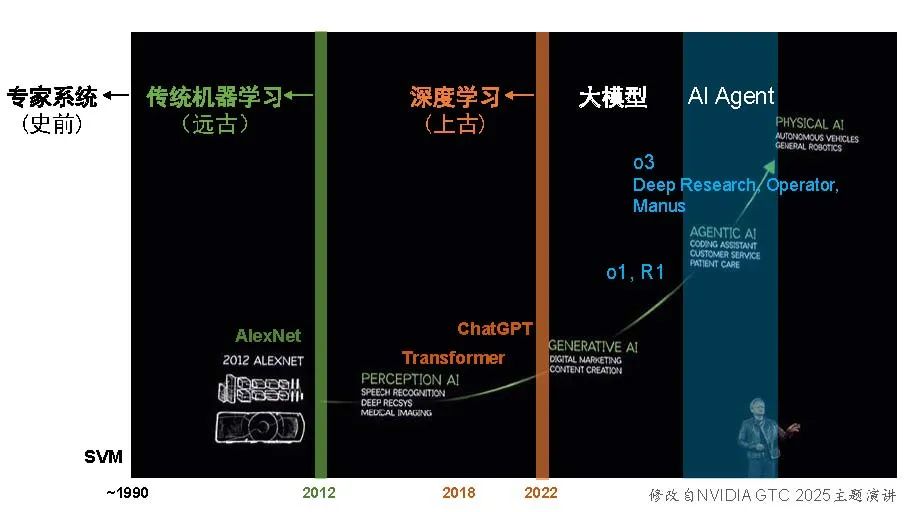
黄仁勋在英伟达GTC2025的主题演讲中回顾了AI过去十几年的发展。从2012年AlexNet开始的深度学习,到近几年大模型推动的生成式AI,再到当下正经历的Agentic AI,直到未来的Physical AI。

深度学习的十年里,AI进展超过了此前传统机器学习三十年的积累。而ChatGPT上线后的短短两年半,AI更是突飞猛进,取得的成果已经远超深度学习的十年。“人间一天,AI一年”。从今天回望,深度学习像是上古时期的,传统机器学习则是更遥远的远古技术,而SVM之前的专家系统,算是文明尚未开化的史前AI了。当前所处的Agentic AI有两波标志性事件:第一波是去年9月开始的以OpenAI的o1和DeepSeek的R1为代表的推理模型逐渐成熟,第二波是今年初的o3模型上线和Deep Research、Operator、Manus等Agent应用的出现。
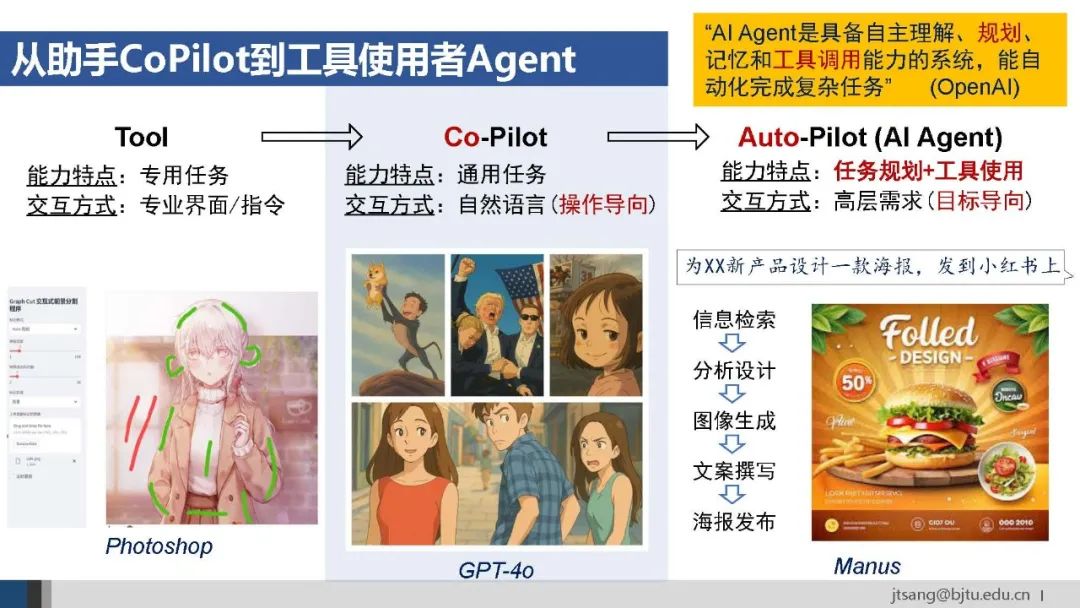
在大模型之前,以专家系统、传统机器学习和传统深度学习为代表的AI,依赖专业界面和指令,解决专用任务。比如用Photoshop进行交互式抠图。这一阶段的AI和人类历史上每次技术革命一样,提供的是被人类使用的工具。大模型带来的通用任务解决能力和自然语言交互界面,使AI成为人机协作的副驾驶Co-Pilot。比如GPT-4o支持基于自然语言指令生成图片、抠图、风格迁移等。不过,此时仍需人类给出明确、具体的指令:人指挥一步,AI执行一步。

除了内容理解和生成的感知能力,大模型逐步具备了任务规划和工具使用的认知决策和行动能力。AI可以直接理解和实现目标导向的高层需求。 比如提出“为某新产品设计海报并发布到小红书”,Manus会自主进行任务规划—将复杂任务拆解为多个子任务,并在必要时使用外部工具/其他agent来执行其中某个子任务。 此时,AI成为了主驾驶Auto-Pilot--即AI Agent。根据OpenAI的定义:AI Agent是具备自主理解、规划、记忆和工具调用能力的系统,能自动化完成复杂任务。
