文档人工智能(Document AI,简称 DAI)已成为一个至关重要的应用领域,而大语言模型(Large Language Models,简称 LLMs)的兴起正在深刻地重塑这一领域。早期方法主要依赖于编码器–解码器(encoder-decoder)架构,而如今仅使用解码器的 LLM 模型在文档智能中引发了革命性变革,显著推动了文档理解与生成能力的提升。 本文对 DAI 的发展历程进行了全面梳理,重点总结了当前研究进展以及 LLM 在该领域的未来前景。我们系统探讨了多模态(multimodal)、多语言(multilingual)以及检索增强(retrieval-augmented)等方向中的关键突破与挑战,同时提出了若干未来研究方向,包括基于智能体(agent-based)的方法和面向文档的专用基础模型(document-specific foundation models)。 本文旨在对 DAI 的最新研究现状及其在学术与实际应用中的潜在影响进行结构化分析,为后续研究提供系统参考。
1 引言
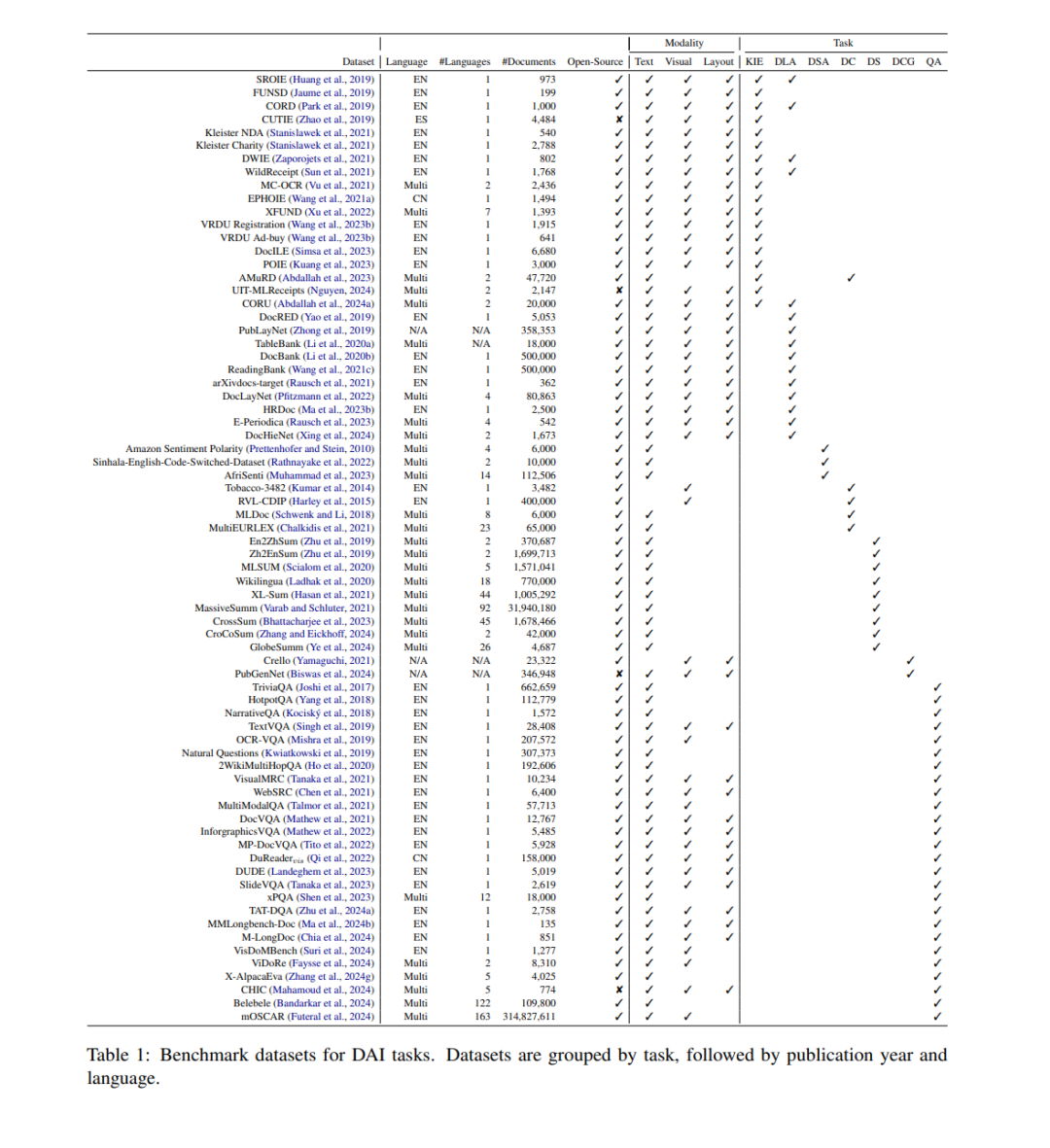
文档作为信息传递的重要载体,呈现出多样的格式形式,在科研与工业领域均扮演着关键角色(Stage and Manning, 2003)。文档人工智能(Document AI,简称 DAI) 综合利用自然语言处理(NLP)与计算机视觉(CV)技术,以实现文档相关任务的自动化,主要可分为两大类:文档理解(understanding)(Pfitzmann et al., 2022; Mathew et al., 2021)与文档生成(generation)(Wiseman et al., 2017; Zhang et al., 2018)。然而,传统的基于规则方法(rule-based)(Bourgeois et al., 1992)与基于学习方法(learning-based)(Marinai et al., 2005)通常成本高昂且耗时费力,这促使研究者转向语言模型,以期获得更高效、可扩展的解决方案。 在众多模型中,仅编码器(encoder-only)模型(Hong et al., 2022; Huang et al., 2022; Luo et al., 2023)常用于捕捉细粒度、文档特定的信息;而编码器–解码器(encoder-decoder)架构在处理具有可变长度和多模态输入输出的生成任务上表现突出(Tanaka et al., 2021; Tang et al., 2023),但其性能仍受限于训练数据的质量与规模。 近年来,仅解码器(decoder-only)大语言模型(LLMs) 的突破推动了面向文档任务的 LLM 研究。