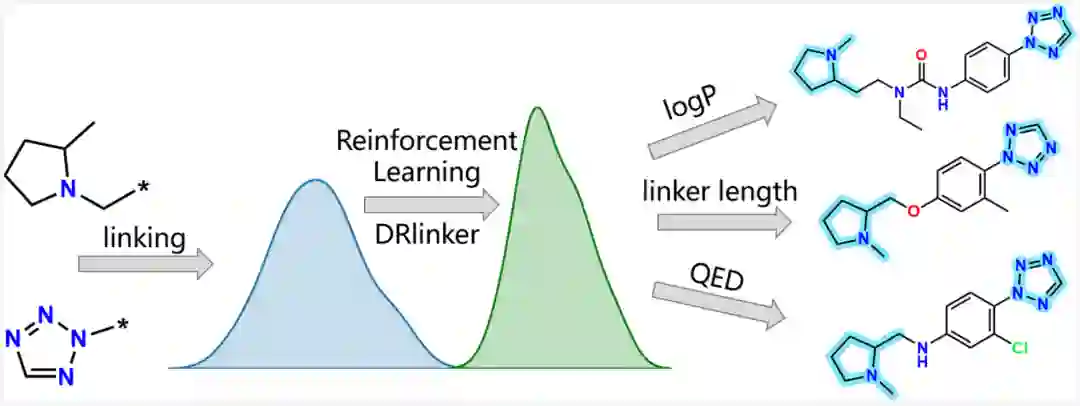
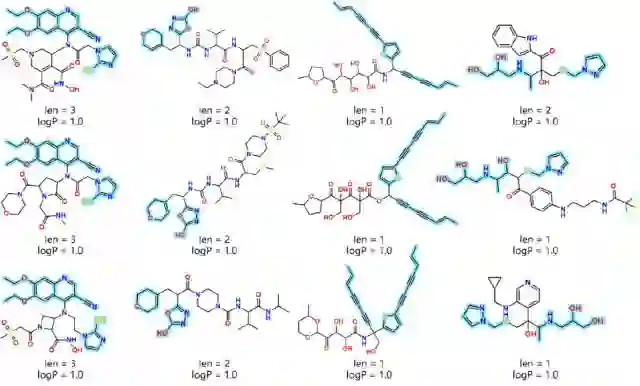
2022年11月20日,中山大学计算机学院杨跃东教授团队与广州国家实验室陈红明研究员团队在Journal of Chemical Information and Modeling期刊上发表论文DRlinker: Deep Reinforcement Learning for Optimization in Fragment Linking Design。论文提出了用于优化片段连接设计的模型DRlinker,其具有优秀的性能表现,在基于片段的药物设计中具有一定的优势和适用性。

1 摘要基于片段(Fragment-based)的药物发现是学术和制药行业中广泛使用的药物设计策略。尽管片段可以通过最新的深度生成模型连接起来以生成候选化合物,但生成具有特定属性的连接子(Linker)仍然存在问题。在这项研究中,作者提出了一个新框架,DRlinker,通过强化学习来控制片段与给定化合物的连接。
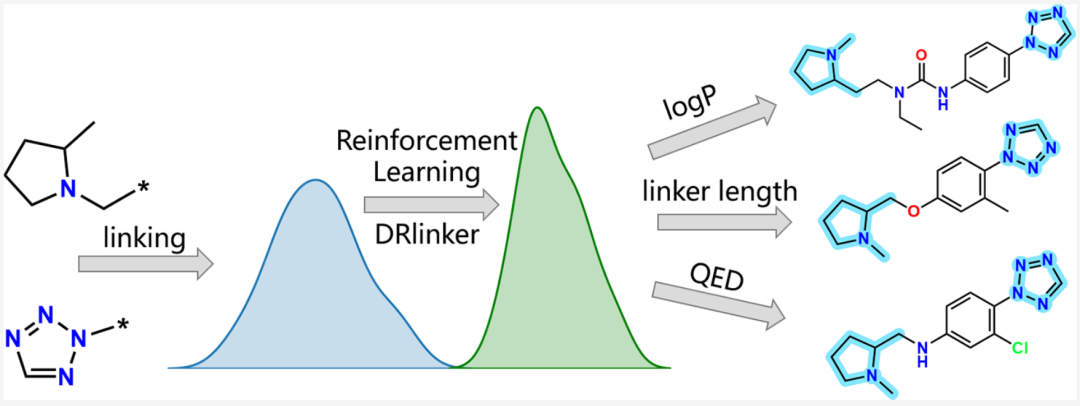
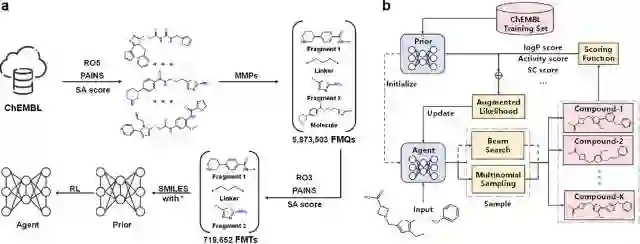