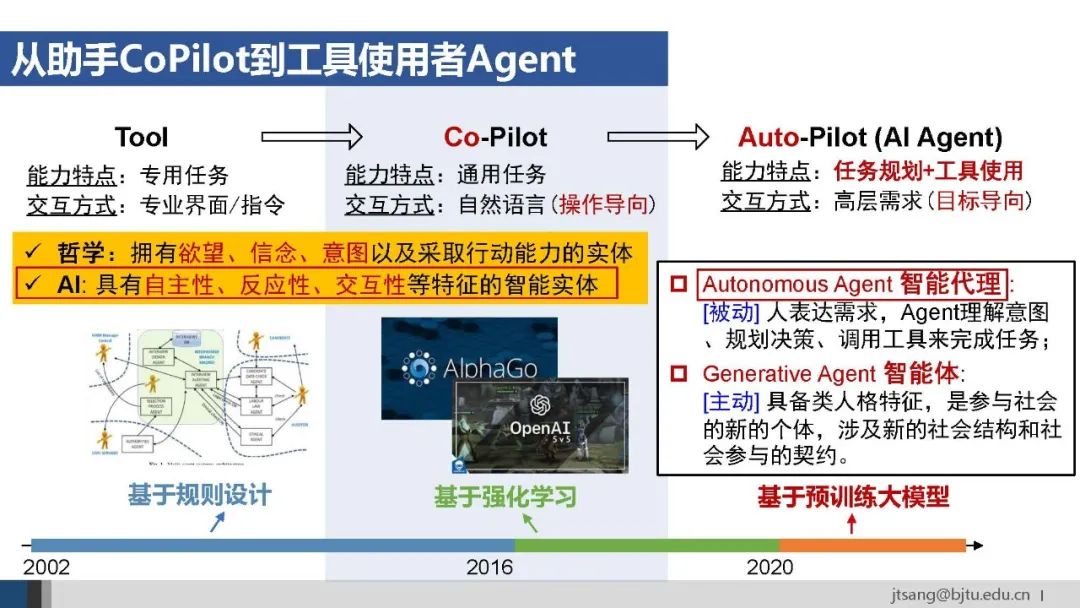
以上是从AI发展的角度看如何从Tool演变为AI Agent。从Agent这个术语本身出发,哲学和AI有不同的定义。以技术实现为目的,我们更关注AI定义中的自主性、反应性和交互式,暂不讨论尚未形成共识的哲学范畴的意识等问题。
实际上,Agent一直是AI发展中的核心概念。从技术路径看,先后经历了基于规则和基于强化学习两个阶段。AlphaGo和OpenAI早期的游戏Agent即基于强化学习训练,在单一任务、封闭环境中达到了超过人类的水平。 今天的AI Agent建立在大模型的基础上,通过预训练获得了世界知识先验,并以语言作为处理不同任务的接口,使得AI Agent超越了仅依赖强化学习的局限,具备一定的泛化能力和通用性。 根据行为发起主体,AI Agent又可以分为被动响应人类需求的autonomous agent,和具备类人格特征和主动行为模式的generative agent。
以下从任务规划和工具使用两种核心能力、以及应用这三个方面,介绍前一种AI Agent -- autonomous agent的进展。
**1. **任务规划
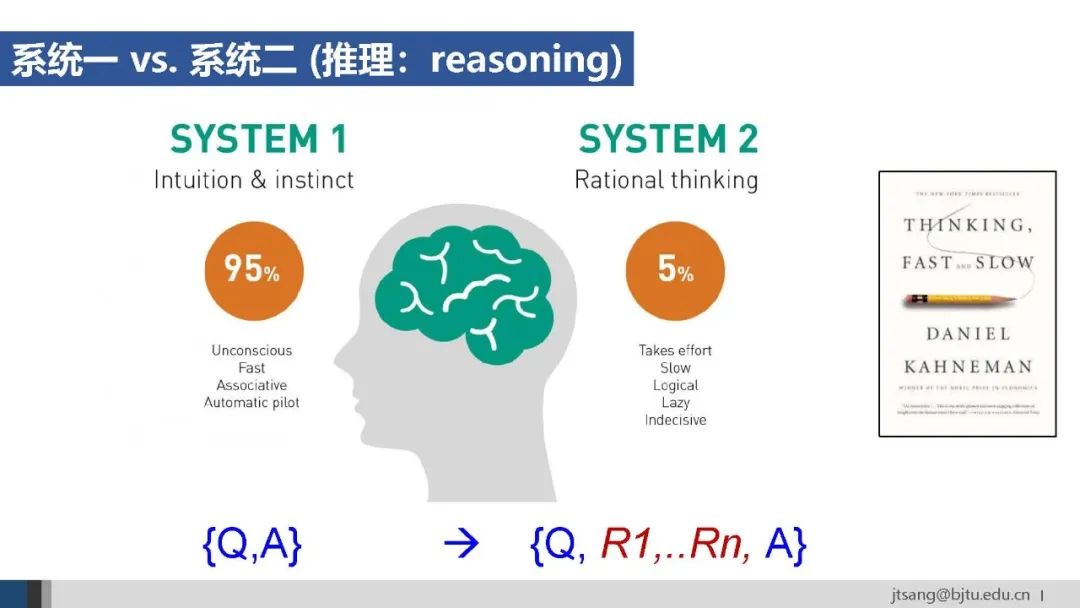
任务规划与人类的系统二能力紧密相关。按照心理学理论,系统一代表直觉,从Q直接到A,属于“快思考”;系统二从Q到A之间增加了多步的逻辑推理,属于“慢思考”。(区分推理和推断:推理reasoning是指模型通过多步骤、结构化的中间过程来得出结论;而推断inference泛指模型生成输出结果的过程,可能基于推理、也可能不基于推理)。
要让大模型实现系统二的推理能力,第一种方法是提示词。 比如思维链CoT、思维树ToT等方法,提供少量包含推理过程的样本示例,激发模型In-Context Learning上下文学习,在线调整其推断行为。
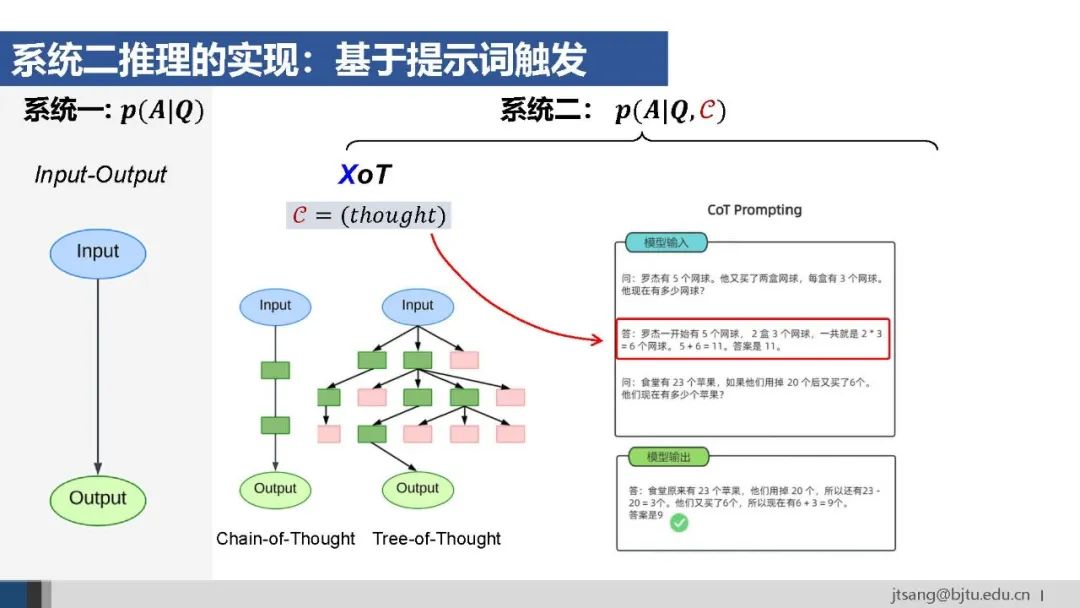
