
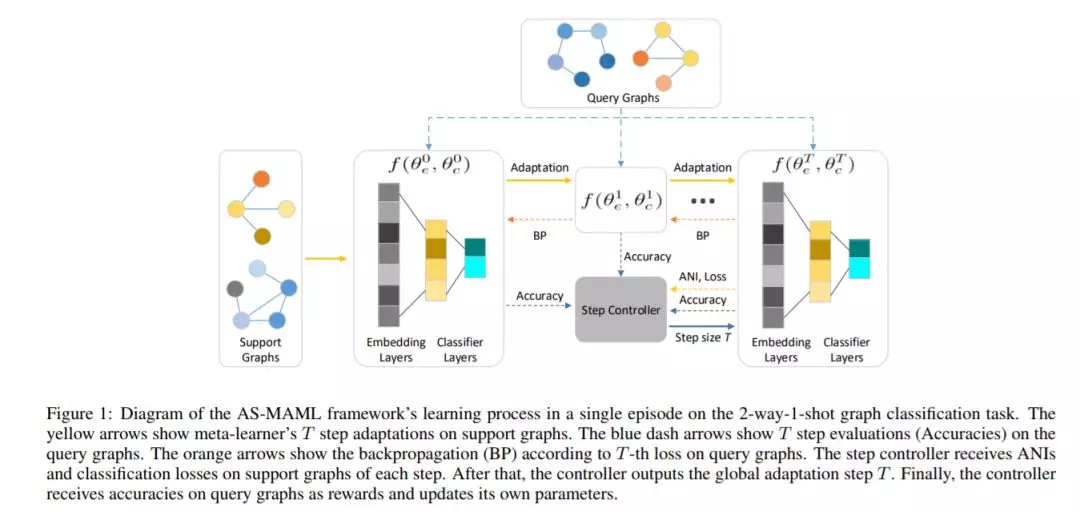
图分类的目的是对图结构数据进行准确的信息提取和分类。在过去的几年里,图神经网络(GNNs)在图分类任务上取得了令人满意的成绩。然而,大多数基于GNNs的方法侧重于设计图卷积操作和图池操作,忽略了收集或标记图结构数据比基于网格的数据更困难。我们利用元学习来进行小样本图分类,以减少训练新任务时标记图样本的不足。更具体地说,为了促进图分类任务的学习,我们利用GNNs作为图嵌入主干,利用元学习作为训练范式,在图分类任务中快速捕获特定任务的知识并将其转移到新的任务中。为了提高元学习器的鲁棒性,我们设计了一种新的基于强化学习的步进控制器。实验表明,与基线相比,我们的框架运行良好。
成为VIP会员查看完整内容
相关内容

Arxiv
20+阅读 · 2019年10月25日


相关VIP内容
相关资讯
相关论文
Arxiv
20+阅读 · 2019年10月25日