该方法已被证明是从连接子长度和、优化化合物预测的生物活性到各种多目标任务的有效方法。具体而言,模型生成的化合物中,符合所需连接子长度要求,符合要求,并在生物活性优化中提高了 pChEMBL值。最后,quasi骨架跳跃(quasi-scaffold-hopping)研究表明,DRlinker可以生成与先导抑制剂具有高3D相似度但低2D相似度的近30%的分子,这证明了DRlinker在基于实际基于片段的药物设计中的优势和适用性。 2 方法模型的目标是将末端片段(terminal fragments)与所需的属性关联起来。关联通过Transformer转换为端到端的句子补全过程,其中输入是一对片段的SMILES,包括切割点“*”,输出是完整分子的SMILES。为了保持期望的性能,作者采用了强化学习来指导完成。如图1所示,整个工作流由两个阶段组成。在第一阶段,Transformer模型基于ChEMBL数据进行训练,生成Prior模型。然后,使用基于策略的强化学习(policy-based reinforced learning, RL)方法对先验模型进行训练,以通过评分函数的辅助来优化属性,从而生成智能体(Agent)模型。在RL训练期间,Agent旨在为具有预期性质(例如,和生物活性)的新颖和多样分子采样所需的化学空间。
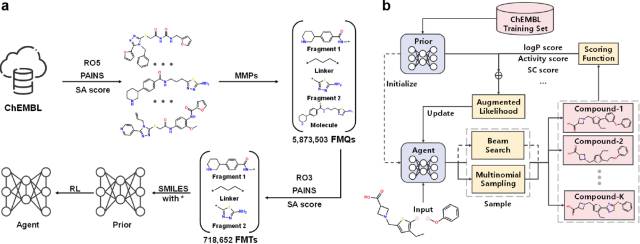
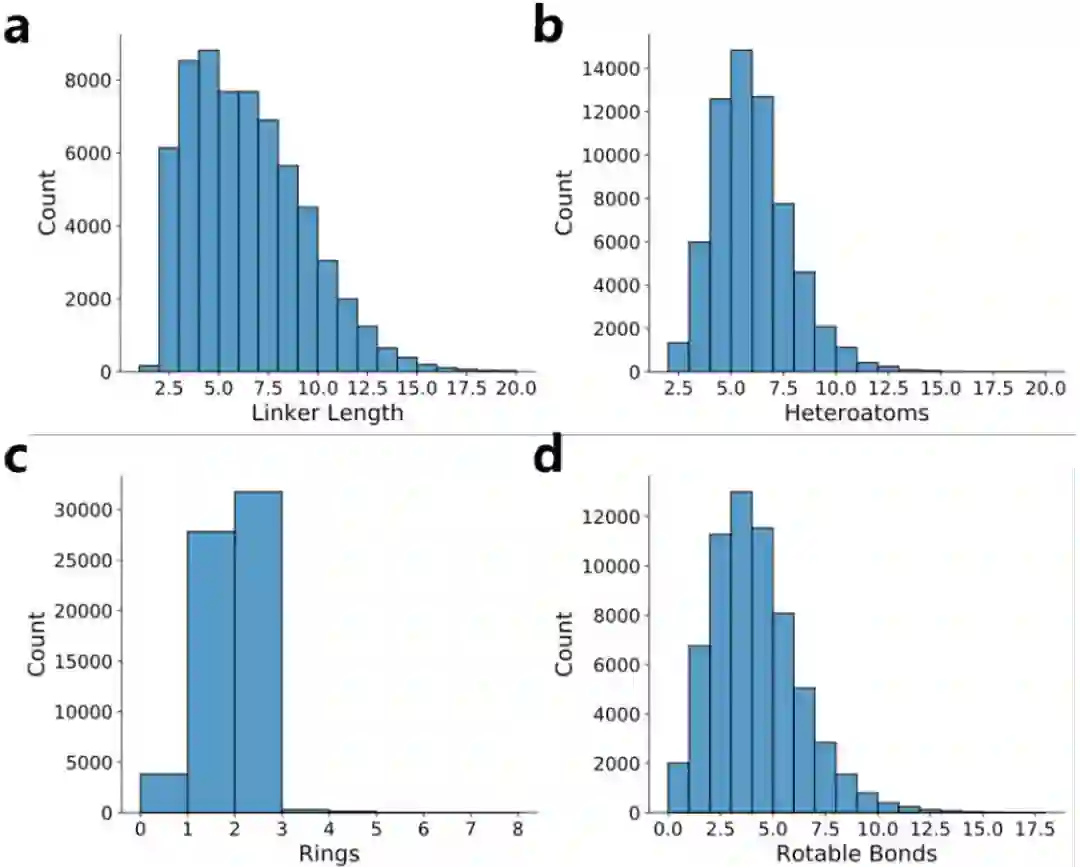
