
北京交通大学桑基韬教授团队发布最新Agent综述,梳理了从流水线向模型原生发展的趋势,包括规划、工具使用、记忆这些基本能力和Deep Research、GUI Agent两类应用。 调研过程感受到基于LLM的大规模强化学习对这种趋势的推动作用,也感受到了系统层在逐渐模型原生化后从能力补偿到生态支持定位上的变化。 欢迎在repo里一起讨论:
https://github.com/ADaM-BJTU/model-native-agentic-ai
智能体式人工智能(Agentic AI)的迅速发展标志着人工智能进入了一个全新的阶段,在这一阶段中,大语言模型(Large Language Models, LLMs)不再只是被动响应,而是具备了行动、推理与适应的能力。本文综述了构建智能体式人工智能的范式转变:从基于流水线(Pipeline-based)系统——即规划、工具使用与记忆由外部逻辑协调——逐步演进到模型原生(Model-native)范式,其中这些能力被内化至模型参数之中。 我们首先将强化学习(Reinforcement Learning, RL)定位为推动这一范式转变的算法引擎。通过将学习从对静态数据的模仿转变为面向结果的探索,强化学习支撑了跨语言、视觉与具身领域的统一解决方案 —— LLM + RL + Task。在此基础上,本文系统性地回顾了三大核心能力——规划(Planning)、工具使用(Tool Use)与记忆(Memory)——如何从外部脚本化模块演化为端到端的可学习行为。进一步地,我们分析了这一范式转变如何重塑了两类代表性智能体应用:Deep Research智能体(强调长时推理能力)与GUI智能体(强调具身交互能力)。 最后,我们讨论了智能体能力的进一步内化趋势,包括**多智能体协作(Multi-agent Collaboration)与反思(Reflection)等方面的融合演进,以及系统层与模型层在未来智能体式人工智能中的角色变化。总体而言,这些发展勾勒出一条通向模型原生智能体式人工智能(Model-native Agentic AI)**的清晰路径——一个融合学习与交互的整体框架,标志着人工智能从“构建应用智能的系统”迈向“通过经验成长智能的模型”的转型。 § 项目主页:https://github.com/ADaM-BJTU/model-native-agentic-ai 关键词:智能体式人工智能(Agentic AI)、AI智能体、模型原生(Model-native)、流水线(Pipeline)、强化学习(Reinforcement Learning)、大语言模型(Large Language Models) Jitao Sang, Jinlin Xiao, Jiarun Han, Jilin Chen, Xiaoyi Chen, Shuyu Wei, Yongjie Sun, and Yuhang Wang. 2025. Beyond Pipelines: A Survey of the Paradigm Shift toward Model-Native Agentic AI. J. ACM 1, 1 (October 2025),76 pages. https://doi.org/10.1145/nnnnnnn.nnnnnnn

“我听见就忘记,我看见就记住,我实践就理解。” ——孔子
1 引言(Introduction)
近年来,人工智能(Artificial Intelligence, AI)领域被生成式人工智能(Generative AI)的迅猛发展所主导,该类技术在生成类人文本、图像及其他模态内容方面表现卓越 [13, 164, 210]。然而,生成式人工智能的输出仍主要是被动响应式的:它能根据提示生成内容,却无法主动追求目标、维持长程推理,或与环境交互。为了突破被动生成的局限,迈向自主行动的智能形态,研究者们逐渐将焦点转向智能体式人工智能(Agentic AI),这一方向强调自我导向的行为、复杂的推理能力以及环境交互能力。智能体式人工智能的兴起,被广泛视为AI系统演化的下一个阶段。 在学术界与工业界,普遍认为智能体式AI的三项核心能力为: * 规划(Planning):将高层次目标分解为连贯的多步策略; * 工具使用(Tool Use):调用与协调外部资源,如API、数据库或其他模型; * 记忆(Memory):在长时范围内保留、检索与管理信息。
智能体式AI的发展与其核心能力的实现方式密切相关,而后者正经历着一次深刻的范式转变。
1.1 范式(Paradigms)
