Pix2Struct上进行实验,发现让模型首先输出中间结果上下文,再输出答案能显著提升文档视觉问答任务的性能。
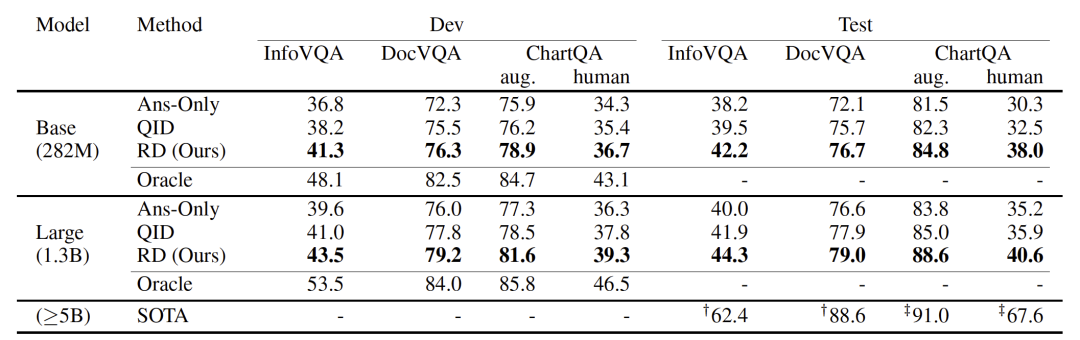
表1:Pix2Struct上下文学习结果 LAMENDA[21]是针对图表类文档中复杂问题而设计的包含思维链中间步骤的增强数据,文章中清楚证明了小模型在经过“按步骤思考”后,再得出答案,可以提升数值计算等问题的准确率。同样地,TAT-LLM[22]则是在大语言模型上分别设计了证据抽取器、推理器和执行器三个模块,通过让大语言模型在文本和表格混合的数据集上按照以上三个步骤进行训练,得出的答案准确率有了明显提升。 4. 未来方向 在本节,我们将介绍目前存在的挑战以及未来可能的改进方法,进一步提升文档视觉问答任务的性能。 4.1 文档图像理解 虽然目前的视觉编码器已经能够理解大多数简单布局的文档,但针对复杂布局的文档依然存在缺陷,尤其是针对现实世界各类图表数据,现有模型并不能完全理解其内在的细节关系。主要原因之一还是缺乏此类数据,现有数据大多集中在对文档信息的简单抽取上,并未训练其理解文档深度细节关系的能力,因此,未来可以进一步丰富文档视觉问答在不同领域,不同难度上的数据集,以进一步实现文档视觉问答任务在实际生活中的应用。 4.2 多页文档图像问答 目前的方法大部分针对的是单页文档图像,MPDocVQA[5]和DUDE[6]是最近提出的多页文档视觉问答数据集,现有模型还未曾实现基于端到端的方法实现对多页文档图像的有效理解,而实际生活中我们的需求都是针对多页文档,因此,未来需要实现能充分理解多页文档内容的视觉编码器,以及大规模用于训练的多页文档视觉问答数据集。 4.3 跨模态联合推理 文档图像中包含的数据是丰富多样的,既包括文本,也可能有图像、表格等其他模态信息,这要求模型不仅要理解文档图像中的多模态信息,还能够基于不同模态信息进行推理,尤其是图表和表格,对数值计算具有较高的要求。因此,未来需要增强模型对文档图像中多模态信息的整合与推理能力,可以通过训练其上下文学习能力来提升这一效果。 5. 总结 本文旨在向读者们提供文档视觉问答这一任务的发展历程,以及存在的挑战和展望。我们将现有的研究方法分为了三个类别:两阶段预训练-微调、端到端预训练-微调以及基于中间结果的微调。其中第三个主要借鉴了大语言模型的上下文学习能力。最后,我们讨论了目前文档视觉问答任务存在的不足以及改进方向,希望本文可以对读者带来更多的启发。
6. 参考文献
[1] Mathew M, Karatzas D, Jawahar C V. Docvqa: A dataset for vqa on document images[C]//Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2021: 2200-2209. [2] Mathew M, Bagal V, Tito R, et al. Infographicvqa[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2022: 1697-1706. [3] Tanaka R, Nishida K, Yoshida S. Visualmrc: Machine reading comprehension on document images[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(15): 13878-13888. [4] Zhu F, Lei W, Feng F, et al. Towards complex document understanding by discrete reasoning[C]//Proceedings of the 30th ACM International Conference on Multimedia. 2022: 4857-4866. [5] Tito R, Karatzas D, Valveny E. Hierarchical multimodal transformers for Multipage DocVQA[J]. Pattern Recognition, 2023, 144: 109834. [6] Van Landeghem J, Tito R, Borchmann Ł, et al. Document understanding dataset and evaluation (DUDE)[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 19528-19540. [7] Huang Y, Lv T, Cui L, et al. Layoutlmv3: Pre-training for document ai with unified text and image masking[C]//Proceedings of the 30th ACM International Conference on Multimedia. 