图1 (a) 片段化和学习过程的流程图。 (b) DRlinker的训练过程。图1 (a) 的过程可以描述为以下7步:1. 数据:数据来源于ChEMBL数据库。2. 过滤:根据RO5(Lipinski’s “Rule of Five", 类药物五原则)、PAINS(pan assay interference compounds substructures, 泛分析干扰化合物亚结构)、SA分数(synthetic accessibility score, 合成可及性分数,阈值设为6.5)等原则过滤数据,以保证生成的分子是类似于先导化合物且可以合成的。3. 构建FMQ:作者采用分子对匹配切割算法[the matched molecular pairs (MMPs) cutting algorithm]构建fragment molecule quadruple (FMQ),得到”片段1,连接子,片段2“这样的数据,最后得到5873503个FMQs.4. 进一步过滤:使用“三原则”(“Rule of Three”, RO3)、最短连接子键距离(the shortest linker bond distance, SLBD,小于15)等约束条件以及片段和连接子的SA分数(片段的SA分数小于5,连接子的SA分数小于片段的总和)来过滤FMQ。最终,只有718652对末端片段和起始分子被保留为片段-分子三元组(fragment molecule triplet, FMT)用于模型学习。5. 最终得到包括63846个平均上具有5.96个连接长度原子、1.45个环、3.68个可旋转键和平均5.52个杂原子的唯一连接子(详细直方图如图S1所示)。所有这些化合物都使用canonical SMILES (标准SMILES)格式表示。与模型SyntaLinker和DeLinker类似,作者没有考虑SMILES中的立体异构体和互变异构体,因为这些信息可以由公共晶体结构提供或通过对接预处理确定。6. 训练Prior模型。7. 训练强化学习模型。
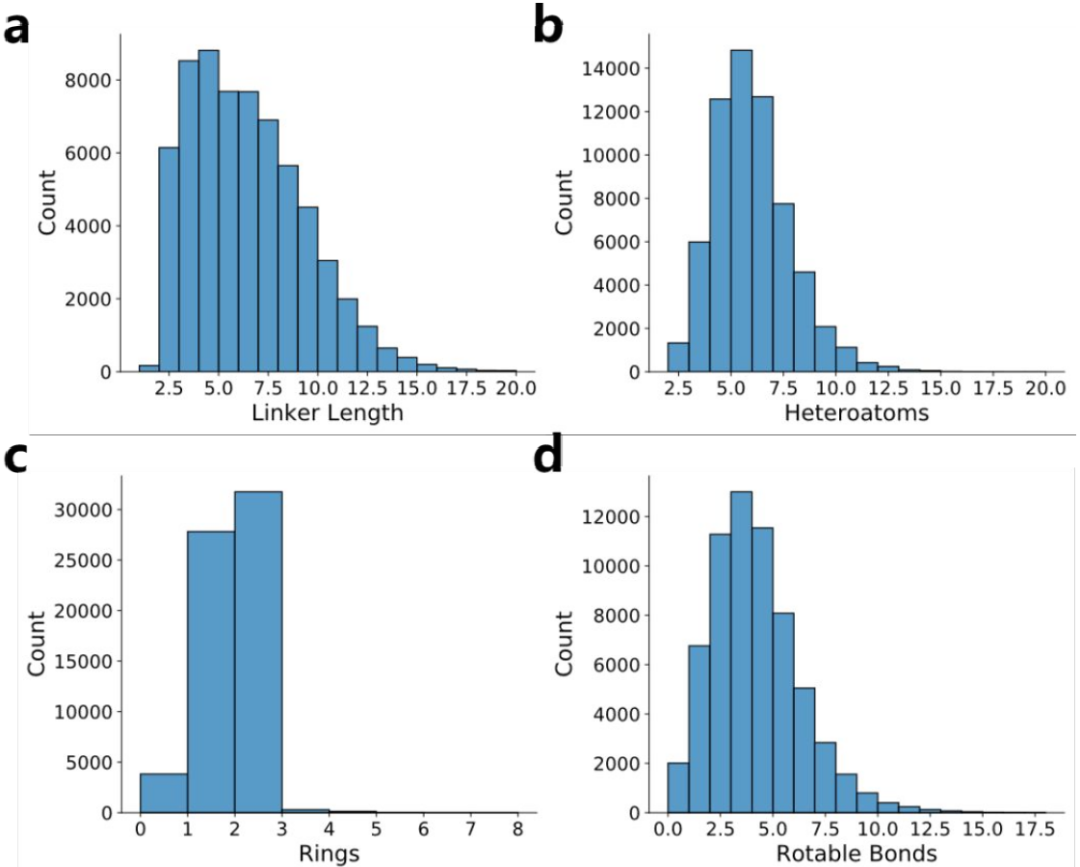
图S1 ChEMBL数据集中连接子的拓扑结构和物理化学直方图图1 (b) 的过程可以描述为以下4步:1. 在ChEMBL数据集上训练模型,并生成Prior模型。2. Agent由Prior网络参数初始化,并通过Beam search或多项式采样采样K个样本。3. 通过不同的打分函数对采样的生成样本进行评分,并将评分与增强的似然相整合以更新Agent参数。 4. 通过数百或数千个训练,Agent就可以将片段与所需属性关联起来。 2.1 Transformer框架
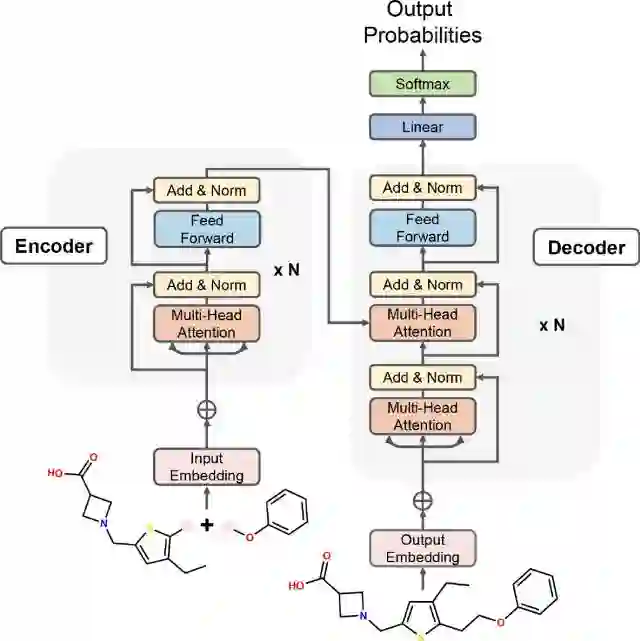