大模型从预训练的多任务学习中学到了捕捉上下文关联的自注意力,提示词相当于在推断阶段增加了一个“条件层”,让模型在进行推断时参考示例中的推理结构,影响其生成结果。
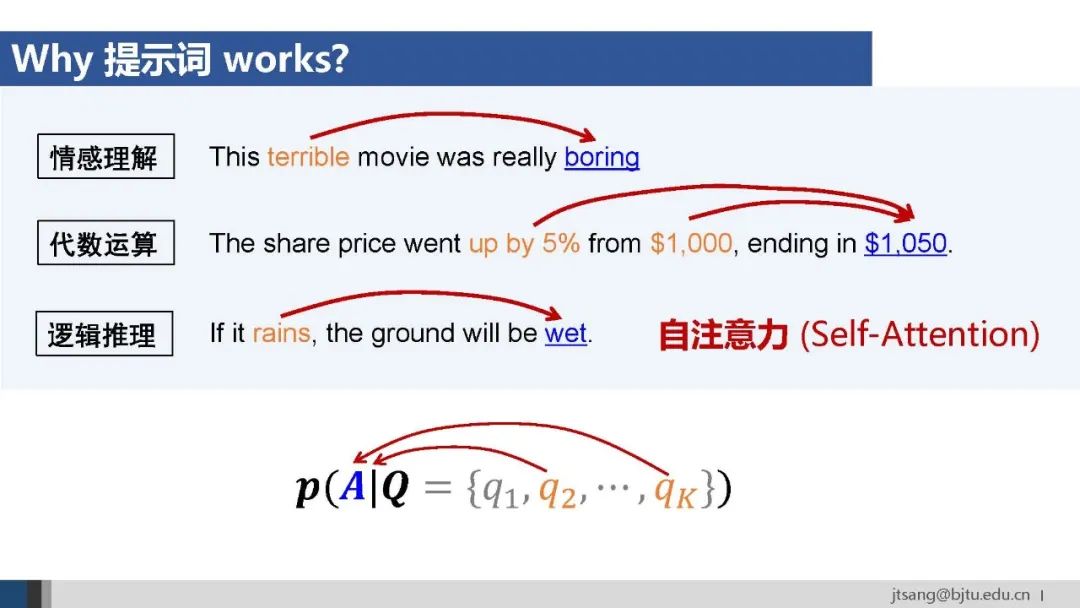
然而,互联网语料主要是 (Q, A) 的形式,这意味着自注意力中学到的上下文关联是在问题和答案之间的。而推理需要捕捉推理过程和答案之间的关联。在推理过程上将p(A|Q)展开后,可以看得很清楚。 因此,最直接的方式还是构造含有推理过程的数据,通过学习将推理能力内化进到模型里。

主要有监督学习和强化学习两种学习路线。监督学习类似师傅手把手教徒弟,像是大学之前的通识教育,提供标准解法和完整步骤。 强化学习则更像研究生教育,导师出了题目,学生自己探索,导师定期给反馈。从这个类比也可以理解强化学习中结果奖励和过程奖励的关系。

以上是从老师的角度,监督学习是“教”,强化学习是“育”。 从学生的角度,监督学习是“学”,强化学习是“习”。别人标注的推理路径不一定适合你,在试错中探索适合自己的路径才是王道。

o1首次展示了基于学习的推理模型的潜力。 之后学术界和开源社区出现了大量复现工作。和预训练需要大规模集群不同,推理模型的学习聚焦后训练阶段,算力资源的门槛相对较低。而且,预训练算法在GPT-3.5之前基本都开源了,加上ChatGPT发布后一年多的时间,大家摸索地七七八八了。但后训练、特别是用强化学习训练大语言模型,有大量待探索的工作。学术界觉得自己又行了。
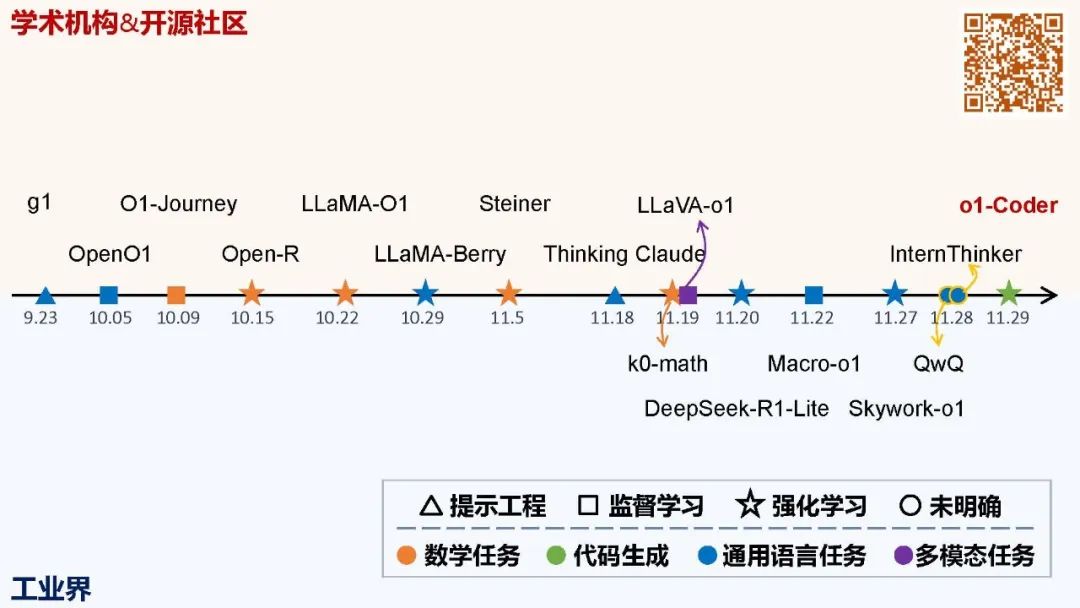
再之后就是DeepSeek R1将推理模型的训练秘籍公开,而且大幅压缩了模型训练和推断成本。
o1验证了推理模型的可行性,R1极致优化效率,降低技术应用门槛。从新技术的早期 demo 出现,到成本降低后的规模化应用,是典型的技术演进路径。
2. 工具使用
AI Agent可调用的工具主要有API接口、数据库和知识库、外部模型等。对于无法API化的外部系统,可以将图形界面交互也封装成工具供Agent调用。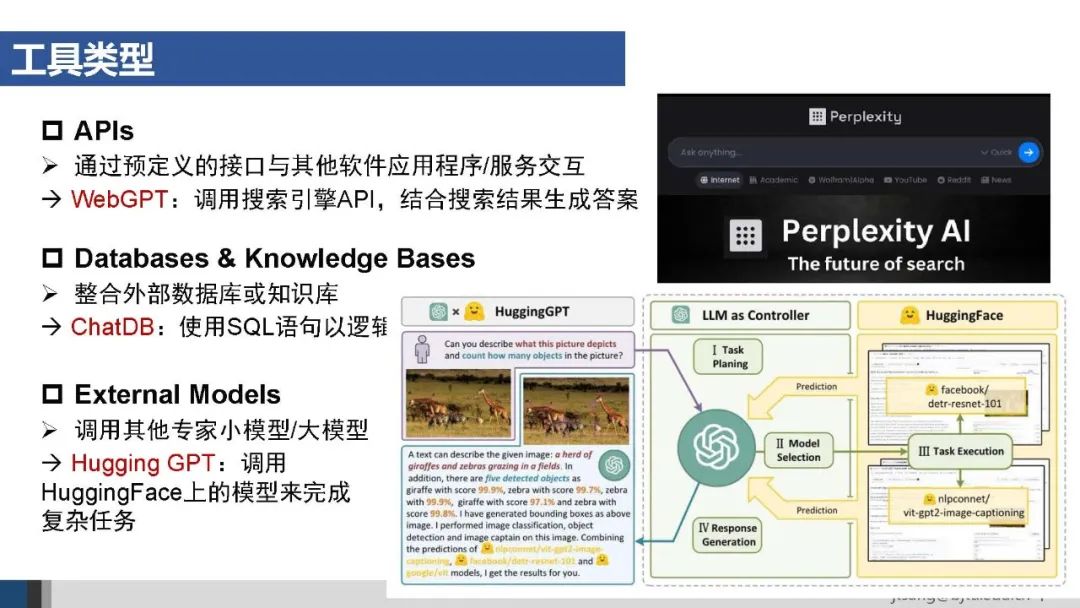
