全域作战 (ADO) 是美国军事联合概念的演变,旨在应对战略对手,他们希望利用战争的新兴特征来破坏和克服美国在日益复杂和全球战场上的优势。ADO作为一个概念很重要,因为它同时认识到作战环境的复杂性以及对手打算如何在其中实现战略优势。这个概念描述了美国陆军如何在巩固成果的同时,使联合部队能够防止、拒绝和利用对手。随着多域作战环境的出现和美国陆军寻求在未来获得并保持持久的优势,继续发展ADO概念将至关重要。
兵棋推演继续作为军事组织的一项关键职能和工具。兵棋推演工具根据玩家的决定,以不同程度的现实和抽象来模拟过程和后果。兵棋推演理论对美国陆军领导力的开发至关重要,因为它提供了一个过程,通过抽象的机制将关键的决策还原成一个反复的过程,使人们能够探索失败并奖励学习,以做出更合适的决策。兵棋推演是测试ADO概念的关键因素,也是培训和教育未来领导力的关键方法。
ADO的关键是发展理解概念和作战环境的能力。ADO推演允许领导者和军事理论家学习和探索作战环境,包括对手与美国和盟军在作战环境中的能力。设计一个关于ADO作战概念的兵棋推演工具,可以创造一个框架,在这个框架内,领导者可以练习规划、执行和反思关键因素。这篇论文提出了一个概念证明,即通过教育和培训,重点关注陆军的ADO规划和执行的作战方法,以促进未来的领导力开发。
引言
战争是永远存在的。在某种不同程度上,行为者总是为冲突做准备或参与冲突。战争的特征和现代战争的概念在时间上无情地向前推进。美国的战争专家和政策制定者主要认为,全域作战(ADO)是未来的战争概念。全域作战代表了美国军队在2020年和不久将来的现代联合作战概念和方法。这一概念将空中、陆地、海洋、网络空间、电磁和太空领域整合在一起,进行跨时空的规划和同步执行。ADO固有的复杂性要求领导者对跨领域的能力、规划和执行有一定的了解。
从战术层面开始的领导力开发路径限制了联合和作战经验。对ADO的理解和更好的执行需要领导者在经验发展的早期学习规划和实施新生的概念。到目前为止,真实世界的亲身体验是最好的,但很难复制,在联合作战中更是如此。兵棋推演提供了一个补充教育和培训的工具,利用机械原理来帮助对问题和决策过程的理解框架。一个全面的兵棋推演工具对于ADO中未来作战领导力的开发是至关重要的。
本报告的目的是展示兵棋推演如何为美国陆军在ADO中的角色开发和领导力培养提供方法。该研究旨在为对ADO感兴趣的领导人提供一个基础,并通过兵棋推演进行开发和教育。本报告展示了兵棋推演如何模拟ADO的概念,以指导和促进教育。兵棋推演的目的包括跨越时间和空间,通过所有领域来规划和管理军事行动,同时在与ADO相关的各个阶段纳入作战艺术和科学元素。兵棋推演模型应能适应任何场景,并采用模块化设计,允许根据需要强调背景。设计者根据现有的作战框架,通过在至少两个主要对手之间的偶发阶段来开发兵棋推演工具,从而实现反思和讨论。本报告提供了一个概念证明,即作为进一步开发的基线Theatrum Belli,并解决了陆军理论中关于兵棋推演的一个重要空白。