这些模型基于多样化的多模态数据进行训练,涵盖图像分割(Hu et al., 2024a)、版面布局(Wang et al., 2024a; Luo et al., 2024)以及几何信息(Lamott et al., 2024)等任务,在文档理解与生成方面均展现出显著性能提升。 尽管取得了显著进展,LLMs 在准确解释文档内容方面仍存在挑战(Liu et al., 2024a)。许多模型仍依赖光学字符识别(OCR)引擎,或忽略文档中丰富的文本语义信息,从而阻碍了跨多种文档模态学习统一表示的能力。此外,多语言性与语言多样性(Joshi et al., 2020)仍是普遍难题:数据稀缺及高质量训练语料不足限制了多语言 LLM 的表现。虽然已有研究探索了跨语言泛化(cross-lingual generalization)在等价翻译任务中的有效性(Zhang et al., 2023),但 DAI 往往需要更复杂的上下文信息,如文档结构与语言特定知识(Zhao et al., 2024c; Xing et al., 2024),这进一步限制了 LLM 在多语言文档处理中的性能。 LLMs 在 DAI 领域的发展与应用,已成为当前的核心研究方向。实现多语言与多模态能力是模型应对多样化真实场景的关键(Xu et al., 2024b; Zhu et al., 2024b)。近期的研究致力于融合多语言性与多模态性,以增强统一文档表示学习(unified document representation learning),从而提升 LLM 的通用性与鲁棒性(Hu et al., 2024a)。 鉴于基于 LLM 的 DAI 的快速发展,亟需对其在文档处理方面的能力进行系统性梳理。为此,本文综述了当前最先进(SoTA)的多语言与多模态 LLM 的最新进展,重点分析了它们在 DAI 中的表现、所面临的挑战及未来发展方向。 在这篇深入的综述中,我们系统地将基于 LLM 的 DAI 相关研究划分为五大核心任务。本文的主要贡献包括: * (1) 在第 2 节中,详细介绍了文档智能的定义与发展历程,并概述了相关的评测基准(benchmarks); * (2) 在第 3 节中,全面回顾了 LLM 多模态能力的集成进展,重点分析其在多样化 DAI 应用中的效果; * (3) 在第 4 节与第 5 节中,系统分析了多语言能力与检索增强(retrieval-augmented)范式的最新发展,探讨它们在提升**上下文感知文档智能(context-aware document intelligence)**中的作用; * (4) 最后,总结了构建高可靠性文档专用基础模型(document-specific foundation models)所面临的关键技术挑战,并提出了面向未来的可行研究方向,为 DAI 的持续发展提供参考。