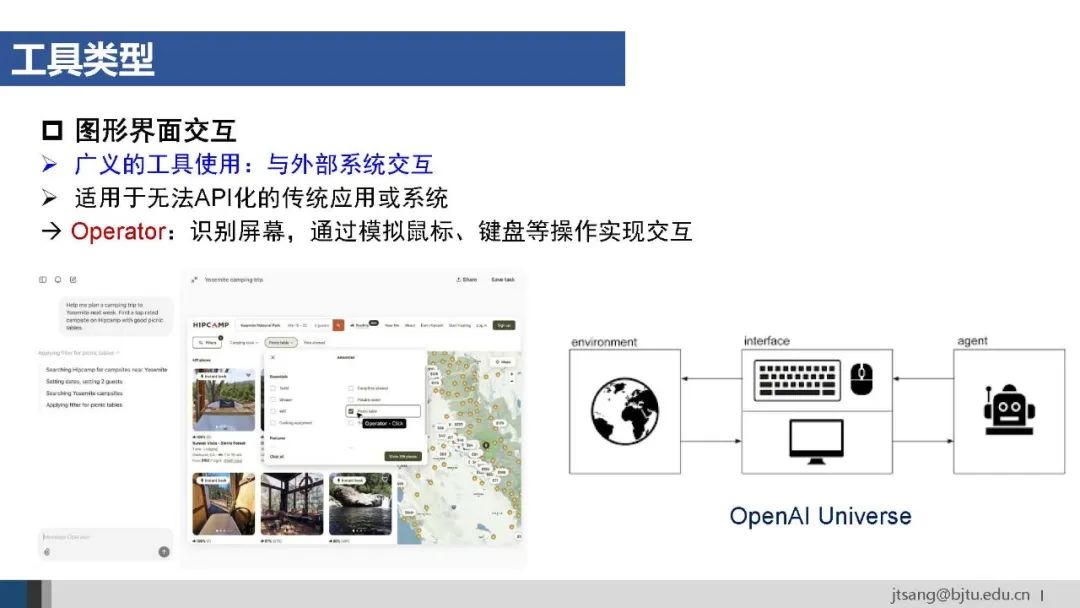
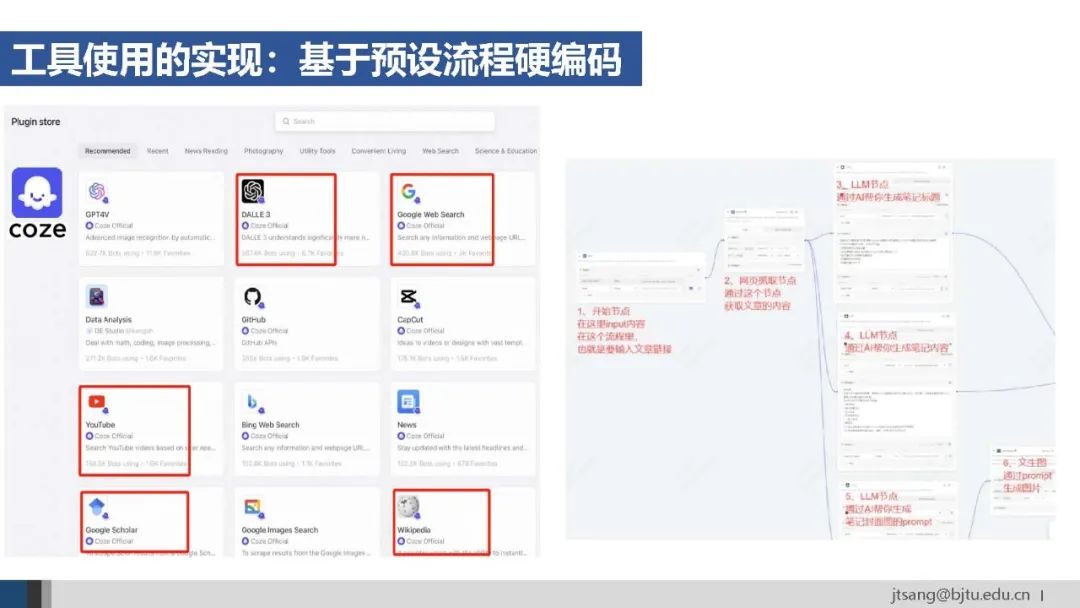
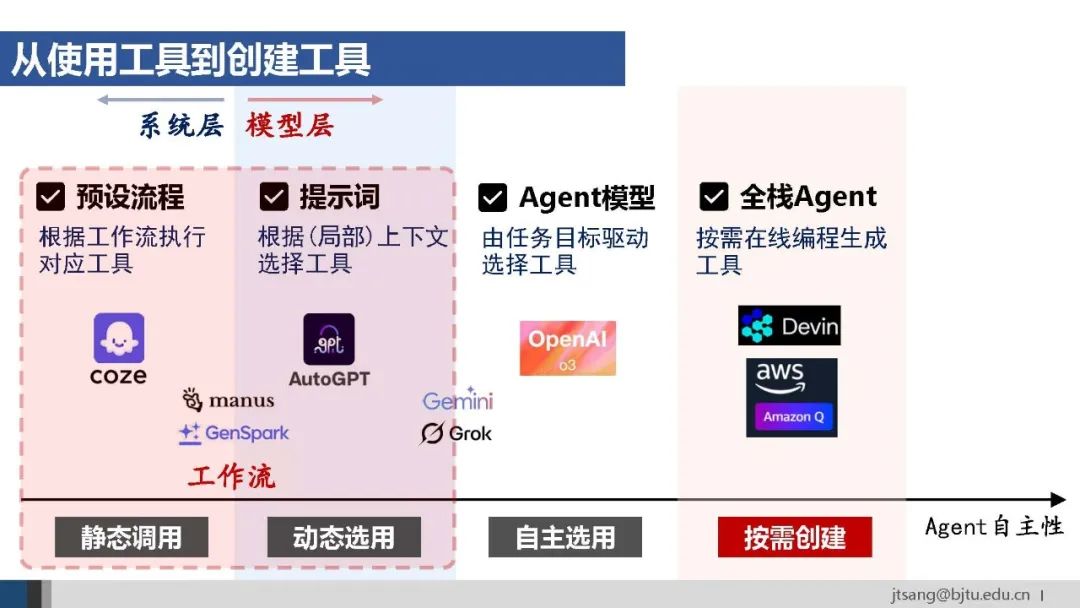
使用工具的第一种方式是**系统层的预设流程,**即通过硬编码方式定义Agent的行为逻辑。 优点是确定性强、可靠,但缺乏灵活性、难以应对开放性和动态变化的环境。字节的Coze是典型的通过设计工作流搭建Agent的平台。
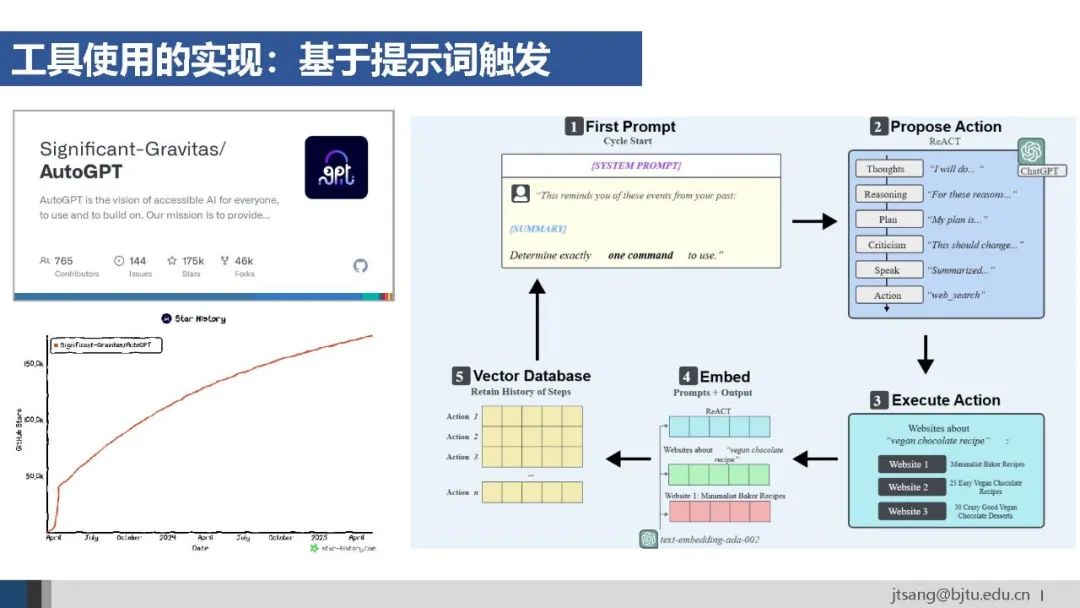
另一种实现方式是**模型层的提示词触发,**引导模型选择合适的工具。这种方式更加灵活,适用于基于局部上下文的任务决策。AutoGPT是早期代表性的基于提示词的Agent框架。
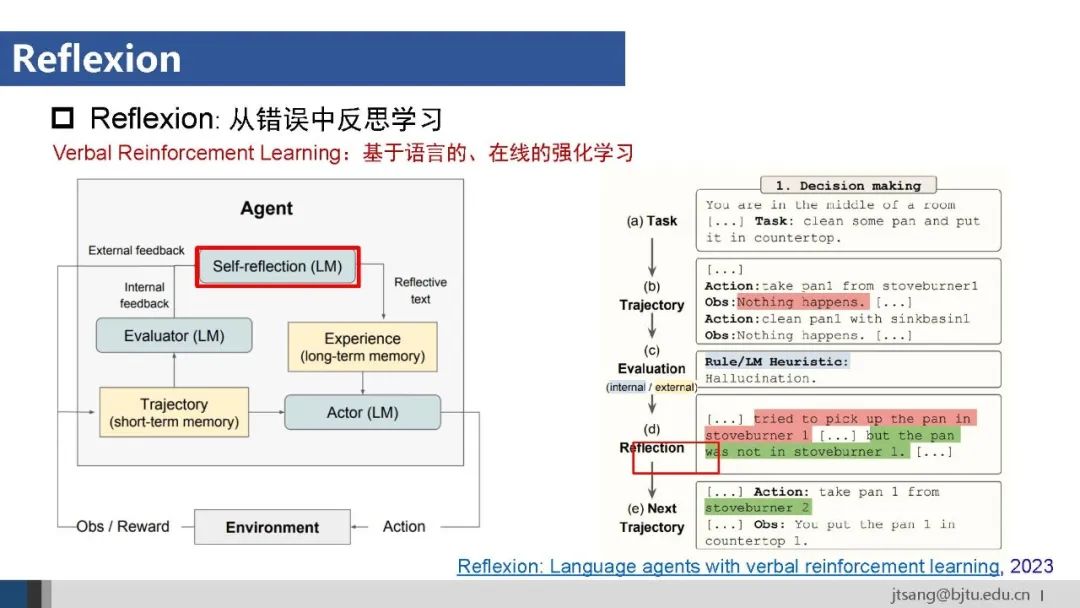
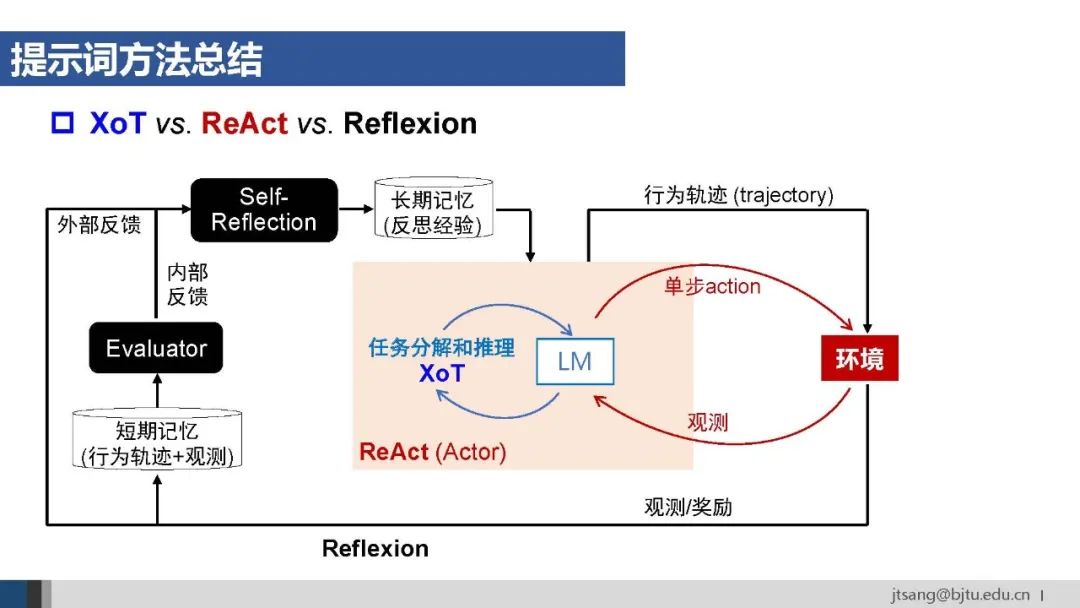
Agent框架使用的提示词方法包括ReAct、Reflexion等。任务规划使用的XoT关注模型内部行为,ReAct通过使用工具与外部环境交互,Reflexion则进一步结合整个行为轨迹,支持Agent从错误中学习并改进行动策略。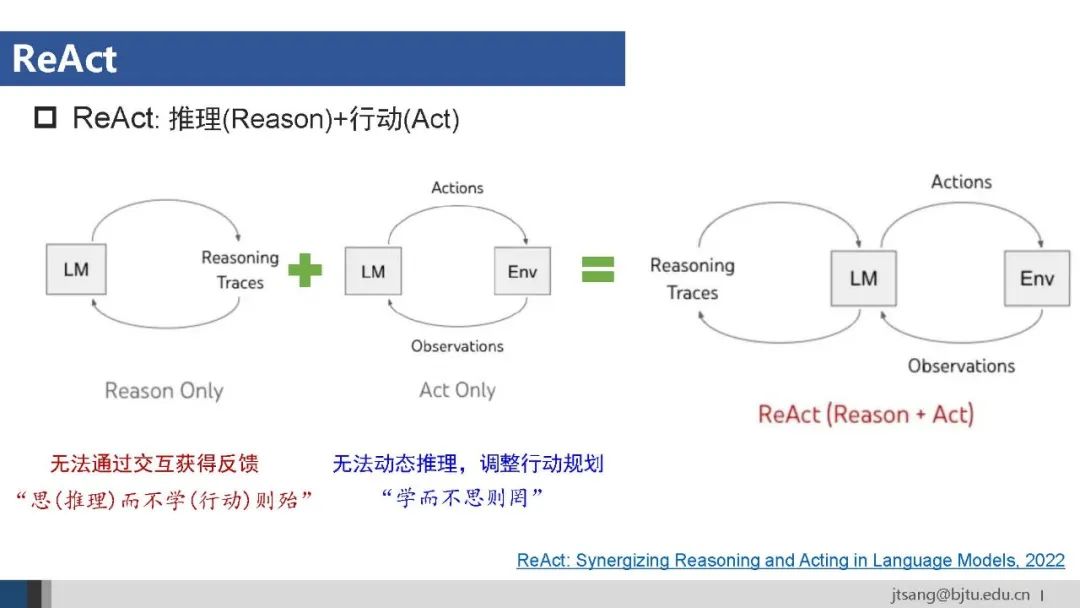
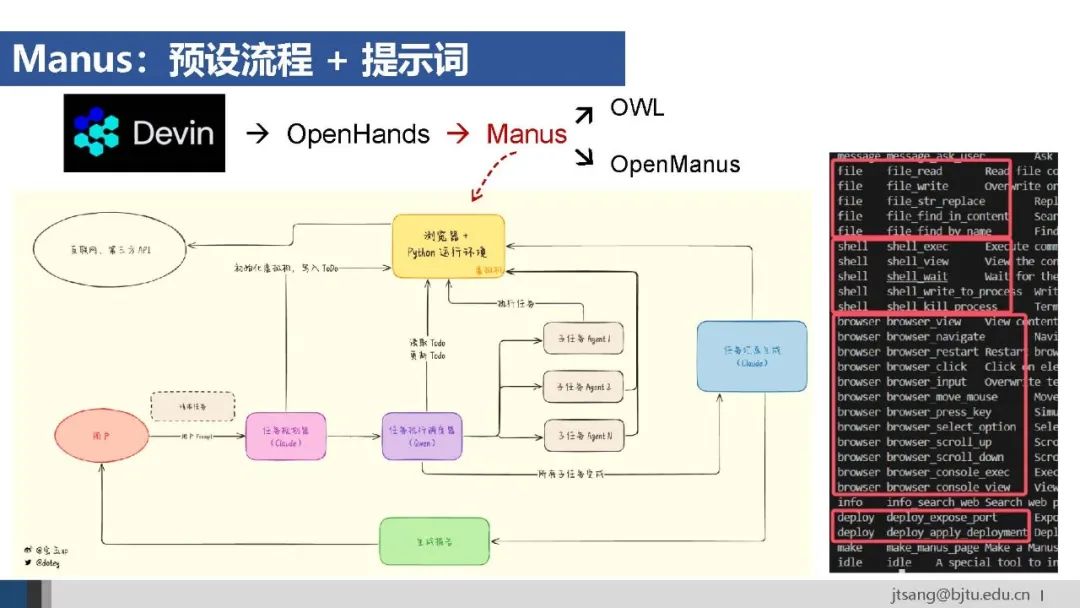
Manus结合使用了预设流程和提示词的方法:预设的任务解决流程是问题分析-任务规划-调用子任务Agent-结果总结等,在每个子任务Agent内部则设计了针对性的提示词。
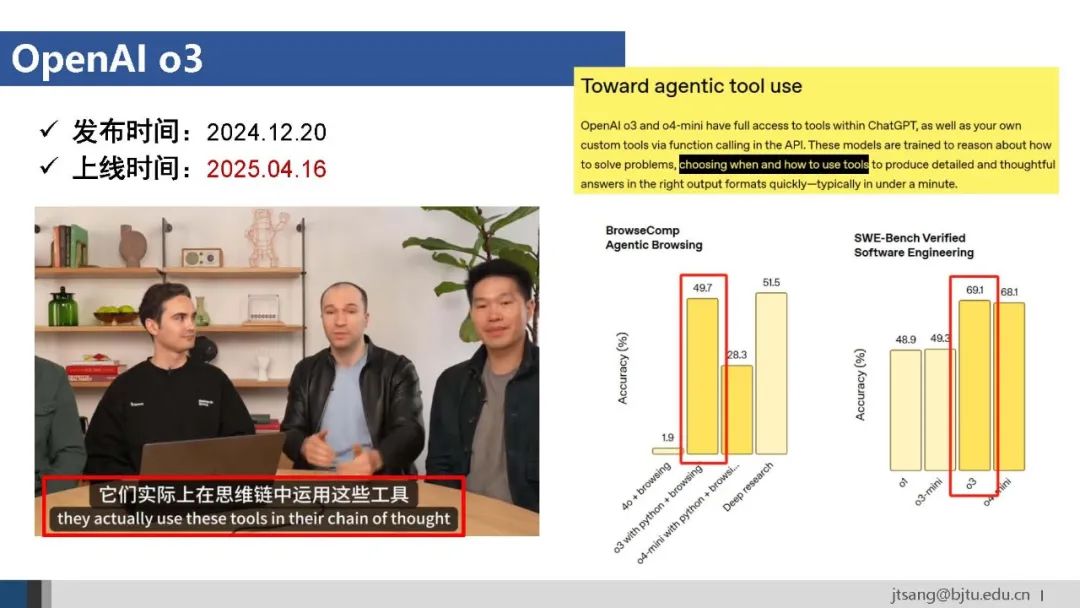
与推理能力类似,工具使用(在推理链中使用工具,Chain-of-Action,CoA)也可以通过学习的方式内化到模型中。 将预设流程和提示词触发两种方式统称为工作流。根据“更少的人工,更多的智能”的原则,基于学习得到的Agent模型应该具有更高的上限。 基于端到端学习的Agent模型o3于4月16日正式上线。Greg Brockman在介绍时明确说o3学习“在思维链中使用工具”。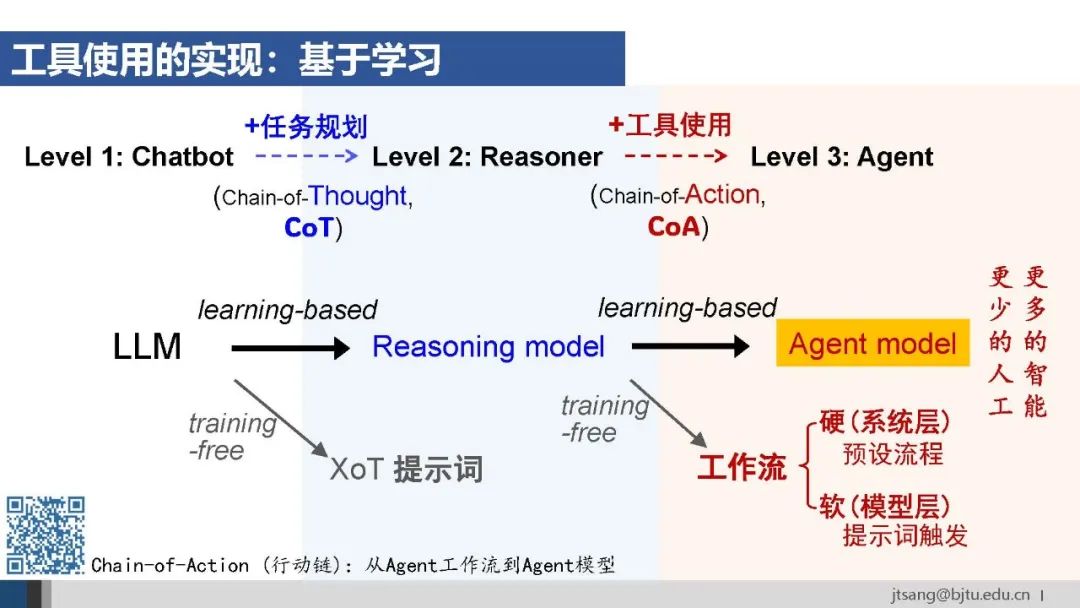