DRlinker的基础框架是一个典型的Transformer神经网络,所用架构与“Attention is all you need“论文中所用的架构类似,框架图如图2所示。
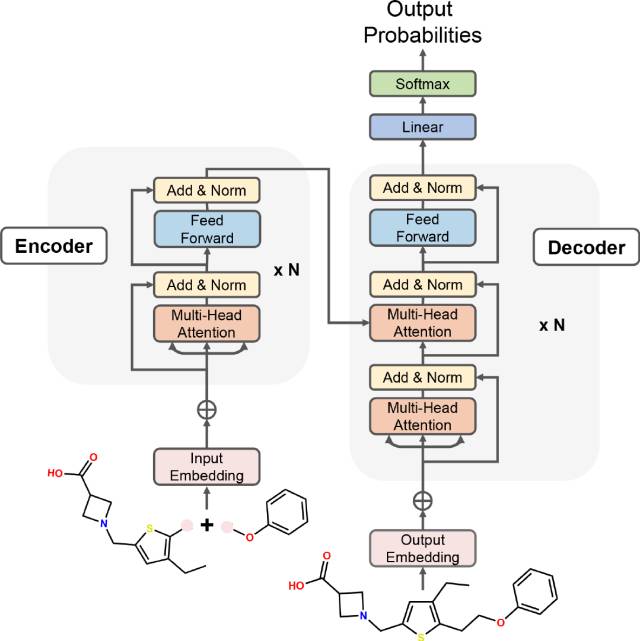
图2 DRlinker的Transformer框架用于片段连接优化。 2.2 强化学习
2.1节中,模型通过Transformer生成了具有特定期望性质的分子的SMILES表示。生成过程可以被视为马尔可夫决策过程,其中,在给定当前状态的情况下,Agent必须决定选择下一个生成的SMILES字符。作者采用先前描述的Prior模型学习的概率分布用作初始Agent策略。然后根据连接子长度、等不同指标采取不同的打分函数。 3 结果
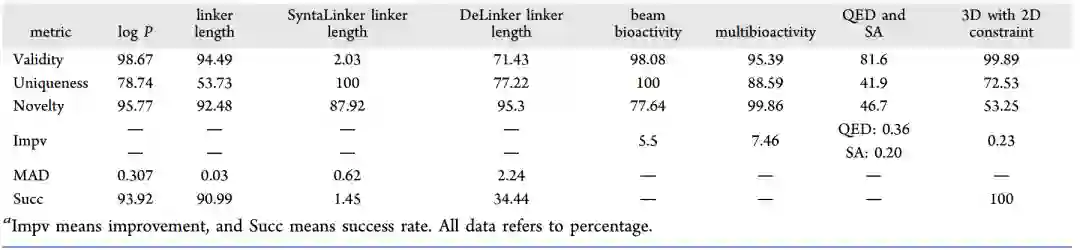
作者在论文中进行了详细的实验和分析。 表1汇总了8个任务上Validity、Novelty、Uniqueness、Recovery、Improvement、Success等6个指标上的结果。 表1 8个任务上模型的表现汇总
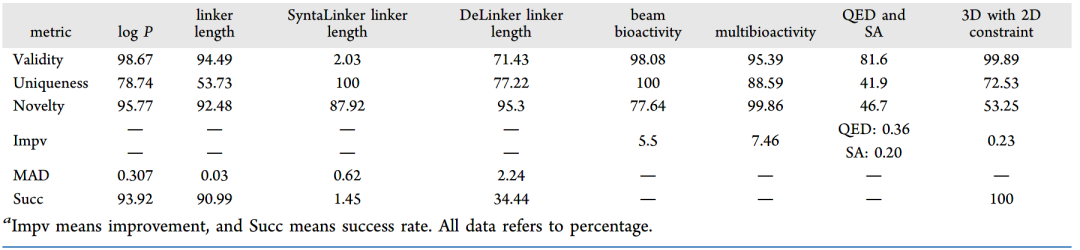
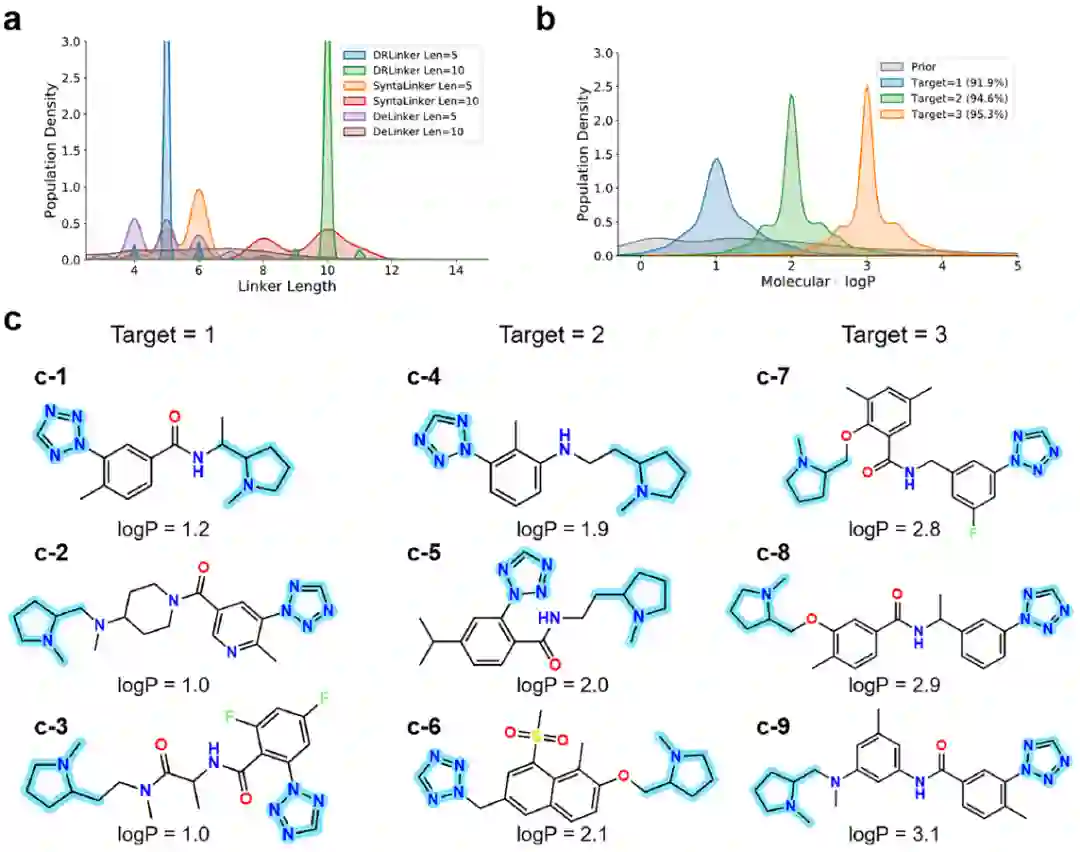
