

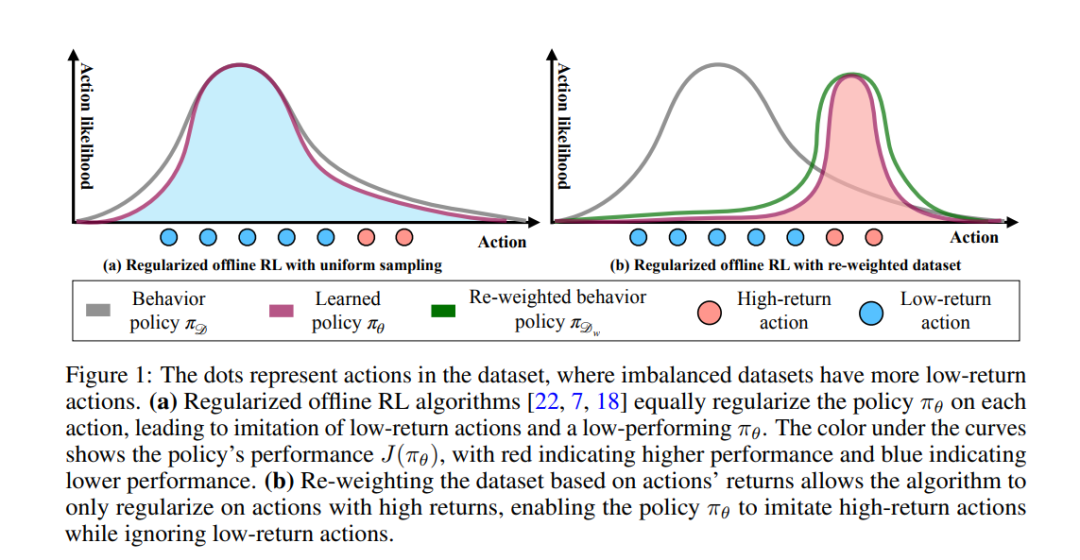
离线策略学习旨在使用现有的轨迹数据集来学习决策策略,而无需收集额外的数据。使用强化学习(RL)而不是监督学习技术(如行为克隆)的主要动机是找到一个策略,该策略的平均回报高于构成数据集的轨迹。然而,我们经验性地发现,当一个数据集被次优轨迹所支配时,最先进的离线RL算法并没有在数据集中的轨迹平均回报上获得实质性的改进。我们认为这是因为当前的离线RL算法假设要接近数据集中的轨迹。如果数据集主要由次优轨迹组成,这个假设会迫使策略模仿次优动作。我们通过提出一个采样策略来克服这个问题,该策略使策略只受到"好数据"的约束,而不是数据集中的所有动作(即均匀采样)。我们呈现了采样策略的实现和一个算法,该算法可以用作标准离线RL算法中的即插即用模块。我们的评估在72个不平衡数据集、D4RL数据集和三种不同的离线RL算法中显示出显著的性能提升。代码可在https://github.com/Improbable-AI/dw-offline-rl 获取。
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2023年11月22日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
218+阅读 · 2023年4月7日
Arxiv
148+阅读 · 2023年3月29日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年11月22日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
218+阅读 · 2023年4月7日
Arxiv
148+阅读 · 2023年3月29日