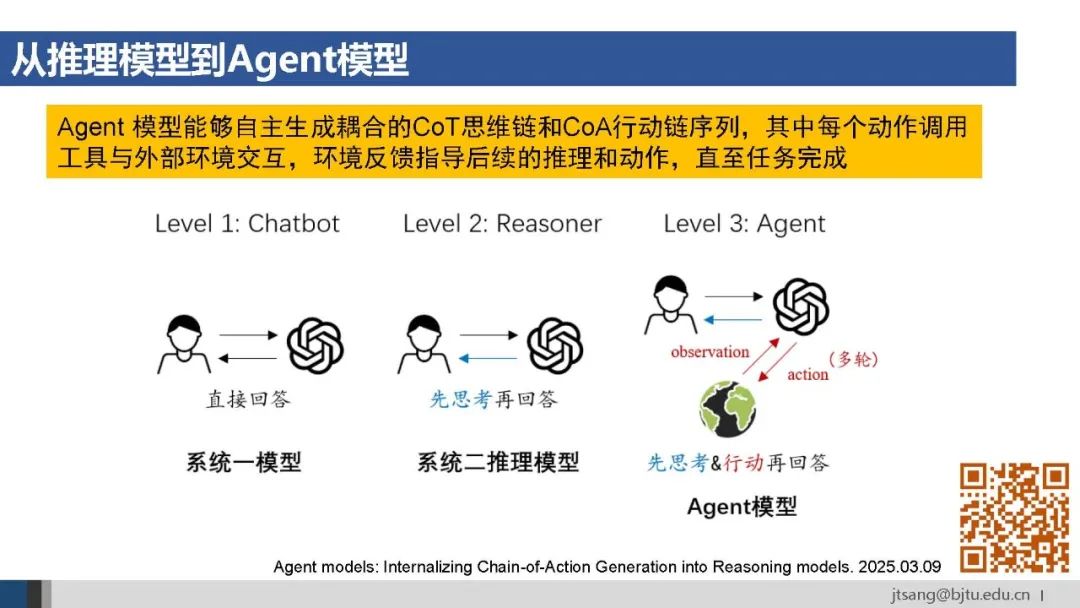
3月初的论文给agent模型下了一个定义。 与LLM和推理模型的人-模型二元结构不同,agent模型要求能够同时进行思考与行动,形成了由人、模型和环境构成的三元结构:使用工具与环境进行交互以获得反馈,经过多轮的思考、行动和观察后,最终生成回复。
推理模型已经具备了通用推理能力和单点的工具使用能力。Agent模型训练旨在面向任务目标,端到端训练模型在推理过程中的链式工具使用能力。 如同研究生通过完成学位论文,才能掌握如何整合查阅文献、做实验、绘制图表这些单个技能完成一个复杂的任务。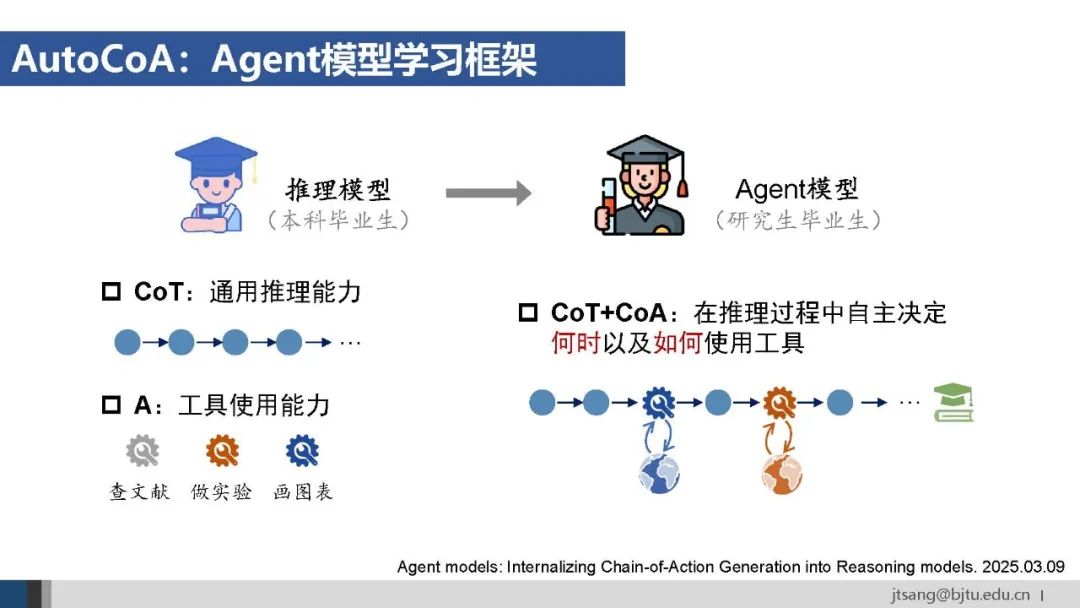

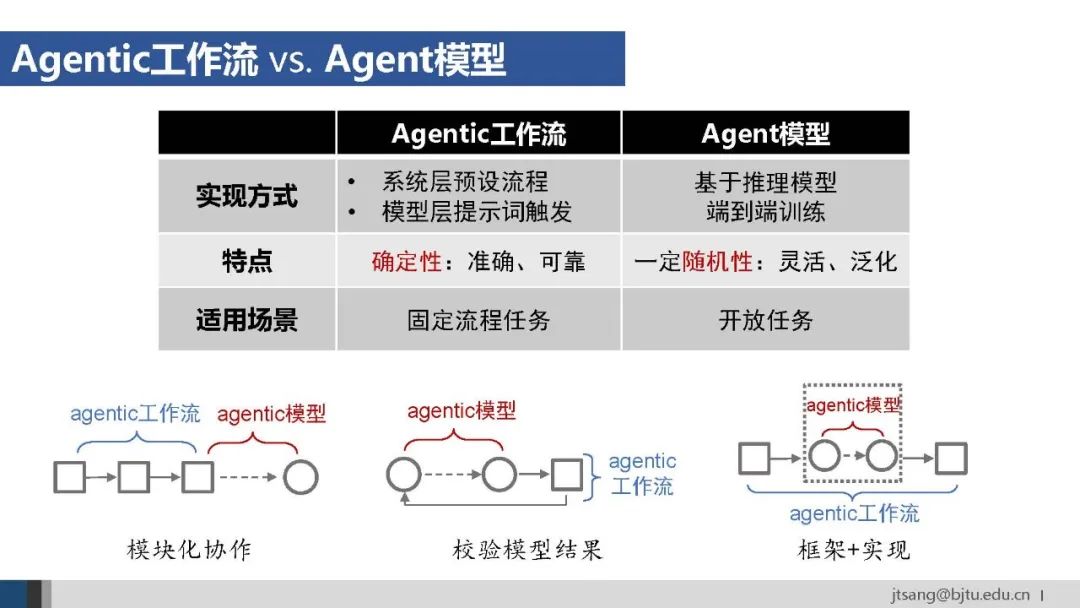
端到端训练的Agent模型,由于面向任务目标进行了策略优化,其选择的工具和工具使用参数是面向全局任务目标生成的。 相比之下,提示词触发的agentic工作流方法,模型虽然也有一定的自主灵活性,但行动是单步进行的,只能根据局部上下文做出选择。

Agent模型探索能力上限,Agentic工作流保证任务执行下限,二者在很长时间内将结合使用。 三种可能的结合方式:(1)模块化协作,确定性流程使用工作流,灵活性需求使用Agent模型;(2)校验模型结果,通过工作流对Agent模型的输出进行校验,减少模型的随机性和幻觉不确定性等问题;(3)框架+实现,工作流搭建顶层确定框架,模型实现底层灵活和智能。
随着自主性进一步提高,工具也将由agent通过在线编程按需创建。一些全栈开发的agent,比如Devin、亚马逊的Kiro都在实现类似的功能。