图3展示了模型连接子长度和LogP任务上的结果。
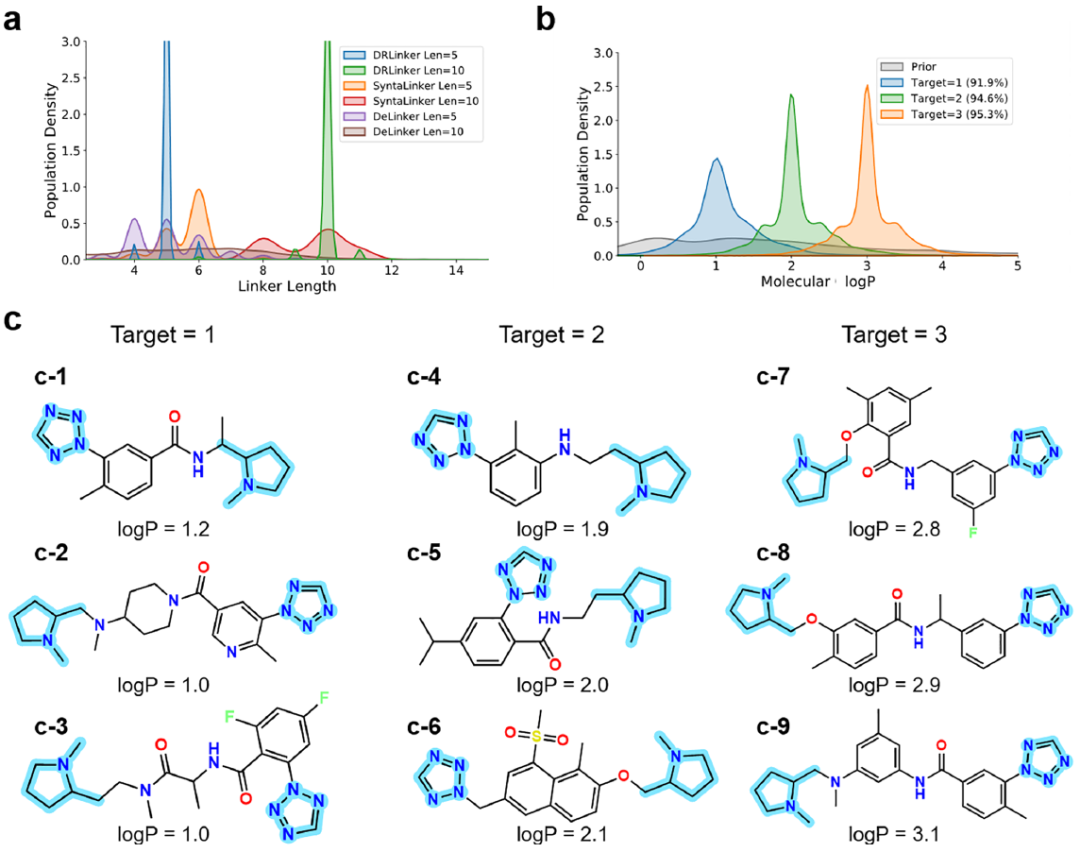
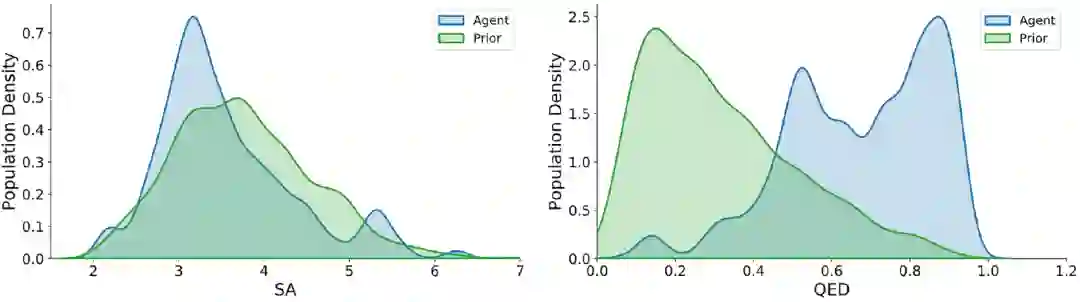
图3 连接子长度和LogP的结果。(a)不同模型在连接子长度任务中针对不同靶标生成样本的分布。(b)不同模型在LogP任务中针对不同靶标生成样本的分布。括号中的百分比表示成功率。(c)在优化LogP任务时使用相同终端片段生成的示例。突出显示的部分是输入片段。图4展示了模型在多目标任务中优化QED和SA指标的连接化合物的分布。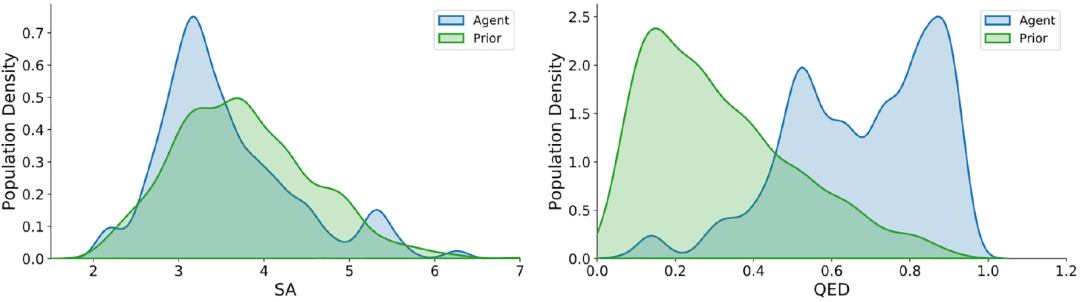
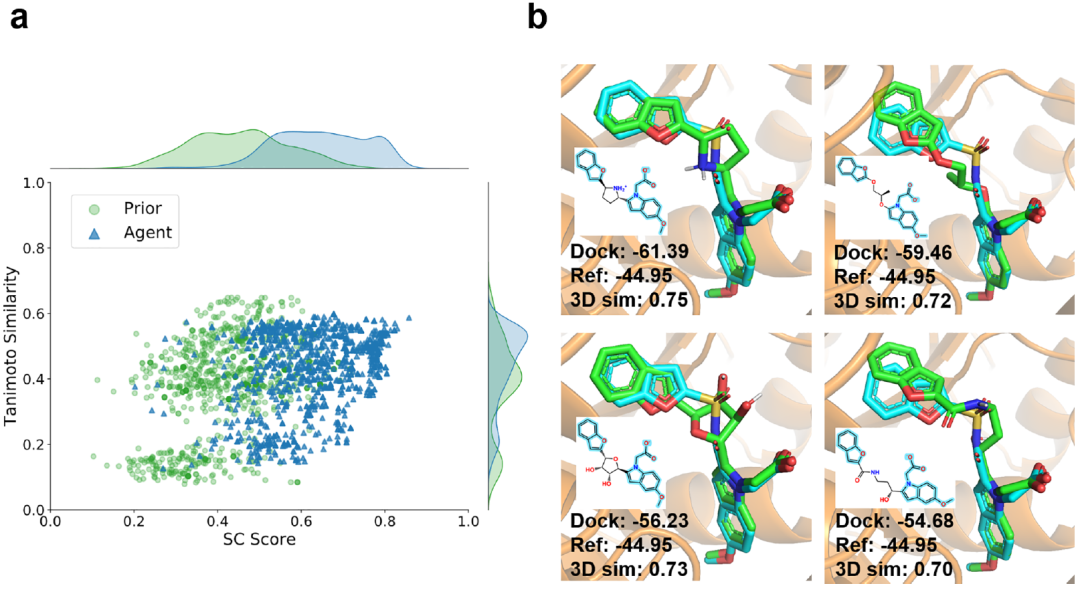
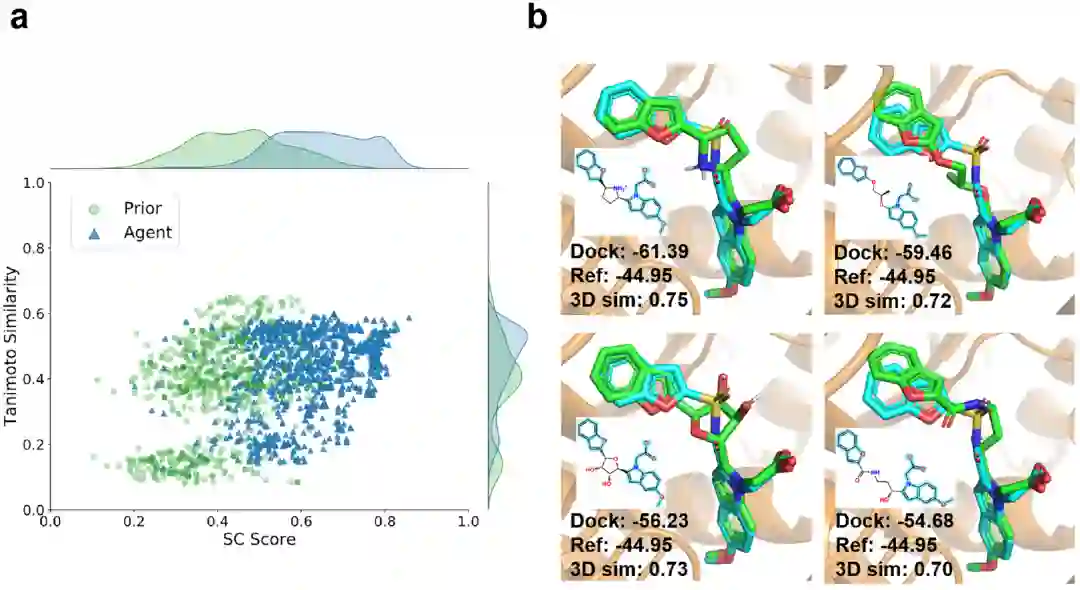
图5 在低2D相似度(Tanimoto similarity < 0.6)的约束下优化3D相似度(SC评分)的性能:(a)连接化合物的2D和3D相似度,(b)Pts靶标的排名前4的候选化合物的结合模式和MM/GBSA结合自由能,以及与先导化合物FG6 (Ref)的比较。化合物FG6是着青色,而候选化合物着绿色。 4 总结与讨论