**(1)基于流水线的范式(Pipeline-based Paradigm)
早期构建智能体的尝试可归纳为“流水线(pipeline)”范式,在这种体系中,智能体的核心能力主要由外部结构在工作流式架构中协同实现: * 规划(Planning):早期系统依赖外部符号规划器(如PDDL,Planning Domain Definition Language)。例如,LLM+P [126] 通过独立于领域的引擎生成计划,而非由模型本身推理。随后,研究者通过提示(prompt)直接引导模型生成推理链(如思维链(Chain-of-Thought, CoT)[244] 与思维树(Tree-of-Thought, ToT)[276]),让模型以逐步推理的方式表达其中间思考过程。 * 工具使用(Tool Use):最初表现为单轮函数调用[165],即模型生成结构化的API请求,由系统解析并执行。之后发展为多轮框架,如ReAct[277],该框架促使模型在“思维-行动-观察(Thought-Action-Observation)”循环中交替进行推理与调用外部动作。 * 记忆(Memory):长期以来依赖外部模块实现。短期记忆通常通过对话摘要(conversation summary)[18]维持,即将长交互历史压缩后重新注入上下文窗口;长期记忆多采用检索增强生成(Retrieval-Augmented Generation, RAG)[97],即将历史交互存储于向量数据库中并按需检索。
在此范式下,智能体的关键能力并非模型内生,而是通过人工设计的流水线外化实现。形式上定义如下: 定义 1(基于流水线的智能体式人工智能)
基于流水线的智能体式AI将智能体视为一个系统,其中大语言模型(LLM)仅作为被外部逻辑编排的功能组件。其策略函数为复合函数形式: , 其中,外部流水线(系统工作流或模型提示)
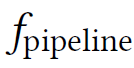
对模型内部策略 的输出施加约束与操控。 该范式的优点在于模块化与一定的可解释性,但局限亦十分明显:系统依赖精心设计的流水线逻辑,结构僵化且脆弱,面对动态环境时难以自适应。更根本地,流水线范式将LLM视为被动工具,而非主动决策体。
**(2)模型原生范式(Model-native Paradigm)
为克服流水线范式的限制,智能体式AI正在向“模型原生(model-native)”原则转变。该新范式的核心思想是:不再构建复杂的外部智能体系统,而是训练一个强大的智能体模型,使模型自身即为系统。
在旧范式中,智能体被概念化为通过提示与脚本连接的复合系统;而在新兴的模型原生范式中,智能体被视为单一、统一的模型,其通过端到端训练学习自主执行高层次功能。规划、工具使用与记忆管理不再是外部模板或脚本,而是逐步内化为模型的固有行为。
规划内化:OpenAI 的推理模型 o1 [166] 首次通过大规模强化学习实现了“模型学会自主思考与规划”的可行性;DeepSeek 的 R1 [38] 进一步证明,基于结果奖励的强化学习即可训练出推理与规划行为,无需高成本的逐步监督。 * 工具使用内化:OpenAI 的 o3 [167] 将工具调用融入推理过程,模型能够学习何时以及如何在策略内部调用多种工具;Moonshot 的 K2 [88] 则通过大规模工具使用轨迹与多阶段RL强化了多步决策能力。
记忆内化:短期记忆方面,Qwen-2.5-1M [268] 通过合成长序列数据扩展了原生上下文窗口,实现了更长时信息的保持;进一步地,MemAct [311] 将上下文管理重新表述为模型可学习的“工具调用”,让模型自主决定何时存储或检索信息。长期记忆方面,MemoryLLM [238] 开创性地实现了参数化记忆,通过在前向传播中持续更新潜在记忆token,使知识得以自动内部更新。
显然,相比于流水线范式,模型原生范式将LLM视为主动的决策者,其学习自主生成计划、调用工具并管理记忆。形式上可定义为:

1.3 算法(Algorithms)
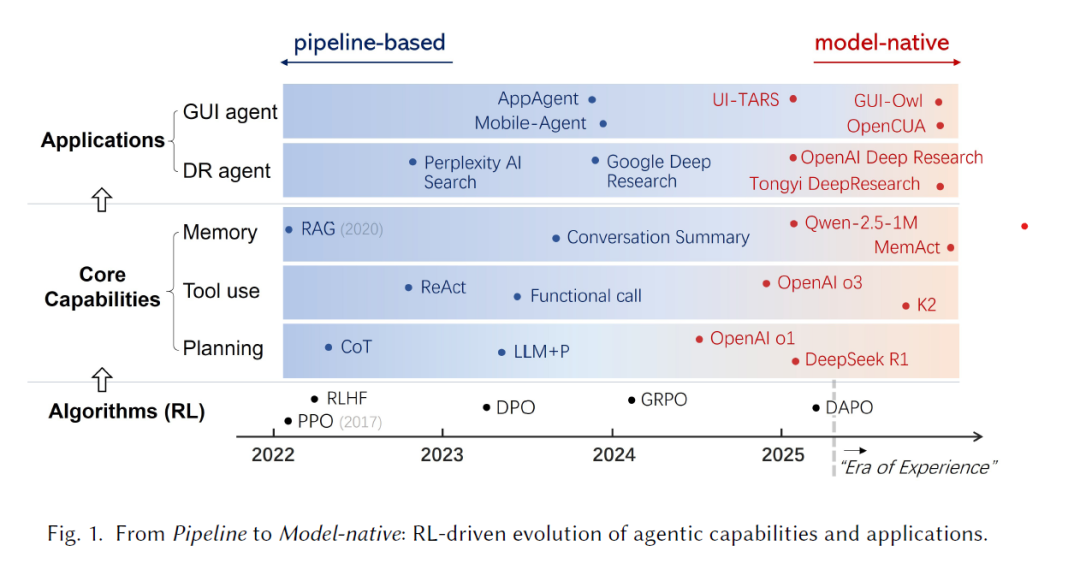
推动智能体式人工智能(Agentic AI)从**基于流水线(pipeline-based)向模型原生(model-native)范式转变的核心动力,是大规模强化学习(Reinforcement Learning, RL)在大语言模型(LLM)训练中的应用。自 DeepSeek-R1 技术报告 [38] 发布以来,端到端强化学习(end-to-end RL)在LLM中的研究取得了显著进展,表明智能体的核心能力可以通过探索式学习(exploration)**获得,而无需昂贵的逐步监督(step-by-step supervision)。这凸显了强化学习在推动LLM自主演化行为策略、适应新环境方面的变革潜力。图1展示了智能体从流水线范式向模型原生范式演进的过程,并结合了RL算法的演化脉络。