3. AI Agent应用Operator和Deep Research代表了目前AI Agent的两个主要应用方向:操作action agent和信息information agent。前者扮演“眼和手”的角色,擅长环境交互与自动化操作,适用于重复性强的操作密集型任务。后者扮演“大脑”的角色,擅长知识整合与复杂分析,适用于知识密集型任务。

实现方式上包括GUI Agent、API Agent和多Agent三种。 其中多Agent,比如荣耀的OS Agent “YoYo”调用中移动的App Agent“灵犀”,目前看是使用大型App、兼顾通用性和效率的可选方案。

GUI Agent和API Agent代表了看待未来AI发展的两种思维。GUI Agent代表的是让AI适应人类的数字世界,人形机器人即是让AI适应人类的物理世界。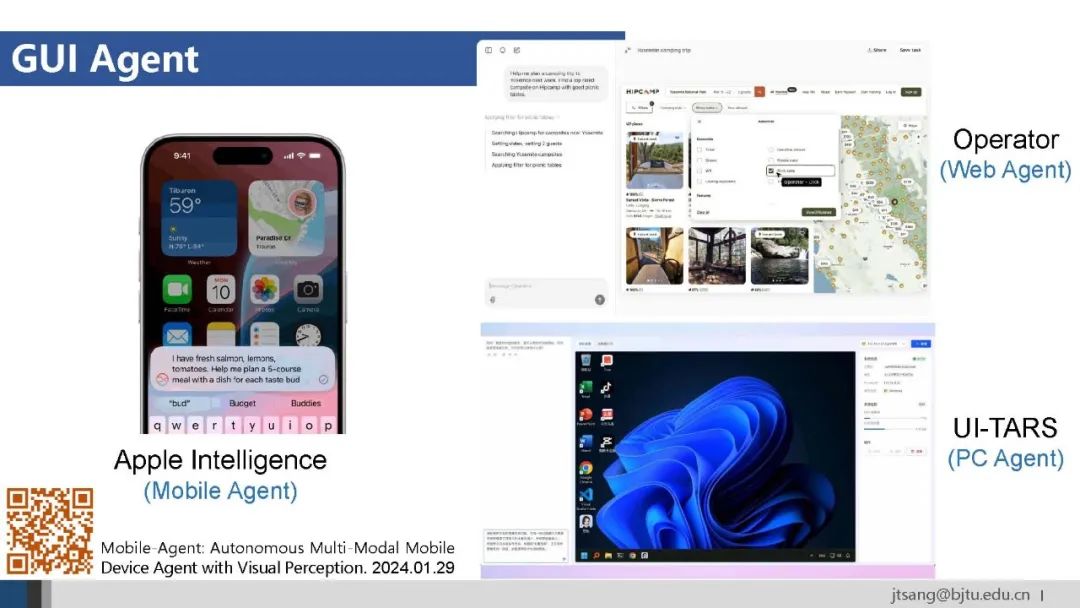

相比物理世界改造的困难,数字世界的改造要相对容易些。API Agent则希望为AI创建一个原生的世界,包括为AI专门设计的工具、交流语言等。

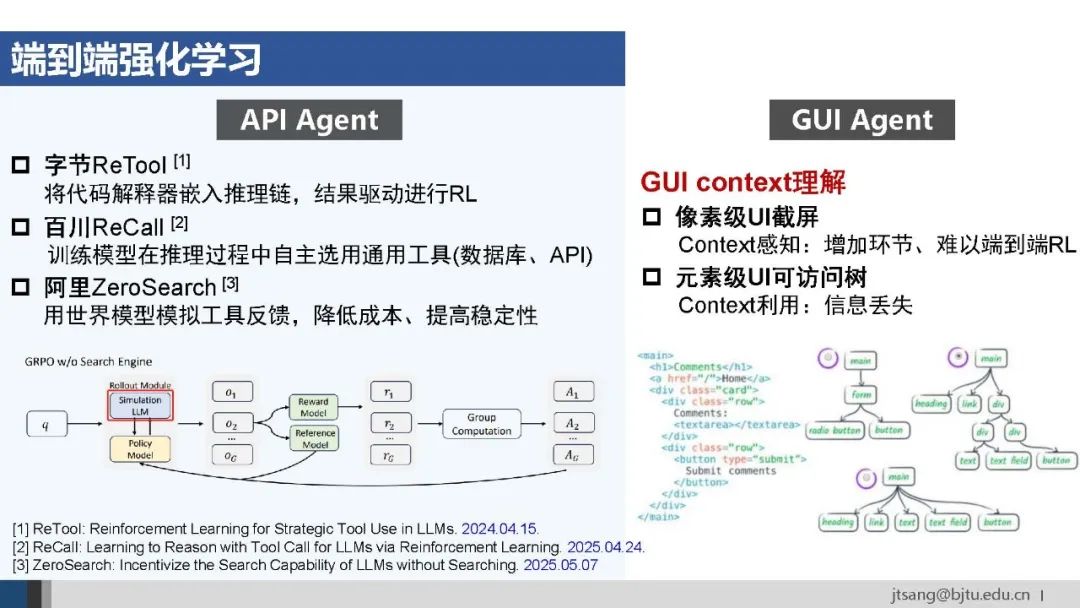
AutoCoA的框架主要面向的是API Agent。从4月中旬开始,几个大厂密集发布的工作,也证明端到端RL在API Agent上是跑得通的。 但在GUI Agent上,强如字节的UI-TARS,RL也只能在单步行动上训练。 问题可能出在是对GUI context的理解上:截屏的方法增加了感知环节,使得端到端训练难以进行;可访问树的方法由于信息丢失,会影响上下文信息的利用。
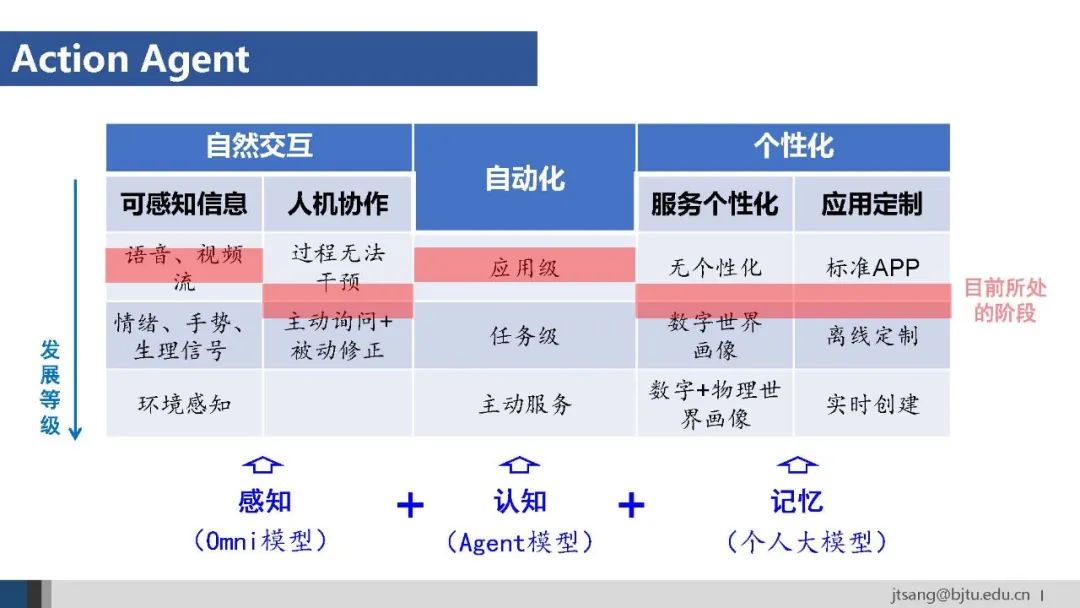
Action agent目前主要在各类终端上。Agent入口的层级从高到低有应用级、系统级和硬件级。 微信将元宝直接放到联系人中,再次体现了腾讯作为连接器的定位:通过微信连接人和信息-公众号,连接人和服务-小程序,甚至连接任何交易-微信支付。 终端agent应该具备自然交互、自动化、个性化三个特点。分别对应了感知、认知和记忆三方面主要能力。
Information agent从基于单次搜索的信息查询,发展到基于多次搜索的知识服务。