在本研究中,作者通过结合Transformer和深度强化学习,开发了用于片段连接子优化的DRlinker。该模型可以通过在给定的评分函数上使用强化学习来生成具有期望性质的化合物。该方案减轻了设计和重新训练具有新特征的大型数据集的需要。它也比必须过滤生成的序列或图的SyntaLinker和DeLinker模型更有效。 作者对一些任务进行了全面测试。结果表明,本论文方法不仅能够生成具有单一目标的分子,例如特定的或更好的预测的生物活性,而且能够生成具有多目标的分子(例如更好的QED和合成可及性)。最后,在骨架跳跃实验的例子中,证明了本方法可以生成与参考结构具有良好3D相似度和较低2D相似度的结构。本生成模型可以在强化学习指导下突破学习空间。t-SNE投影实验(图S8)表明,DRlinker不仅可以覆盖训练集的空间,还可以从学习空间中生成许多真正新颖的连接子。
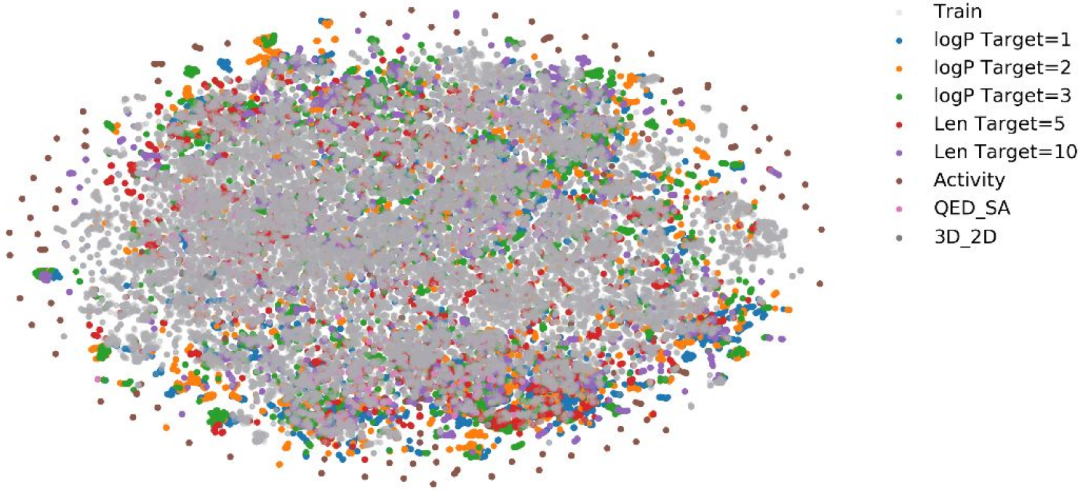
图S8 训练连接子和生成的连接子的t-SNE图,在所有强化学习任务中使用默认设置。虽然该方法被证明是有效的,但这项研究仍有几个局限性。
- 该方法需要一个预定义的评分函数,该函数并不总是可用或不够准确。例如,针对给定靶蛋白的药物设计需要蛋白质-化合物相互作用的精确评分函数,这是已知的瓶颈。这可以通过一种数据驱动的方法部分解决,该方法不断增加蛋白质-化合物相互作用的数据。2. 有趣的是,在任务中,作者选择了一些较长的连接子化合物,其为,增加了长度小于等于3的限制。如图S3所示,这些生成的样本满足长度限制,其接近1,但连接子在侧链中仍有许多亲水基团。这表明DRlinker通过在主链或侧链中添加亲水基团来优化生成。优化这个问题可能是未来工作的方向。3. 评分函数可能是计算密集型的,并将限制本方法的采样效率。例如,在quasi-scaffold-hopping实验中,通过RDKit计算3D相似度分数的低吞吐量几乎需要一秒钟来评估两个分子之间的相似度,并且一次迭代训练(2000步)需要大约35小时来生成64个化合物。解决这一问题的一种方法是将GPU的混合计算与分布式CPU计算相结合,特别是在现代超级计算机的帮助下进行。

图S3 限制连接子长度优化LogP的生成示例。突出显示的部分是输入片段。 总之,DRlinker为基于片段的药物设计提供了一种灵活且用户友好的方法。用户只需定义一个评分函数,该方法将自动对具有所需属性评分的化合物进行采样。 参考资料 Tan Y, Dai L, Huang W, et al. DRlinker: Deep Reinforcement Learning for Optimization in Fragment Linking Design[J]. Journal of Chemical Information and Modeling, 2022.
--------- End ---------