在陆军兵棋推演中,ADO的概念和理论存在一个重大的空白。很少有现有的模型能以现代的方式将所有的五个战争领域都纳入其中,以适当地呈现ADO的要素。此外,美国陆军缺乏一个模拟的、标准化的模型来最好地描述从师到战区陆军在作战层面执行 ADO。美国空军和美国海军目前正在开发一个以ADO为导向的兵棋推演,但仍然没有纳入大量的地面部队。本报告提出了一种兵棋推演的设计,能够在作战层面上对ADO的规划和执行的领导力进行教育和开发。鉴于该兵棋推演的主要目标,设计者必须承认该模型和研究的局限性。
第一手和真实世界的经验是最好的学习环境。然而,在作战层面为ADO创造一个真实世界的训练环境,在时间、物质和人员上的成本可能是令人望而却步的。兵棋推演是一个有明确目标的模型,它准确地描述了至少两个对立面之间的一些战争要素。为了实现这个明确的目标,必须对设计的因素进行优先排序。该模型只模拟了现实和战争的某些部分,优先用于实现兵棋推演的目标。设计的细节越精确、越全面,它就越复杂。兵棋推演通常会牺牲不同程度的精确性来实现简单性,以减轻参与者所需的时间和精力成本。设计的目的是在ADO上进行指导,这也带来了其他的限制。兵棋推演可以通过多次迭代来教授类似的学习目标,但对现实的每一次抽象都意味着模型的应用在任何时候都只能解决这么多问题。
兵棋推演的获取和可用性是对拟议的兵棋推演的关键限制。兵棋推演中的任何机密材料都会大大降低大多数专业军事教育(PME)项目的准入门槛。由于缺乏机密材料,该设计不可避免地掩盖了ADO固有的某些方面。这使得一个用于训练和教育目的的模型能够得到更广泛的传播,甚至可能包括盟军部队。此外,该模型的扩大传播鼓励了PME之外更广泛的参与,这可以进一步创新和调整未来的迭代。除了所讨论的本报告的局限性外,设计过程的范围更好地定义了设计方法。
本报告的兵棋推演设计范围提出了一个课堂环境的概念说明,以补充ADO的学习。因此,重点支持实现具体的学习目标,只需要教师和学生的必要时间和努力。一个兵棋推演如果吸收了太多的时间,无论是学习操作还是执行本身,对任何有时间安排的人来说都会成为一种负担。为了解决参与者的注意力问题,兵棋推演的模式必须是高效和简短的,但仍然包括促进学习目标的机制。教员通过兵棋推演来管理学生的注意力,并需要利用剩余的时间来发挥综合作用,而不是让学生筋疲力尽。为了补充高级军事研究项目(AMSP)的课程,设计应该以研讨会的环境为基线。这种形式可以扩展到旅以上梯队的工作人员,在几个小时内执行迭代,而不是全天的事务。设计的迭代性质适合于情节性的场景,参与者可以用默认的标准跳入和跳出场景,或者在不同的情节之间进行进展,以实现持续的连续性。这是对兵棋推演范围的一般性介绍,本报告将在后面对其设计背后的理论作进一步的详细说明。
本报告的引言阐述了论文和主要目的,确定了重大差距,以及兵棋推演设计的局限性和范围。下一节涵盖了所研究的文献、理论、概念和以前的兵棋推演,以及它们对拟议设计方法的应用。
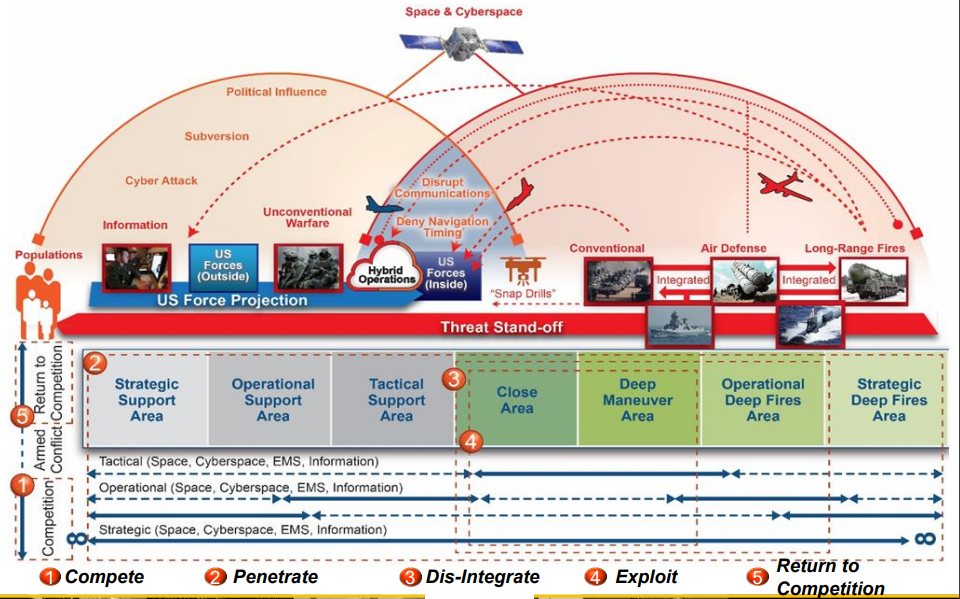
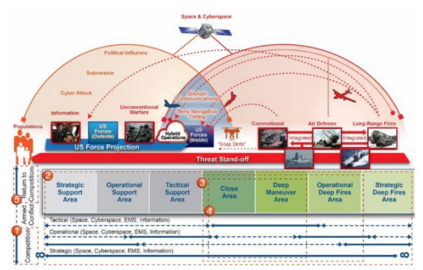
图4. 在MDO框架中强调的军事问题。