OpenAI的deep research进一步实现了面向任务完成的多次搜索优化,代表了未来AI Agent应用的重要方向。 人的信息处理能力,从查询、总结到综合分析,目前information agent已基本具备。更高级的创造能力,除了模型智能的提升,还需要更多的API接口、以及融合action agent与物理世界打通提供更多元的外部信息才可能实现。

关于AI Agent应该通用还是垂直的讨论。 从任务特点看,agent与chatbot和reasoner不同,关注的是具体任务的执行,这也是“AI下半场”的另一种解释:从刷通用能力的benchmark到解决具体任务。从实现方式看,工作流的方法需要面向任务设计具体的执行逻辑;基于RL学习的方法,则需要根据任务目标,设定准确的环境奖励。

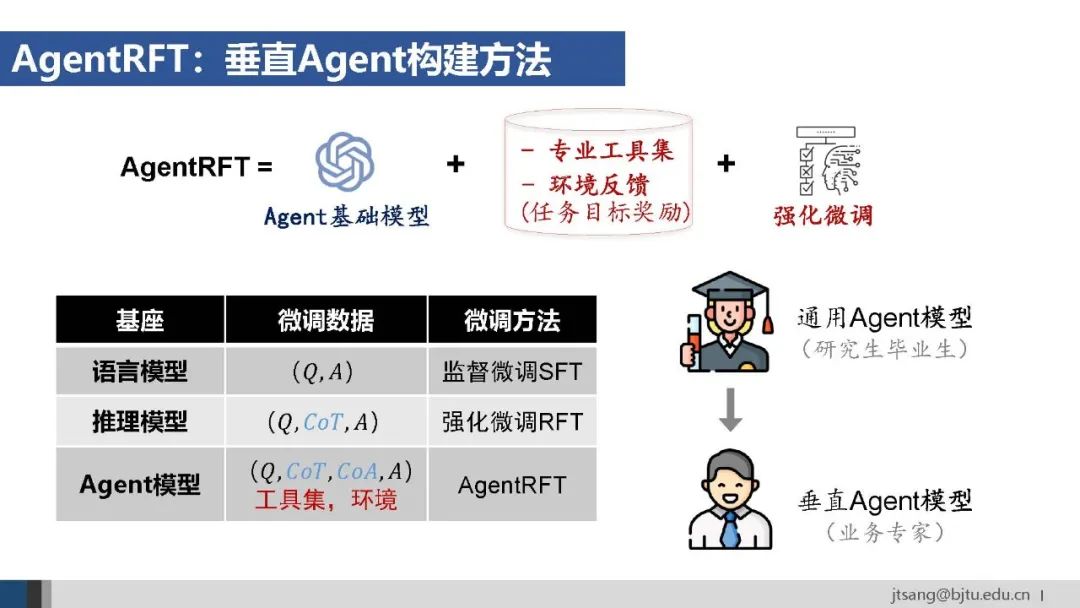
对o3等agent基础模型微调获得垂直agent的通用公式是:准备完成任务所需的专业工具集、受控环境内可验证的任务目标,然后进行强化微调。 随着o3、Qwen3等Agent基础模型成熟,就好像高素质的研究生毕业生供应增加。企业需要接下来结合具体任务继续培养,在特定工作上训练成为业务专家。 端到端训练垂直Agent,已经在广告(ICON)、网络安全(XBOW)、软件开发(Traversal)等领域有了成功案例。
OpenAI开始用可替代的人类专家工时评估模型的能力,这表明agent逐步作为一种服务成为生产力。 Agent的生产力由模型智能、工具多样性和数据专业性三个因素决定。应用层不仅要承接最新模型成果,还需要从工具和数据两个方面向下优化模型。 与chatbot失效的数据飞轮不同,在agent阶段,普通用户的行动流数据对于提升模型能力还是有用的,所以AI Agent产品目前仍然存在数据飞轮。OpenAI收购Windsurf,很大程度上是看重其丰富的开发者agentic行为数据。对比传统软件通过需求分析确定高频、标准、静态的需求,基于Agent的服务可以满足长尾、个性化、动态的需求。基于Agent的新一代软件的界面可能被高度简化为一个对话框,传统复杂的操作过程被隐藏,成为面向目标的服务交付。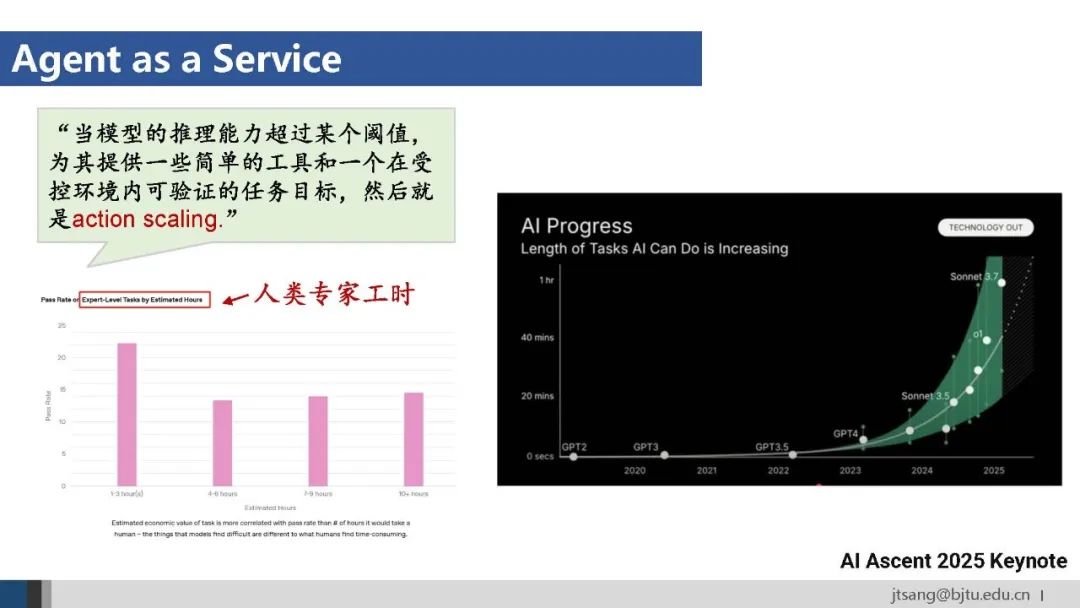
