
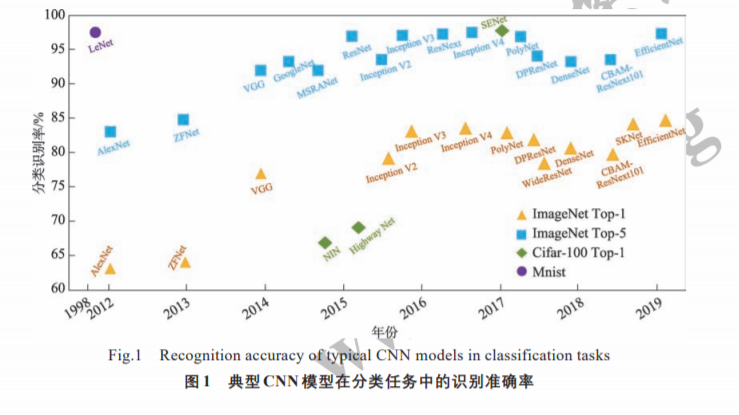
深度学习是机器学习和人工智能研究的最新趋势,作为一个十余年来快速发展的崭新领域,越来越受到研究者的关注。卷积神经网络(CNN)模型是深度学习模型中最重要的一种经典结构,其性能在近年来深度学习任务上逐步提高。由于可以自动学习样本数据的特征表示,卷积神经网络已经广泛应用于图像分类、目标检测、语义分割以及自然语言处理等领域。首先分析了典型卷积神经网络模型为提高其性能增加网络深度以及宽度的模型结构,分析了采用注意力机制进一步提升模型性能的网络结构,然后归纳分析了目前的特殊模型结构,最后总结并讨论了卷积神经网络在相关领域的应用,并对未来的研究方向进行展望。
地址: http://fcst.ceaj.org/CN/abstract/abstract2521.shtml
成为VIP会员查看完整内容
相关内容




相关VIP内容
相关资讯
相关论文