**从SFT到RL(From SFT to RL)
在强化学习成为主流之前,监督微调(Supervised Fine-Tuning, SFT)是提升LLM能力的主要手段。SFT的基本思想是让模型模仿数据集中真实的轨迹(ground-truth trajectories)。 然而,与感知层任务(如目标分类)不同,人类可以轻松标注图像类别,但智能体任务往往涉及认知与执行层(cognitive and executive level)操作。例如“撰写研究报告”这类真实任务通常包括多步推理、信息检索与多次修订。要为此类任务构建完整轨迹,成本极高且对人类标注者几乎不可行。 强化学习以一种优雅的方式规避了显式程序性监督的需求,通过重新定义学习问题实现突破。RL不再让模型去模仿“应该如何行动”的静态数据,而是让模型在动态环境中探索“哪些行动会导致成功”。 这一过程可形式化为马尔可夫决策过程(Markov Decision Process, MDP):在每一步,模型观察任务上下文(状态 sss),生成动作 aaa —— 可以是文本序列或具体决策。环境随后返回一个奖励信号(reward),衡量该动作相对整体任务目标的质量或效用。模型的目标是学习一个策略 πθ\pi_\thetaπθ,以最大化任务全过程的期望累计奖励。通过学习不同轨迹的相对价值,模型能够基于经验逐步改进策略,而无需逐步人工指导。 这种转变至关重要:它使模型能够发现人类数据中不存在的、更优策略,从被动模仿者转变为主动探索者(active explorer)。
**LLM的强化学习(RL for LLMs)
早期用于LLM的强化学习方法通常将模型视为静态序列生成器,其目标是使输出更符合人类偏好。代表性算法包括 PPO(Proximal Policy Optimization) [191] 与 DPO(Direct Preference Optimization) [189],它们广泛应用于人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF) [169] 框架中。 在RLHF中,首先训练一个奖励模型(reward model)将人类偏好转化为数值奖励,再通过PPO或DPO对LLM进行微调。该方法在优化单轮行为(single-turn behaviors)方面效果显著,例如提升模型的指令遵循性与生成内容的价值对齐性。 然而,这类RL方法无法充分训练出具备智能体特征(agentic)的模型。智能体运行于多轮交互与动态环境中,涉及长期依赖与稀疏奖励(sparse rewards)。传统的PPO/DPO与RLHF依赖密集、逐步监督,难以高效优化长程任务(long-horizon tasks)策略。 为应对这一问题,新一代结果驱动(outcome-driven)的RL算法应运而生,旨在解决长程任务中训练稳定性与效率的现实挑战。 * GRPO(Group Relative Policy Optimization) [193]:为克服PPO中大规模评论网络(critic network)的低效问题,GRPO提出一种组内相对优势计算(group-relative advantage)范式,通过计算同一组采样响应间的相对奖励来评估策略表现,无需绝对值评论器,从而提升训练稳定性。 * DAPO(Decoupled Clip and Dynamic sAmpling Policy Optimization) [285]:进一步改进了多轮交互性能,通过正负优势的分离裁剪机制(decoupled clipping)与动态采样策略(dynamic sampling),使其在长程任务的训练中表现更为高效。
随着这些创新的出现,更多RL算法不断涌现 [109, 223, 271],实现了更大规模、更高效的LLM训练。这一系列进展最终形成了当前被广泛认可的统一训练框架:
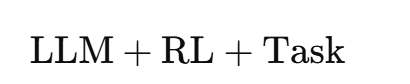
即在定义良好的任务环境中,通过强化学习算法对基础模型进行增强训练。 这些算法创新共同构成了推动**模型原生智能体式人工智能(Model-native Agentic AI)**范式转变的核心驱动力。
1.4 综述结构(Survey Structure)
本综述的后续章节组织如下: * 第2节:讨论为何智能体任务的独特特性决定了强化学习的必要性,并比较经典RL与LLM中的RL形式,以确立其可行性; * 第3至第5节:系统性回顾三大核心智能体能力——规划(Planning)、工具使用(Tool Use)与记忆(Memory)——从流水线范式向模型原生范式的演进; * 第6节:结合核心能力的演化,分析智能体应用的发展,重点介绍 Deep Research 智能体与 GUI 智能体 的演变路径; * 第7节:探讨其他智能体能力(如多智能体协作(Multi-agent Collaboration)与反思(Reflection))的模型原生化趋势,并分析未来在智能体式AI中**系统层(system layer)与模型层(model layer)**的角色分化与协同。
更多请查看原文: https://github.com/ADaM-BJTU/model-native-agentic-ai