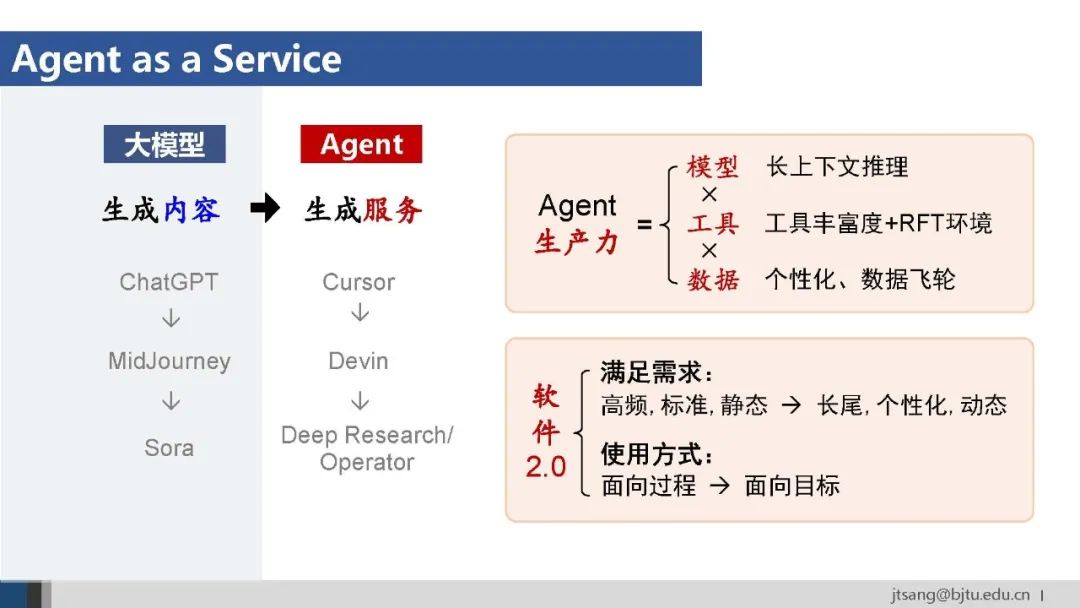
如乔布斯40年前的预言,从how to do、what to do,到what I want,用户只需描述“我想要什么”,Agent自动完成“怎么做”。AI Agent代表了新的抽象层,已经无限接近人类思维。 正如网页和App是互联网信息的应用载体,agent是智能服务的载体。Agent的设计,因此应该更充分地发挥AI整合底层数据资源和工具生态的效率和能力。

这需要action agent和information agent的深度融合。马斯克曾说:电脑和手机是人的数字延伸,其带来的无限信息访问能力已经可以让我们成为超人了。
让AI像人一样操纵电脑,从而接管一切人类在屏幕前完成的工作,是OpenAI成立时就定下的目标。 随着action agent接入更多I/O,information agent可使用更多工具,AI Agent正在突破人类肉身的物理限制,可以以无限带宽连接世界。这不仅是完成人类的任务,更是让agent自主、持续地从人类世界学习和进化的方式。
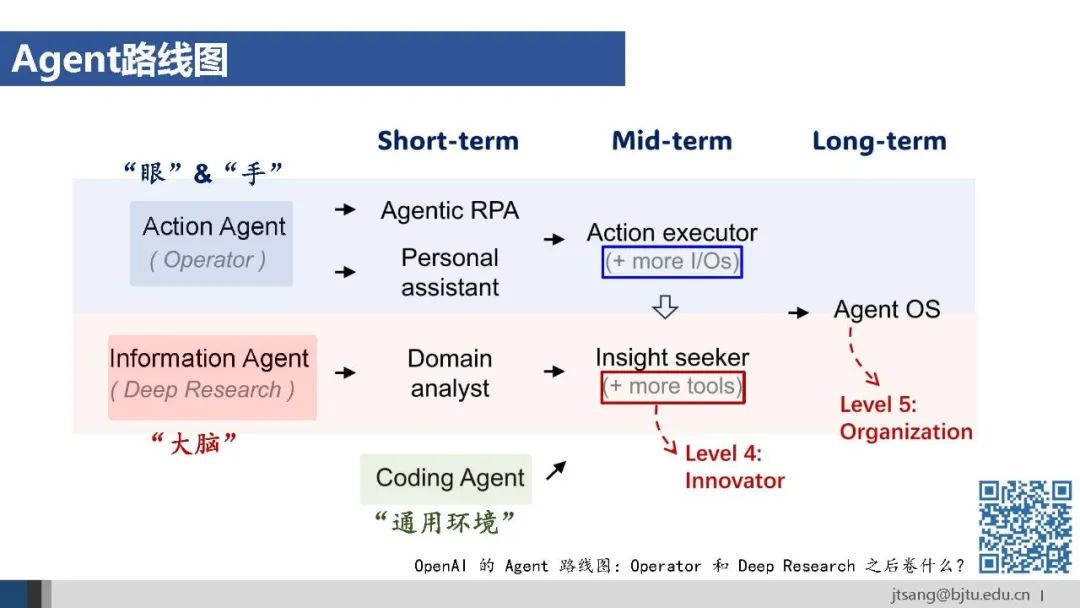
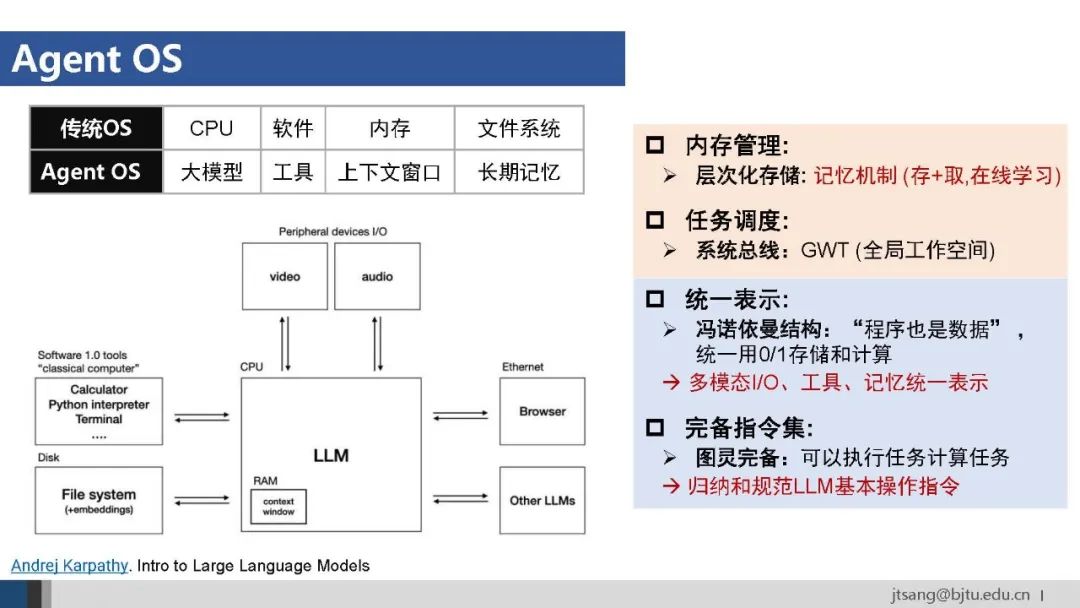
Agent OS将成为AI Agent的运行基础。
任务规划、工具使用和记忆是AI Agent的三个基础能力。关于记忆,“大海捞针”评估的主要是单点信息检索的能力,agent解决复杂任务需要的是上下文理解和全局推理能力。 最近一年已经看到了任务规划和工具使用能力的发展,期待记忆机制的突破。
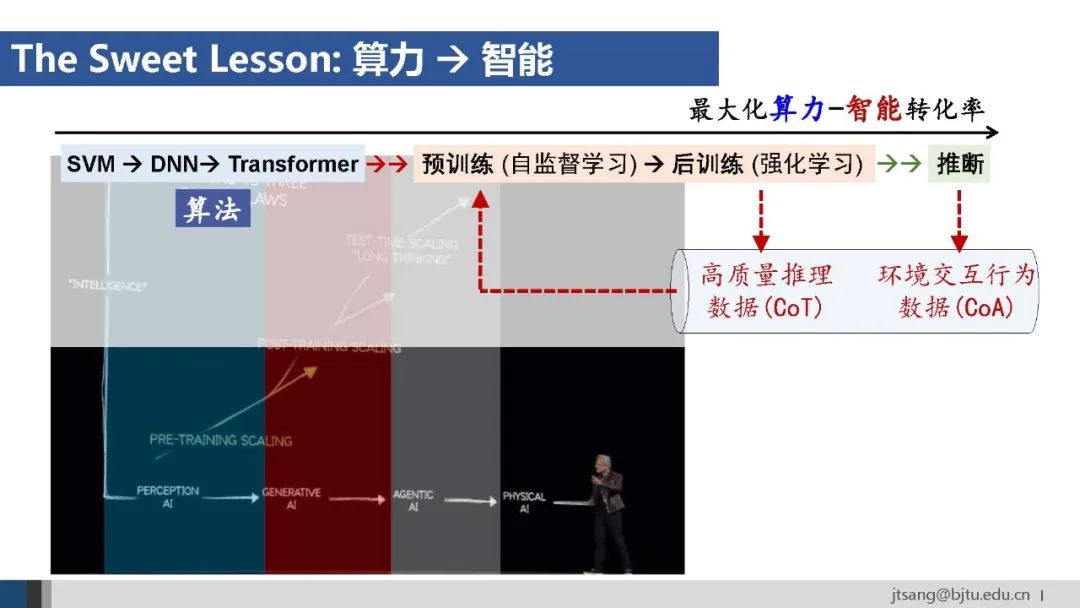
回到黄仁勋的主题演讲。 预训练、后训练、推断三阶段的scaling law,支撑着目前生成式AI和Agentic AI的发展。