2022: 4083-4091. [8] Appalaraju S, Jasani B, Kota B U, et al. Docformer: End-to-end transformer for document understanding[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 993-1003. [9] Tang Z, Yang Z, Wang G, et al. Unifying vision, text, and layout for universal document processing[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 19254-19264. [10] Kim G, Hong T, Yim M, et al. Ocr-free document understanding transformer[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 498-517. [11] Lee K, Joshi M, Turc I R, et al. Pix2struct: Screenshot parsing as pretraining for visual language understanding[C]//International Conference on Machine Learning. PMLR, 2023: 18893-18912. [12] Pang C, Liu F, Piccinno F, et al. MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering[J]. 2022. [13] Masry A, Kavehzadeh P, Do X L, et al. Unichart: A universal vision-language pretrained model for chart comprehension and reasoning[J]. arXiv preprint arXiv:2305.14761, 2023. [14] Ye J, Hu A, Xu H, et al. Ureader: Universal ocr-free visually-situated language understanding with multimodal large language model[J]. arXiv preprint arXiv:2310.05126, 2023. [15] Chen Z, Wang W, Tian H, et al. How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites[J]. arXiv preprint arXiv:2404.16821, 2024. [16] Hu A, Xu H, Ye J, et al. mplug-docowl 1.5: Unified structure learning for ocr-free document understanding[J]. arXiv preprint arXiv:2403.12895, 2024. [17] Masry A, Shahmohammadi M, Parvez M R, et al. ChartInstruct: Instruction Tuning for Chart Comprehension and Reasoning[J]. arXiv preprint arXiv:2403.09028, 2024. [18] Han Y, Zhang C, Chen X, et al. Chartllama: A multimodal llm for chart understanding and generation[J]. arXiv preprint arXiv:2311.16483, 2023. [19] Meng F, Shao W, Lu Q, et al. Chartassisstant: A universal chart multimodal language model via chart-to-table pre-training and multitask instruction tuning[J]. arXiv preprint arXiv:2401.02384, 2024. [20] Zhu W, Agarwal A, Joshi M, et al. Efficient End-to-End Visual Document Understanding with Rationale Distillation[J]. arXiv preprint arXiv:2311.09612, 2023. [21] Zhuowan L, Bhavan J, Peng T, et al. Synthesize Step-by-Step: Tools, Templates and LLMs as Data Generators for Reasoning-Based Chart VQA[J]. arXiv preprint arXiv:2403.16385, 2024. [22] Zhu F, Liu Z, Feng F, et al. TAT-LLM: A Specialized Language Model for Discrete Reasoning over Tabular and Textual Data[J]. arXiv preprint arXiv:2401.13223, 2024.
编辑:李子健初审:张 羽复审:冯骁骋终审:单既阳***
哈尔滨工业大学社会计算与交互机器人研究中心
理解语言,认知社会 以中文技术,助民族复兴
